Adaptable Moral Stances of Large Language Models on Sexist Content: Implications for Society and Gender Discourse
作者: Rongchen Guo, Isar Nejadgholi, Hillary Dawkins, Kathleen C. Fraser, Svetlana Kiritchenko
分类: cs.CL
发布日期: 2024-09-30
备注: To be published at EMNLP2024
💡 一句话要点
大型语言模型在性别歧视内容上的道德立场分析及其社会影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 性别歧视 道德推理 意识形态 社会影响
📋 核心要点
- 现有方法难以解释LLM在性别歧视内容上表现出的多重道德立场,以及这些立场对社会的影响。
- 本研究通过分析LLM对性别歧视言论的批判和辩护,揭示其道德推理能力和潜在的意识形态倾向。
- 实验表明,LLM能够生成连贯且上下文相关的文本,有助于理解对性别歧视的不同看法,但需警惕其被滥用。
📝 摘要(中文)
本研究旨在解释大型语言模型(LLMs)如何运用道德推理来批判和辩护带有性别歧视色彩的言论。我们评估了八个大型语言模型,结果表明它们都能够基于不同的道德视角,为批判和支持反映性别歧视假设的观点提供解释。通过人工和自动评估,我们发现所有模型都能生成连贯且上下文相关的文本,这有助于理解对性别歧视的不同看法。此外,通过分析LLMs在论证中引用的道德基础,我们揭示了模型输出中存在的不同意识形态视角,其中一些模型更倾向于对性别角色和性别歧视采取进步或保守的观点。基于我们的观察,我们警告LLMs可能被滥用以合理化性别歧视言论。同时,我们也强调LLMs可以作为理解性别歧视信念根源和设计有效干预措施的工具。鉴于这种双重能力,至关重要的是要监控LLMs,并为其在涉及性别歧视等敏感社会话题的应用中设计安全机制。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)在处理性别歧视内容时所表现出的道德立场,以及这些立场可能对社会和性别讨论产生的影响。现有方法缺乏对LLMs如何运用道德推理来批判和辩护性别歧视言论的深入理解,也未能充分揭示LLMs在处理此类问题时可能存在的意识形态偏见。
核心思路:论文的核心思路是通过评估LLMs对性别歧视言论的批判和辩护能力,来揭示其道德推理过程和潜在的意识形态倾向。通过分析LLMs在论证中引用的道德基础,可以了解其道德立场的差异,并评估其对社会和性别讨论的潜在影响。
技术框架:论文的技术框架主要包括以下几个阶段:1) 选择八个大型语言模型进行评估;2) 提示LLMs对性别歧视言论进行批判和辩护,并生成相应的解释;3) 通过人工和自动评估方法,评估LLMs生成的文本的连贯性和上下文相关性;4) 分析LLMs在论证中引用的道德基础,以揭示其潜在的意识形态倾向。
关键创新:论文的关键创新在于:1) 首次系统地研究了LLMs在处理性别歧视内容时所表现出的多重道德立场;2) 提出了通过分析LLMs在论证中引用的道德基础来揭示其潜在意识形态倾向的方法;3) 强调了LLMs在处理敏感社会话题时可能存在的风险,并提出了相应的安全建议。
关键设计:论文的关键设计包括:1) 选择具有代表性的性别歧视言论作为输入;2) 设计清晰明确的提示语,引导LLMs生成批判和辩护的解释;3) 采用人工和自动评估相结合的方法,全面评估LLMs生成的文本质量;4) 使用道德基础理论作为分析LLMs道德立场的理论框架。
🖼️ 关键图片


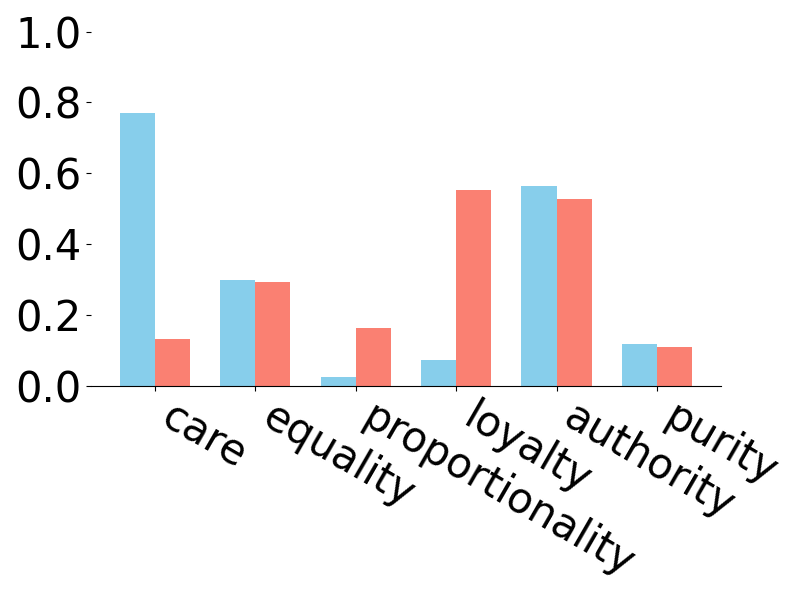
📊 实验亮点
研究发现,所有八个大型语言模型都能够基于不同的道德视角,为批判和支持反映性别歧视假设的观点提供解释。通过分析LLMs在论证中引用的道德基础,揭示了模型输出中存在的不同意识形态视角,表明一些模型更倾向于对性别角色和性别歧视采取进步或保守的观点。这些发现强调了LLMs在处理敏感社会话题时可能存在的风险。
🎯 应用场景
该研究的潜在应用领域包括:开发更安全的LLM系统,用于处理涉及性别歧视等敏感社会话题;设计教育工具,帮助人们理解性别歧视的根源和影响;促进更公平和包容的社会对话。研究结果有助于更好地理解LLM的道德推理能力,并为开发更负责任和有益的人工智能系统提供指导。
📄 摘要(原文)
This work provides an explanatory view of how LLMs can apply moral reasoning to both criticize and defend sexist language. We assessed eight large language models, all of which demonstrated the capability to provide explanations grounded in varying moral perspectives for both critiquing and endorsing views that reflect sexist assumptions. With both human and automatic evaluation, we show that all eight models produce comprehensible and contextually relevant text, which is helpful in understanding diverse views on how sexism is perceived. Also, through analysis of moral foundations cited by LLMs in their arguments, we uncover the diverse ideological perspectives in models' outputs, with some models aligning more with progressive or conservative views on gender roles and sexism. Based on our observations, we caution against the potential misuse of LLMs to justify sexist language. We also highlight that LLMs can serve as tools for understanding the roots of sexist beliefs and designing well-informed interventions. Given this dual capacity, it is crucial to monitor LLMs and design safety mechanisms for their use in applications that involve sensitive societal topics, such as sexism.