Enhancing Romanian Offensive Language Detection through Knowledge Distillation, Multi-Task Learning, and Data Augmentation
作者: Vlad-Cristian Matei, Iulian-Marius Tăiatu, Răzvan-Alexandru Smădu, Dumitru-Clementin Cercel
分类: cs.CL
发布日期: 2024-09-30
备注: Accepted by NLDB2024
DOI: 10.1007/978-3-031-70239-6_22
💡 一句话要点
提出知识蒸馏、多任务学习和数据增强方法,提升罗马尼亚语攻击性语言检测性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 多任务学习 数据增强 攻击性语言检测 罗马尼亚语
📋 核心要点
- 现有罗马尼亚语攻击性语言检测模型效率较低,需要更小、更高效的模型。
- 利用知识蒸馏将大型模型的知识迁移到小型模型,并结合多任务学习和数据增强提升性能。
- 实验结果表明,该方法能够有效提升罗马尼亚语攻击性语言检测的性能。
📝 摘要(中文)
本文强调了自然语言处理(NLP)在人工智能领域的重要性,突出了其在理解和建模人类语言方面的关键作用。 近年来,NLP 的进步,特别是在对话机器人方面,受到了开发者的广泛关注和采用。 本文探讨了获得更小、更高效的 NLP 模型的高级方法。 具体来说,我们采用了三种关键方法:(1)训练一个基于 Transformer 的神经网络来检测攻击性语言,(2)采用数据增强和知识蒸馏技术来提高性能,以及(3)结合多任务学习与知识蒸馏和教师退火,使用不同的数据集来提高效率。 这些方法的结合已经产生了显著改进的结果。
🔬 方法详解
问题定义:论文旨在解决罗马尼亚语攻击性语言检测任务中模型效率和性能之间的平衡问题。现有方法可能存在模型体积大、计算成本高的问题,难以在资源受限的环境中部署。此外,数据稀缺也是一个挑战,限制了模型的泛化能力。
核心思路:论文的核心思路是利用知识蒸馏技术,将一个性能较好的“教师”模型的知识迁移到一个更小的“学生”模型中,从而在保证性能的同时降低模型复杂度。同时,结合多任务学习,利用多个相关数据集来提升模型的泛化能力和鲁棒性。数据增强则用于扩充训练数据,缓解数据稀缺问题。
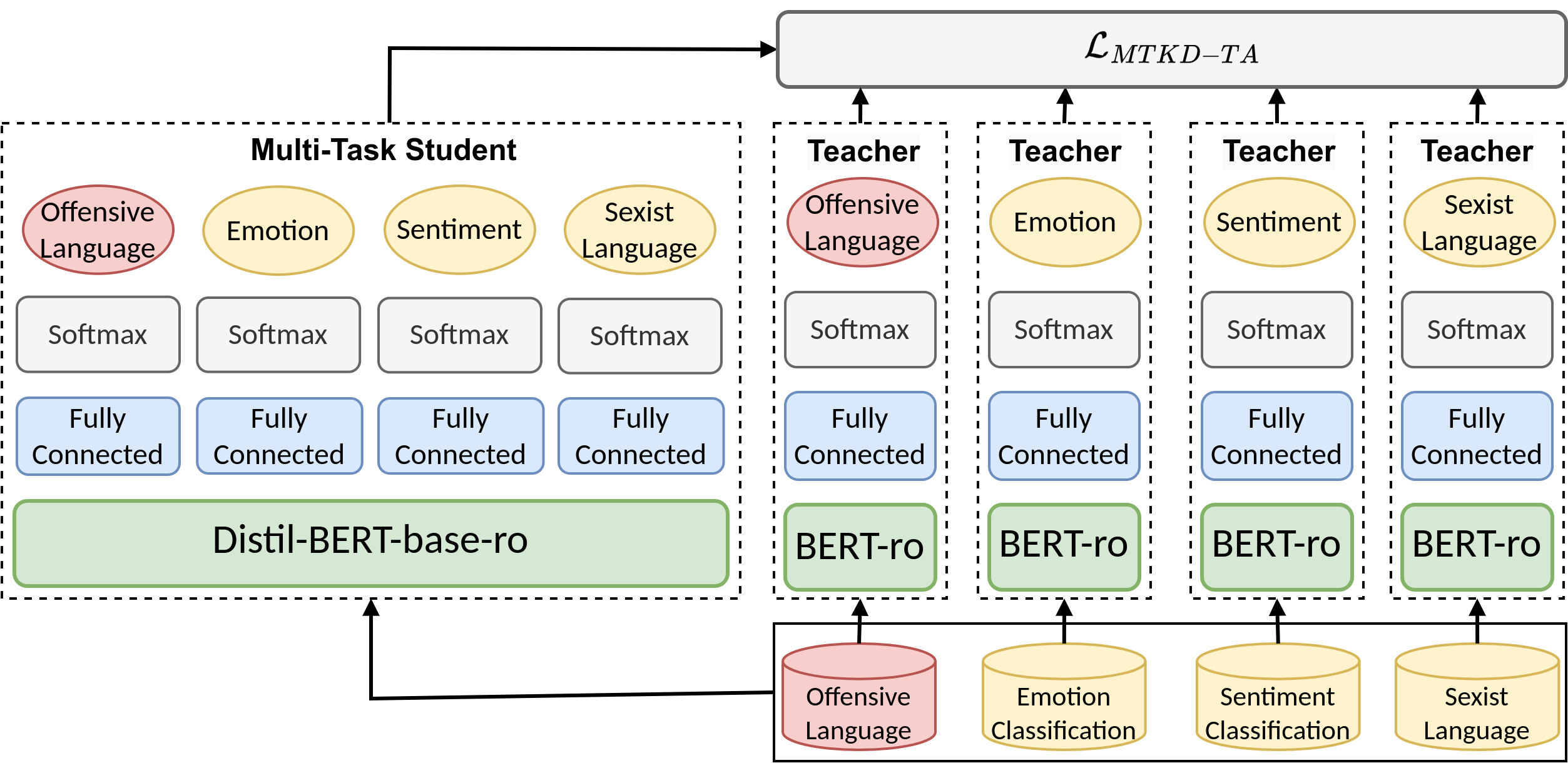
技术框架:整体框架包含以下几个主要模块:1) 基于 Transformer 的教师模型训练;2) 数据增强模块,用于生成更多训练样本;3) 基于知识蒸馏的学生模型训练,学生模型学习教师模型的输出;4) 多任务学习模块,同时在多个相关数据集上进行训练。教师模型首先在一个大型数据集上进行预训练,然后学生模型通过知识蒸馏学习教师模型的输出。多任务学习模块则将多个数据集整合在一起,共同训练学生模型。
关键创新:论文的关键创新在于将知识蒸馏、多任务学习和数据增强三种技术有效地结合起来,用于提升罗马尼亚语攻击性语言检测的性能。这种组合方法能够充分利用不同技术的优势,从而获得更好的效果。此外,论文还探索了教师退火策略,进一步提升了知识蒸馏的效果。
关键设计:论文中可能涉及的关键设计包括:1) 教师模型的选择,例如选择预训练的罗马尼亚语 Transformer 模型;2) 学生模型的结构,通常选择比教师模型更小的模型;3) 知识蒸馏的损失函数,例如使用 KL 散度来衡量学生模型和教师模型输出之间的差异;4) 多任务学习的权重设置,需要平衡不同数据集之间的贡献;5) 数据增强的方法,例如使用回译、同义词替换等技术。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了所提出方法的有效性,结果表明,结合知识蒸馏、多任务学习和数据增强能够显著提升罗马尼亚语攻击性语言检测的性能。具体的性能数据(例如F1值、准确率等)以及与基线模型的对比结果需要在论文中查找。
🎯 应用场景
该研究成果可应用于社交媒体平台、在线论坛等场景,用于自动检测和过滤罗马尼亚语的攻击性言论,从而维护网络环境的健康。此外,该方法也可推广到其他低资源语言的攻击性语言检测任务中,具有广泛的应用前景。
📄 摘要(原文)
This paper highlights the significance of natural language processing (NLP) within artificial intelligence, underscoring its pivotal role in comprehending and modeling human language. Recent advancements in NLP, particularly in conversational bots, have garnered substantial attention and adoption among developers. This paper explores advanced methodologies for attaining smaller and more efficient NLP models. Specifically, we employ three key approaches: (1) training a Transformer-based neural network to detect offensive language, (2) employing data augmentation and knowledge distillation techniques to increase performance, and (3) incorporating multi-task learning with knowledge distillation and teacher annealing using diverse datasets to enhance efficiency. The culmination of these methods has yielded demonstrably improved outcomes.