Analysing Zero-Shot Readability-Controlled Sentence Simplification
作者: Abdullah Barayan, Jose Camacho-Collados, Fernando Alva-Manchego
分类: cs.CL
发布日期: 2024-09-30 (更新: 2024-12-16)
备注: Accepted on COLING 2025
💡 一句话要点
探索零样本可读性控制的句子简化方法,分析上下文信息的影响。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本简化 可读性控制 零样本学习 大型语言模型 指令调优
📋 核心要点
- 现有RCTS模型依赖大规模平行语料,数据稀缺且标注成本高昂,限制了模型应用。
- 论文探索利用指令调优的大型语言模型,在零样本场景下实现可读性控制的句子简化。
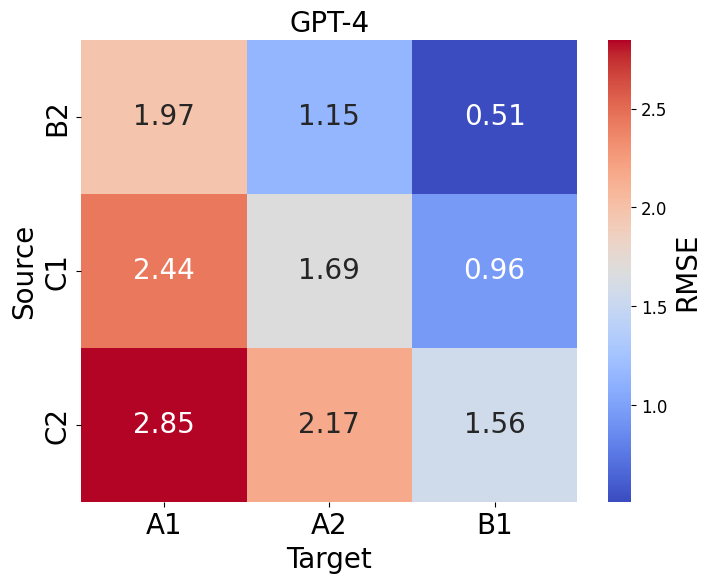
- 实验表明模型在简化句子方面存在困难,并指出当前自动评估指标在RCTS任务上的不足。
📝 摘要(中文)
可读性控制的文本简化(RCTS)旨在重写文本以降低可读性水平,同时保留其含义。RCTS模型通常依赖于在源端和目标端都具有可读性注释的平行语料库。然而,这种数据集稀缺且难以整理,尤其是在句子级别。为了减少对平行数据的依赖,我们探索使用指令调优的大型语言模型进行零样本RCTS。通过自动和人工评估,我们研究了:(1)不同类型的上下文信息如何影响模型生成具有所需可读性的句子的能力,以及(2)实现目标可读性与保持含义之间的权衡。结果表明,由于模型的局限性和源句的特性阻碍了充分的重写,所有测试模型都难以简化句子(尤其是到最低级别)。我们的实验还强调需要更好的针对RCTS的自动评估指标,因为标准指标经常错误地解释常见的简化操作,并错误地评估可读性和含义保留。
🔬 方法详解
问题定义:论文旨在解决可读性控制的句子简化问题,即在不改变句子语义的前提下,降低句子的可读性,使其更易于理解。现有方法主要依赖于平行语料库,但高质量的平行语料库难以获取,限制了RCTS模型的应用范围。
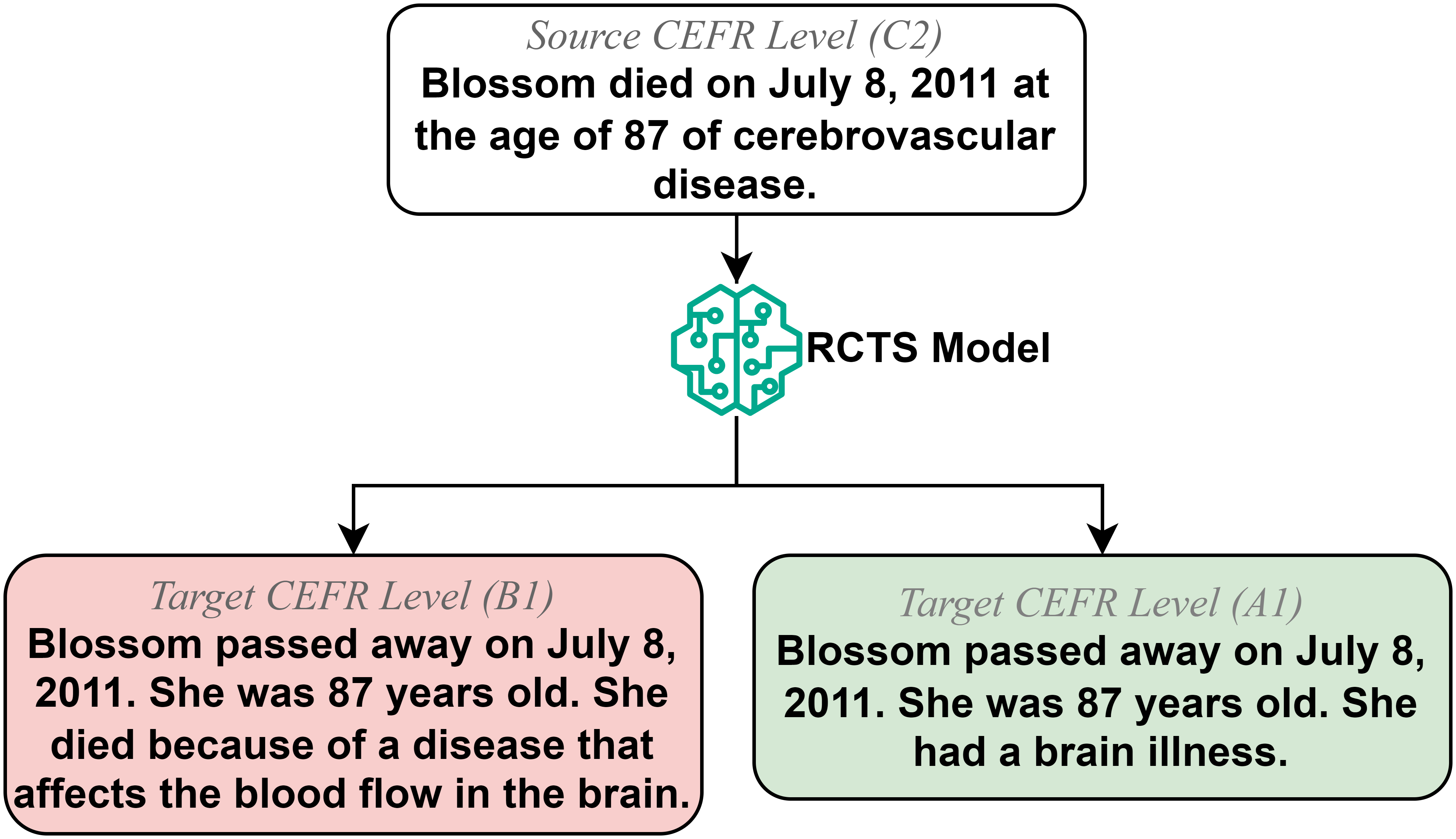
核心思路:论文的核心思路是利用指令调优的大型语言模型,通过指令引导模型在零样本场景下进行句子简化。通过调整输入指令,控制模型生成具有特定可读性水平的简化句子,从而避免对平行语料库的依赖。
技术框架:论文采用指令调优的大型语言模型作为核心框架。具体流程为:首先,将原始句子和目标可读性水平作为输入指令传递给模型;然后,模型根据指令生成简化后的句子;最后,通过自动和人工评估方法,评估生成句子的可读性和语义保持程度。
关键创新:论文的关键创新在于探索了零样本RCTS方法,摆脱了对平行语料库的依赖。此外,论文还分析了不同类型的上下文信息对模型生成结果的影响,并指出了现有自动评估指标在RCTS任务上的不足。
关键设计:论文的关键设计包括:(1) 设计不同的指令模板,以控制模型生成具有特定可读性水平的句子;(2) 探索不同的上下文信息输入方式,例如句子级别、段落级别等;(3) 采用多种自动评估指标和人工评估方法,综合评估生成句子的质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所有测试模型在简化句子方面都面临挑战,尤其是在将句子简化到最低可读性水平时。论文还发现,现有的自动评估指标在评估RCTS任务时存在局限性,容易错误地解释常见的简化操作,并不能准确评估可读性和语义保持程度。这些发现为未来RCTS研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于教育领域,例如为不同阅读水平的学生提供定制化的阅读材料。此外,还可以应用于新闻报道、法律文件等领域,将复杂文本简化为易于理解的版本,提高信息的可访问性。未来,该技术有望进一步提升文本简化效果,并应用于更多场景。
📄 摘要(原文)
Readability-controlled text simplification (RCTS) rewrites texts to lower readability levels while preserving their meaning. RCTS models often depend on parallel corpora with readability annotations on both source and target sides. Such datasets are scarce and difficult to curate, especially at the sentence level. To reduce reliance on parallel data, we explore using instruction-tuned large language models for zero-shot RCTS. Through automatic and manual evaluations, we examine: (1) how different types of contextual information affect a model's ability to generate sentences with the desired readability, and (2) the trade-off between achieving target readability and preserving meaning. Results show that all tested models struggle to simplify sentences (especially to the lowest levels) due to models' limitations and characteristics of the source sentences that impede adequate rewriting. Our experiments also highlight the need for better automatic evaluation metrics tailored to RCTS, as standard ones often misinterpret common simplification operations, and inaccurately assess readability and meaning preservation.