Neurosymbolic AI approach to Attribution in Large Language Models
作者: Deepa Tilwani, Revathy Venkataramanan, Amit P. Sheth
分类: cs.CL
发布日期: 2024-09-30
备注: Six pages, three figures, Paper under review
💡 一句话要点
提出神经符号AI方法,提升大语言模型归因的可靠性和可解释性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 归因 神经符号AI 知识图谱 可解释性
📋 核心要点
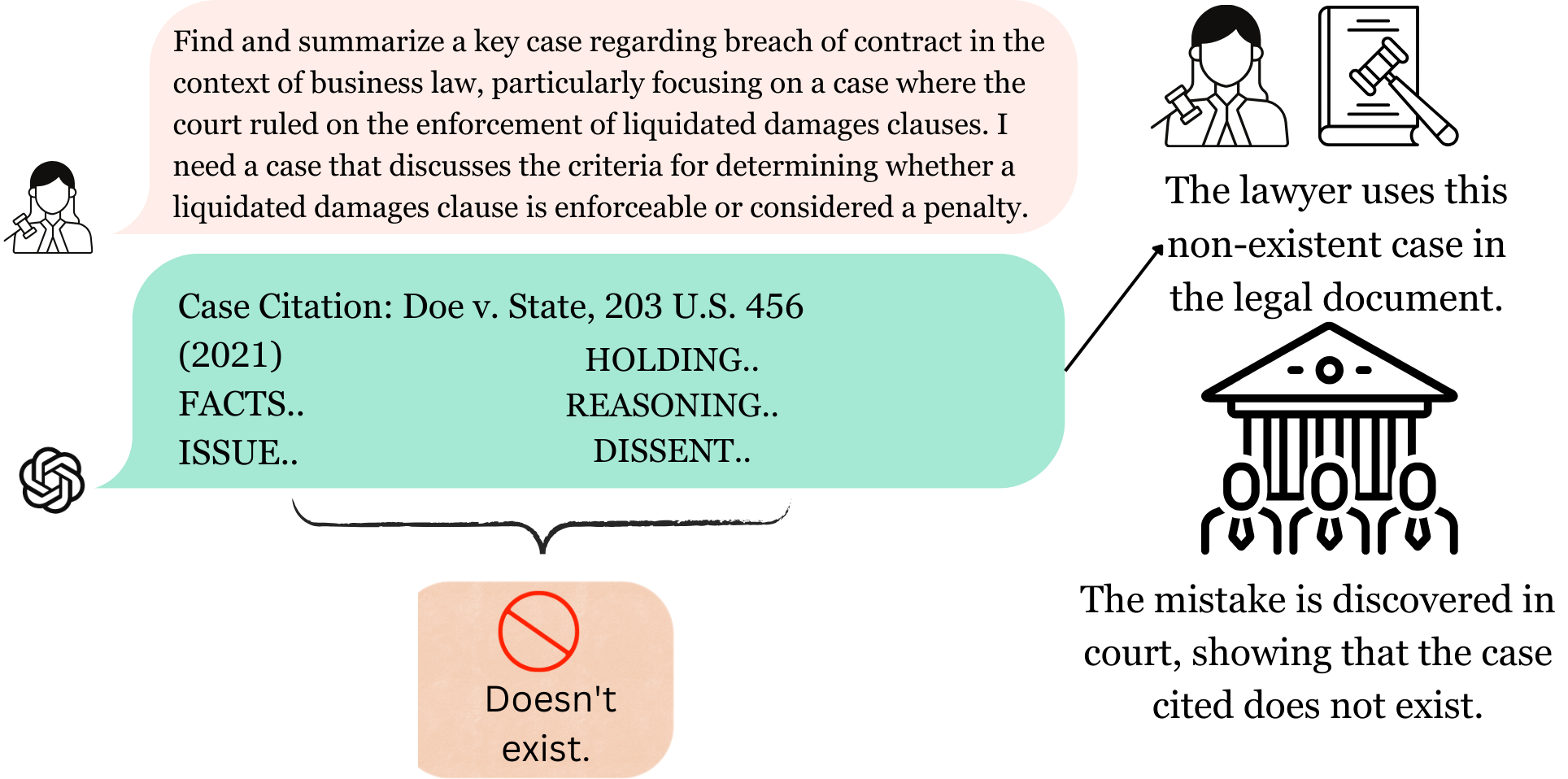
- 现有大语言模型归因方法依赖实时搜索和引用,但易受幻觉、偏差和不可靠信息源的影响。
- 论文提出利用神经符号AI (NesyAI) 结合神经网络和符号推理,提升归因的透明性和可靠性。
- NesyAI框架通过结构化知识和神经学习,旨在构建更可靠、可解释和适应性强的LLM归因系统。
📝 摘要(中文)
大语言模型(LLM)的归因仍然是一个重大挑战,尤其是在确保生成输出的事实准确性和可靠性方面。现有的引用或归因方法,例如Perplexity.ai和集成Bing搜索的LLM所采用的方法,试图通过提供实时搜索结果和引用来支持回答。然而,这些方法存在幻觉、偏差、表面相关性匹配以及管理庞大且未经过滤的知识源的复杂性等问题。虽然像Perplexity.ai这样的工具动态地整合了基于网络的信息和引用,但它们经常依赖于不一致的来源,例如博客文章或不可靠的来源,这限制了它们的整体可靠性。本文提出,通过整合神经符号AI (NesyAI) 可以缓解这些挑战,NesyAI结合了神经网络的优势与结构化符号推理。NesyAI提供透明、可解释和动态的推理过程,通过将结构化符号知识与灵活的、基于神经的学习相结合,解决了当前归因方法的局限性。本文探讨了NesyAI框架如何增强现有的归因模型,为LLM提供更可靠、可解释和适应性强的系统。
🔬 方法详解
问题定义:当前大语言模型在归因方面面临挑战,主要体现在生成内容的事实准确性和可靠性难以保证。现有方法,如依赖实时搜索结果和引用的系统,容易受到幻觉、偏差以及对表面相关性的过度依赖的影响。此外,管理和筛选海量、未过滤的知识来源也带来了巨大的复杂性。这些问题导致LLM在提供信息时,可能引用不准确或不可靠的来源,从而降低了用户信任度。
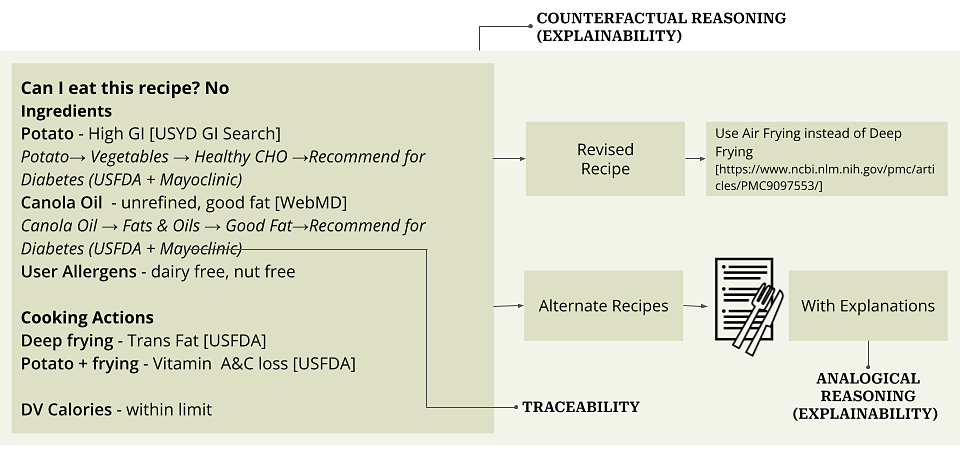
核心思路:论文的核心思路是利用神经符号AI (NesyAI) 的优势,将神经网络的灵活性和符号推理的结构化知识相结合。通过这种结合,NesyAI旨在克服传统神经网络在可解释性和可靠性方面的局限性,同时利用神经网络强大的学习能力。NesyAI能够进行透明、可解释和动态的推理过程,从而提高LLM归因的准确性和可靠性。
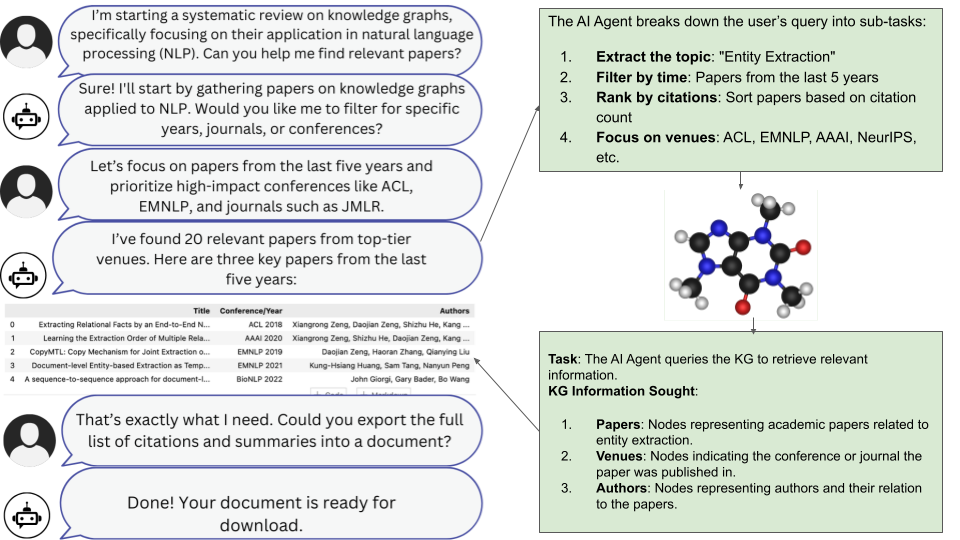
技术框架:论文提出的技术框架涉及将神经符号AI模块集成到现有的LLM归因流程中。具体而言,该框架可能包含以下几个主要模块:1) 知识表示模块:用于将结构化知识表示为符号形式,例如知识图谱或逻辑规则。2) 神经推理模块:利用神经网络学习知识表示上的推理规则,从而进行动态的知识推理。3) 归因生成模块:基于神经推理的结果,生成包含可靠引用的归因信息。整个流程旨在实现从非结构化文本到结构化知识,再到可解释归因的转换。
关键创新:论文最重要的技术创新点在于将神经符号AI应用于大语言模型的归因问题。与传统的纯神经网络方法相比,NesyAI能够提供更透明、可解释的推理过程,从而更容易识别和纠正错误。此外,NesyAI还可以利用结构化知识来约束LLM的生成过程,从而减少幻觉和偏差。这种结合使得LLM能够生成更可靠、更准确的归因信息。
关键设计:具体的参数设置、损失函数和网络结构等技术细节在论文中可能没有详细描述,因为NesyAI本身是一个广泛的领域,可以采用多种不同的实现方式。然而,一些关键的设计考虑可能包括:1) 如何有效地将知识图谱或逻辑规则嵌入到神经网络中。2) 如何设计损失函数,以鼓励神经网络学习正确的推理规则。3) 如何平衡神经网络的灵活性和符号推理的约束性。这些设计选择将直接影响NesyAI在LLM归因任务中的性能。
🖼️ 关键图片
📊 实验亮点
由于是方法论论文,没有具体的实验结果。亮点在于提出了神经符号AI解决LLM归因问题的思路,并分析了其潜在优势。未来的工作可以围绕如何具体实现NesyAI框架,并验证其在实际LLM归因任务中的性能提升展开。例如,可以对比NesyAI与现有归因方法在生成引用的准确性、可靠性和可解释性方面的差异。
🎯 应用场景
该研究成果可广泛应用于需要高可靠性和可解释性的LLM应用场景,例如:智能问答系统、自动报告生成、科学研究辅助等。通过提升LLM归因的准确性,可以增强用户对LLM生成内容的信任度,并减少错误信息的传播。未来,该技术有望推动LLM在更多关键领域的应用,例如医疗诊断、金融分析等。
📄 摘要(原文)
Attribution in large language models (LLMs) remains a significant challenge, particularly in ensuring the factual accuracy and reliability of the generated outputs. Current methods for citation or attribution, such as those employed by tools like Perplexity.ai and Bing Search-integrated LLMs, attempt to ground responses by providing real-time search results and citations. However, so far, these approaches suffer from issues such as hallucinations, biases, surface-level relevance matching, and the complexity of managing vast, unfiltered knowledge sources. While tools like Perplexity.ai dynamically integrate web-based information and citations, they often rely on inconsistent sources such as blog posts or unreliable sources, which limits their overall reliability. We present that these challenges can be mitigated by integrating Neurosymbolic AI (NesyAI), which combines the strengths of neural networks with structured symbolic reasoning. NesyAI offers transparent, interpretable, and dynamic reasoning processes, addressing the limitations of current attribution methods by incorporating structured symbolic knowledge with flexible, neural-based learning. This paper explores how NesyAI frameworks can enhance existing attribution models, offering more reliable, interpretable, and adaptable systems for LLMs.