Self-controller: Controlling LLMs with Multi-round Step-by-step Self-awareness
作者: Xiao Peng, Xufan Geng
分类: cs.CL, cs.AI
发布日期: 2024-10-01
备注: 10 pages, 6 figures
💡 一句话要点
提出Self-controller框架,通过多轮自感知控制LLM生成文本长度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 可控生成 自感知 链式思考 文本长度控制
📋 核心要点
- 现有LLM的可控性有限,尤其是在生成文本的长度等属性上,缺乏有效的控制手段。
- Self-controller通过维护LLM响应的状态,使其具备自感知能力,从而实现对生成过程的精细控制。
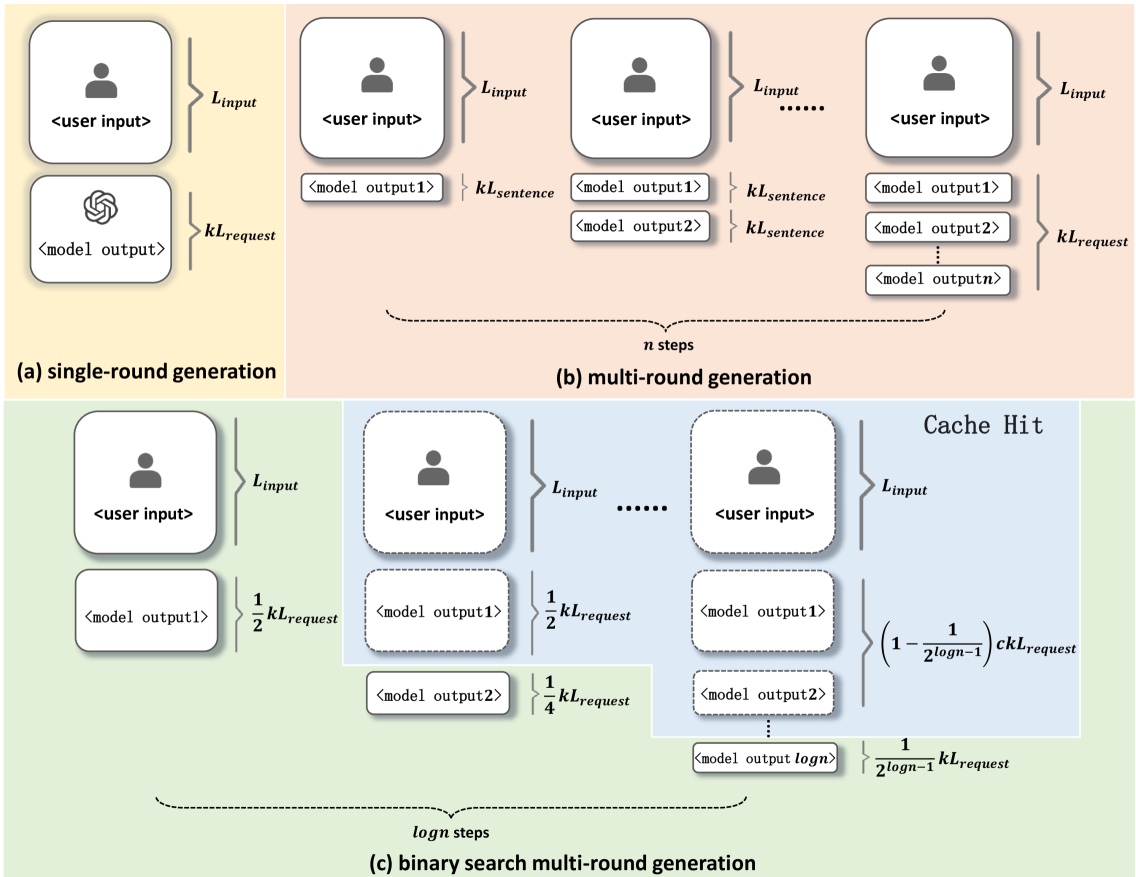
- 实验证明Self-controller在控制文本长度方面有效,并利用二分搜索加速生成,同时降低token消耗。
📝 摘要(中文)
大型语言模型(LLMs)的应用已广泛普及于各个领域。然而,LLMs的基本能力,如可控性,仍然受到限制。为了解决这个问题,我们提出了“Self-controller”,一种新颖的代理框架,将自感知引入LLMs的推理逻辑。这项工作的核心思想是基于LLM的响应维护状态,使LLM能够自感知当前状态,并在多轮思维链范式中逐步思考。我们在文本长度状态上的实验表明了Self-controller的可控性和有效性。我们进一步实现了一种二分搜索算法,以基于文本长度状态的线性和单调性来加速生成过程。Self-controller的另一个优势来自于DeepSeek的上下文缓存技术,当一组对话共享相同的上下文前缀时,该技术可以显著节省计算token消耗。理论上,我们证明在这种情况下,额外的时间复杂度为O(c log n)。粗略估计的结果表明,我们方法的token消耗不超过简单单轮生成的两倍。此外,我们对单词约束的消融研究表明,Self-controller在所有基础模型中都具有一致的可控性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)生成文本的可控性问题,特别是对生成文本长度的精确控制。现有方法通常难以实现对生成文本长度的有效约束,导致生成结果与预期不符。
核心思路:Self-controller的核心思路是赋予LLM“自感知”能力,使其能够根据自身生成的内容和当前状态进行迭代调整。通过维护一个状态变量(例如文本长度),LLM可以逐步逼近目标状态,实现对生成过程的精确控制。这种多轮迭代的自感知过程类似于人类的思考方式,有助于提高LLM的控制能力。
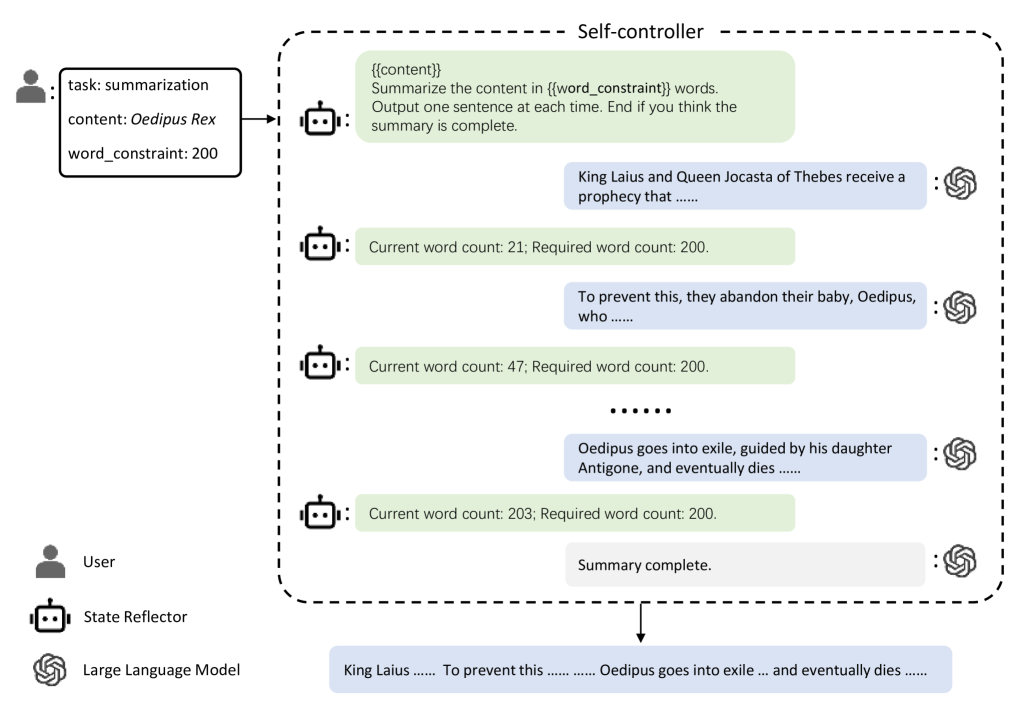
技术框架:Self-controller框架包含以下主要模块:1) 状态维护模块:负责跟踪和更新LLM的当前状态(例如已生成文本的长度)。2) 自感知模块:LLM根据当前状态和目标状态,判断是否需要进行调整。3) 生成模块:LLM根据自感知模块的反馈,生成新的文本片段。4) 迭代控制模块:控制整个迭代过程,直到达到目标状态或满足停止条件。该框架采用多轮链式思考(Chain-of-Thought)范式,使LLM能够逐步推理和生成。
关键创新:Self-controller的关键创新在于将自感知机制引入LLM的推理过程。与传统的单轮生成方法不同,Self-controller允许LLM在生成过程中不断反思和调整,从而提高生成结果的质量和可控性。此外,论文还利用DeepSeek的上下文缓存技术,进一步降低了计算成本。
关键设计:论文采用二分搜索算法来加速文本长度的控制过程。该算法基于文本长度与生成轮数之间的单调关系,通过不断调整生成长度,快速逼近目标长度。此外,论文还设计了相应的提示词(Prompt)和停止条件,以确保LLM能够有效地进行自感知和迭代。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Self-controller能够有效地控制LLM生成文本的长度,并且在不同的基础模型上都具有一致的可控性。通过二分搜索算法,生成速度得到显著提升。此外,DeepSeek的上下文缓存技术有效降低了token消耗,使得Self-controller在实际应用中更具优势。粗略估计表明,该方法的token消耗不超过简单单轮生成的两倍。
🎯 应用场景
Self-controller具有广泛的应用前景,例如:1) 文本摘要:控制摘要的长度,满足不同场景的需求。2) 机器翻译:控制翻译结果的长度和风格。3) 内容创作:辅助生成符合特定要求的文章、故事等。该研究有助于提高LLM在各种实际应用中的可用性和可靠性,并促进人机协作。
📄 摘要(原文)
The applications of large language models (LLMs) have been widely spread across all domains. However, the basic abilities such as the controllability of LLMs are still limited. To address this, we propose "Self-controller", a novel agentic framework bringing self-awareness into LLMs' reasoning logic. The core idea of this work is to maintain states based on the LLM's response, letting the LLM become self-aware of current status and think step by step in a multi-round chain-of-thought paradigm. Our experiment on the state of textual length has shown the controllability and effectiveness of the Self-controller. We further implement a binary search algorithm to accelerate the generation process based on the linearity and monotonicity of the textual length state. Another advantage of the Self-controller comes with DeepSeek's Context Caching technology, which significantly saves computational token consumption when a cluster of conversations shares the same prefix of context. Theoretically, we prove that in this scenario the extra time complexity is $O(c \log n)$. Results of the back-of-the-envelope estimation suggest that the token consumption of our method is no more than twice as much as that of the trivial single-round generation. Furthermore, our ablation study on word constraints demonstrates the Self-controller's consistent controllability across all foundation models.