Are Large Language Models In-Context Personalized Summarizers? Get an iCOPERNICUS Test Done!
作者: Divya Patel, Pathik Patel, Ankush Chander, Sourish Dasgupta, Tanmoy Chakraborty
分类: cs.CL, cs.LG, cs.NE
发布日期: 2024-09-30
💡 一句话要点
提出iCOPERNICUS框架,用于评估大型语言模型在上下文个性化摘要中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 上下文学习 个性化摘要 用户画像 评估框架
📋 核心要点
- 现有方法缺乏有效评估LLM在上下文个性化摘要中利用用户画像对比信息的能力。
- 提出iCOPERNICUS框架,通过更丰富的提示来考察LLM是否真正理解并利用用户个性化信息。
- 实验结果表明,许多先进LLM在面对更全面的个性化提示时,摘要性能反而下降,揭示了ICPL能力的不足。
📝 摘要(中文)
大型语言模型(LLMs)在基于上下文学习(ICL)的摘要任务中取得了显著成功。然而,显著性受到用户特定偏好历史的影响。因此,我们需要LLMs具备可靠的上下文个性化学习(ICPL)能力。为了使任意LLM展现ICPL,它需要能够辨别用户画像的对比。一项最新研究首次提出了一种名为EGISES的个性化程度度量。EGISES衡量模型对用户画像差异的响应程度。然而,它无法测试模型是否利用了ICPL提示中提供的所有三种类型的线索:(i)示例摘要,(ii)用户的阅读历史,以及(iii)用户画像的对比。为了解决这个问题,我们提出了iCOPERNICUS框架,这是一种新颖的上下文个性化学习能力评估方法,用于考察LLMs的摘要能力,并使用EGISES作为比较指标。作为一个案例研究,我们评估了17个最先进的LLM,基于它们报告的ICL性能,并观察到当使用更丰富的提示进行探测时,15个模型的ICPL性能下降(最小:1.6%;最大:3.6%),从而表明缺乏真正的ICPL。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在上下文学习(ICL)的个性化摘要任务中,是否真正具备利用用户画像信息进行个性化摘要的问题。现有方法,如EGISES,虽然可以衡量模型对用户画像差异的响应程度,但无法全面评估模型是否有效利用了示例摘要、用户阅读历史和用户画像对比这三种关键线索。因此,现有方法无法准确判断LLM是否具备真正的上下文个性化学习(ICPL)能力。
核心思路:论文的核心思路是设计一种更全面的评估框架,即iCOPERNICUS,通过构建包含更丰富信息的提示,来考察LLM是否能够有效利用所有可用的个性化线索。如果LLM具备真正的ICPL能力,那么在提供更全面的个性化信息后,其摘要性能应该得到提升,而不是下降。
技术框架:iCOPERNICUS框架的核心是构建包含三种类型线索的ICPL提示:(1)示例摘要,(2)用户的阅读历史,(3)用户画像的对比。框架使用EGISES作为比较指标,评估LLM在不同提示下的摘要性能。通过比较LLM在简单提示和包含更丰富信息的提示下的EGISES得分,可以判断LLM是否真正具备ICPL能力。如果EGISES得分下降,则表明LLM并没有有效利用新增的个性化信息。
关键创新:iCOPERNICUS框架的关键创新在于其更全面的评估方法,它不仅考虑了用户画像的差异,还考虑了示例摘要和用户阅读历史的影响。通过构建包含更丰富信息的提示,iCOPERNICUS可以更准确地评估LLM是否具备真正的ICPL能力。与仅关注用户画像差异的EGISES相比,iCOPERNICUS能够更全面地考察LLM的个性化摘要能力。
关键设计:iCOPERNICUS框架的关键设计在于提示的构建方式。提示需要包含示例摘要、用户的阅读历史和用户画像的对比信息。用户阅读历史可以通过模拟用户的阅读行为来生成,用户画像的对比信息可以通过选择具有不同偏好的用户来实现。EGISES得分的计算方式与现有方法相同,但需要针对不同提示下的摘要结果进行计算,以便比较LLM在不同提示下的性能。
🖼️ 关键图片

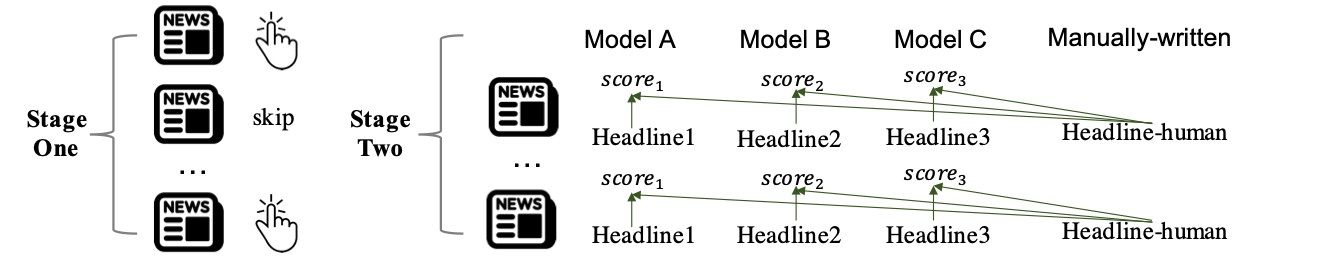
📊 实验亮点
实验结果表明,在17个最先进的LLM中,有15个模型在面对包含更丰富信息的提示时,ICPL性能出现下降(最小:1.6%;最大:3.6%)。这一结果表明,许多先进LLM并没有真正具备利用所有可用个性化线索进行摘要的能力,揭示了当前LLM在ICPL方面的不足。
🎯 应用场景
该研究成果可应用于个性化新闻推荐、个性化产品推荐、个性化教育等领域。通过更准确地评估LLM的个性化摘要能力,可以帮助开发者选择更适合特定应用的LLM,并优化LLM的提示设计,从而提升用户体验和应用效果。未来的研究可以进一步探索如何提升LLM的ICPL能力,使其能够更好地理解和利用用户个性化信息。
📄 摘要(原文)
Large Language Models (LLMs) have succeeded considerably in In-Context-Learning (ICL) based summarization. However, saliency is subject to the users' specific preference histories. Hence, we need reliable In-Context Personalization Learning (ICPL) capabilities within such LLMs. For any arbitrary LLM to exhibit ICPL, it needs to have the ability to discern contrast in user profiles. A recent study proposed a measure for degree-of-personalization called EGISES for the first time. EGISES measures a model's responsiveness to user profile differences. However, it cannot test if a model utilizes all three types of cues provided in ICPL prompts: (i) example summaries, (ii) user's reading histories, and (iii) contrast in user profiles. To address this, we propose the iCOPERNICUS framework, a novel In-COntext PERsonalization learNIng sCrUtiny of Summarization capability in LLMs that uses EGISES as a comparative measure. As a case-study, we evaluate 17 state-of-the-art LLMs based on their reported ICL performances and observe that 15 models' ICPL degrades (min: 1.6%; max: 3.6%) when probed with richer prompts, thereby showing lack of true ICPL.