Scheherazade: Evaluating Chain-of-Thought Math Reasoning in LLMs with Chain-of-Problems
作者: Stephen Miner, Yoshiki Takashima, Simeng Han, Sam Kouteili, Ferhat Erata, Ruzica Piskac, Scott J Shapiro
分类: cs.CL
发布日期: 2024-09-30 (更新: 2025-02-24)
🔗 代码/项目: GITHUB
💡 一句话要点
Scheherazade:利用问题链自动生成数学推理基准,评估LLM的思维链能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数学推理 基准测试 思维链 自动化生成
📋 核心要点
- 现有数学推理基准(如GSM8K)已无法有效区分先进LLM的推理能力,需要更具挑战性的基准。
- Scheherazade通过前向和后向链接两种方式,自动将简单数学问题串联成复杂的问题链,生成大规模基准。
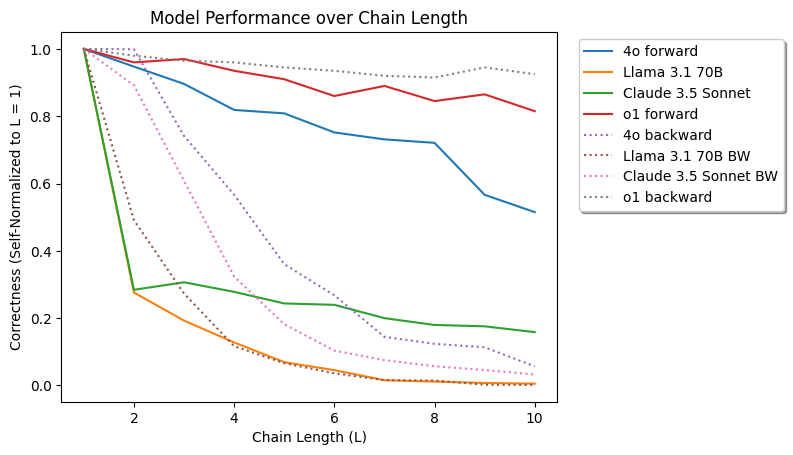
- 实验表明,Scheherazade生成的基准能有效区分不同LLM的推理能力,OpenAI的o1-preview模型表现相对更优。
📝 摘要(中文)
本文提出Scheherazade,一种自动生成具有挑战性的数学推理基准的方法,通过逻辑地链接一个小的起始问题集来产生大量问题。论文提出了两种不同的链接方法:前向链接和后向链接,包括随机分支技术以生成复杂的推理问题。作者将Scheherazade应用于GSM8K数据集,创建了GSM8K-Scheherazade,并评估了3个前沿LLM和OpenAI的o1-preview模型。结果表明,其他前沿模型的性能在链接少量问题后急剧下降,而o1-preview的性能保持稳定,并且OpenAI的旗舰模型在后向推理方面表现更好。数据和代码已公开。
🔬 方法详解
问题定义:论文旨在解决LLM数学推理能力评估中,现有基准难度不足,且人工构建新基准成本高昂的问题。现有方法难以有效区分先进LLM的推理能力,限制了对LLM推理能力的深入研究。
核心思路:论文的核心思路是通过自动化的方式,将简单的数学问题链接成复杂的问题链,从而生成大规模、具有挑战性的数学推理基准。这种方法避免了人工构建基准的成本,并且可以灵活地控制基准的难度。
技术框架:Scheherazade包含两个主要的链接方法:前向链接和后向链接。前向链接从一个起始问题开始,逐步添加新的问题,每个新问题都依赖于前一个问题的答案。后向链接从一个目标问题开始,逐步分解为更简单的子问题,直到达到已知的起始问题。两种方法都包含随机分支技术,以增加问题链的复杂性。整体流程包括:1. 选择起始问题集;2. 选择链接方法(前向或后向);3. 设置链接长度和分支因子;4. 自动生成问题链。
关键创新:该方法最重要的创新点在于自动化生成复杂数学推理基准的能力。与传统的手工构建基准相比,Scheherazade可以高效地生成大规模的基准,并且可以灵活地控制基准的难度。此外,前向和后向链接两种方法提供了不同的问题生成策略,可以更全面地评估LLM的推理能力。
关键设计:关键设计包括:1. 链接长度:控制问题链的长度,影响问题的复杂程度;2. 分支因子:控制每个问题可以链接的后续问题的数量,增加问题链的多样性;3. 问题选择策略:选择哪些问题进行链接,影响问题链的主题和难度;4. 随机化策略:在链接过程中引入随机性,避免生成过于相似的问题链。
🖼️ 关键图片

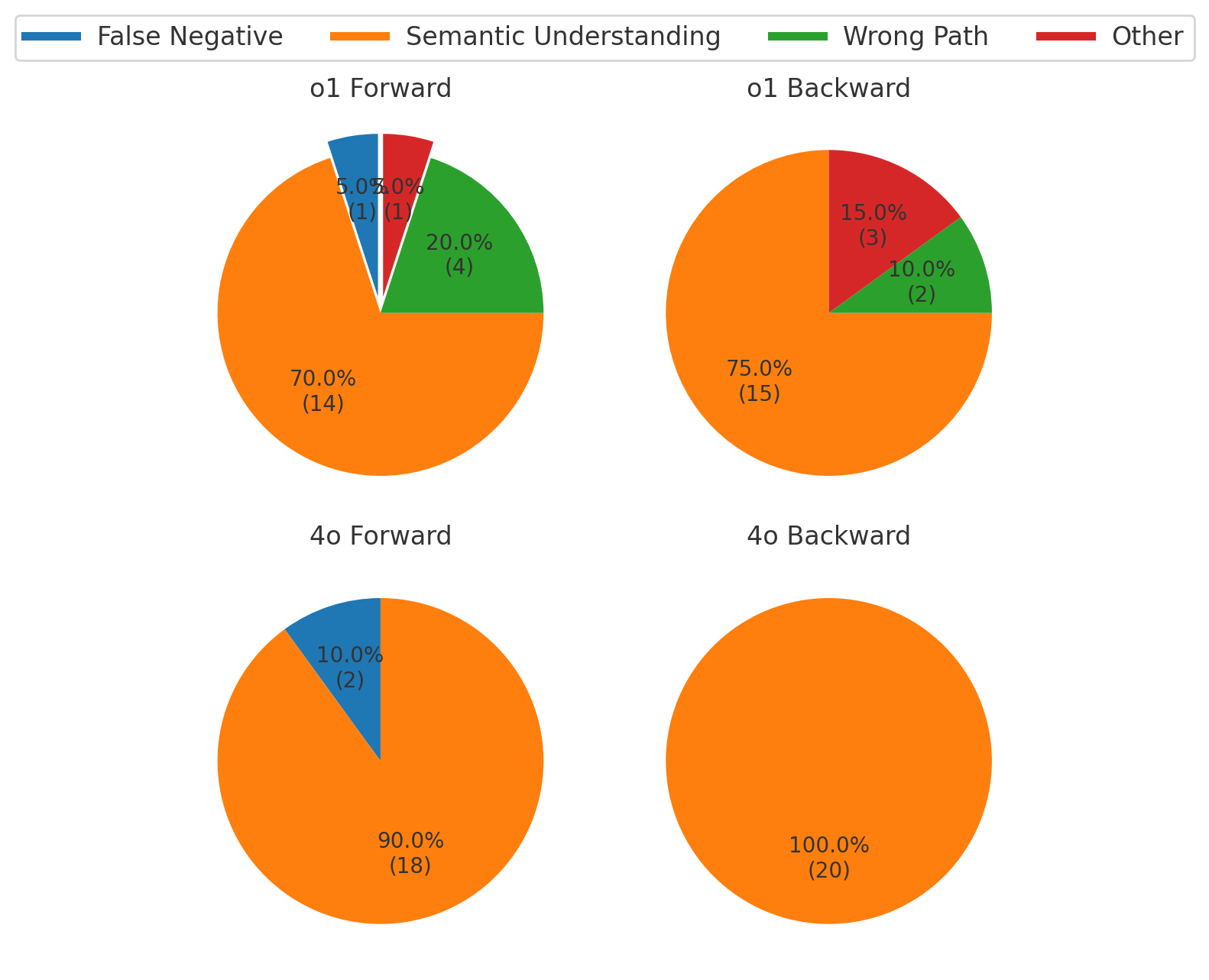
📊 实验亮点
实验结果表明,在GSM8K-Scheherazade基准上,随着问题链长度的增加,其他前沿模型的性能急剧下降,而OpenAI的o1-preview模型表现出更强的鲁棒性。OpenAI的旗舰模型在后向推理方面表现优于其他模型,表明其在问题分解和逆向推理方面具有优势。这些结果表明,Scheherazade能够有效区分不同LLM的推理能力。
🎯 应用场景
Scheherazade可用于更全面、更细致地评估和比较不同LLM的数学推理能力。生成的基准可用于训练LLM,提高其解决复杂数学问题的能力。此外,该方法可以推广到其他推理领域,例如逻辑推理、常识推理等,为LLM的评估和训练提供更有效的工具。
📄 摘要(原文)
Benchmarks are critical for measuring Large Language Model (LLM) reasoning capabilities. Some benchmarks have even become the de facto indicator of such capabilities. However, as LLM reasoning capabilities improve, existing widely-used benchmarks such as GSM8K marginally encapsulate model reasoning differentials - most state-of-the-art models for example achieve over 94% accuracy on the GSM8K dataset (paperwithcode, 2024). While constructing harder benchmarks is possible, their creation is often manual, expensive, and unscalable. As such, we present Scheherazade, an automated approach to produce large quantities of challenging mathematical reasoning benchmarks by logically chaining a small starting set of problems. We propose two different chaining methods, forward chaining and backward chaining, which include randomized branching techniques to generate complex reasoning problems. We apply Scheherazade on GSM8K to create GSM8K-Scheherazade and evaluate 3 frontier LLMs and OpenAI's o1-preview on it. We show that while other frontier models' performance declines precipitously at only a few questions chained, our evaluation suggests o1-preview's performance persists, with the flagship OpenAI model the only one to perform better at backward reasoning. Our data and code are available at https://github.com/YoshikiTakashima/scheherazade-code-data.