Using Large Multimodal Models to Extract Knowledge Components for Knowledge Tracing from Multimedia Question Information
作者: Hyeongdon Moon, Richard Davis, Seyed Parsa Neshaei, Pierre Dillenbourg
分类: cs.CL
发布日期: 2024-09-30 (更新: 2025-07-07)
备注: Accepted to Educational Data Mining 2025
💡 一句话要点
利用大型多模态模型从多媒体问题信息中提取知识成分,用于知识追踪
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识追踪 大型多模态模型 知识成分提取 智能辅导系统 自动化评估
📋 核心要点
- 现有知识追踪方法依赖统计数据和人工定义的知识成分,难以整合AI生成的教育内容。
- 提出利用指令调优的大型多模态模型,自动从教育内容中提取知识成分。
- 实验表明,自动提取的知识成分可有效替代人工标注,提升智能辅导系统性能。
📝 摘要(中文)
知识追踪模型使得智能辅导系统能够为学生提供反馈。然而,学习科学中现有的知识追踪方法主要依赖于统计数据和教师定义的知识成分,这使得将AI生成的教育内容与传统的既定方法相结合具有挑战性。本文提出了一种使用指令调优的大型多模态模型从教育内容中自动提取知识成分的方法。通过在五个领域中针对知识追踪基准进行全面评估来验证该方法。结果表明,自动提取的知识成分可以有效地替代人工标注的标签,为在有限数据场景中增强智能辅导系统、在教育环境中实现更具可解释性的评估以及为自动化评估奠定基础提供了一个有希望的方向。
🔬 方法详解
问题定义:论文旨在解决知识追踪领域中,依赖人工标注知识成分的局限性问题。现有方法需要大量人工标注,成本高昂且难以扩展,尤其是在缺乏足够数据的情况下。此外,人工定义的知识成分可能存在主观性,影响知识追踪的准确性和可解释性。
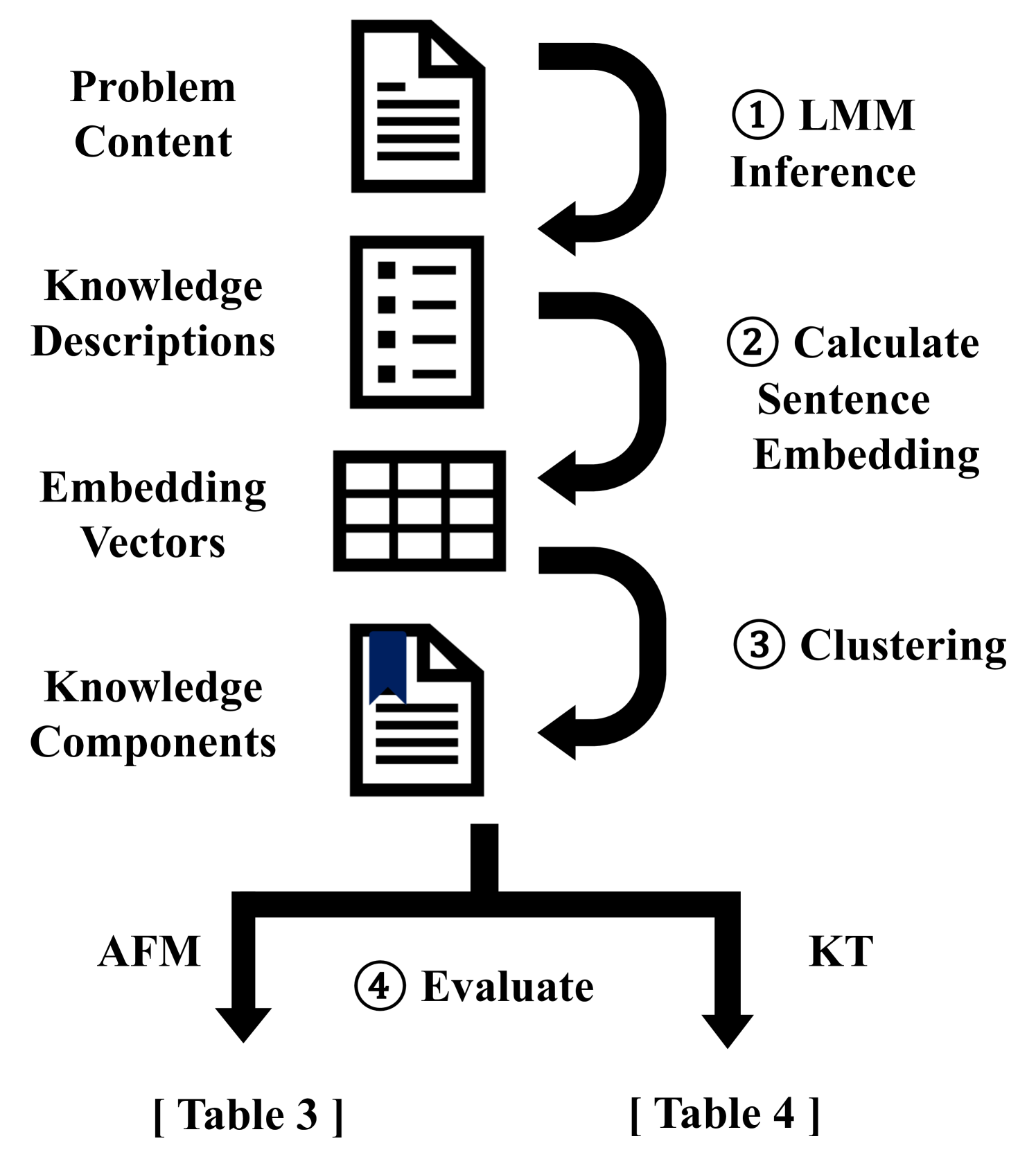
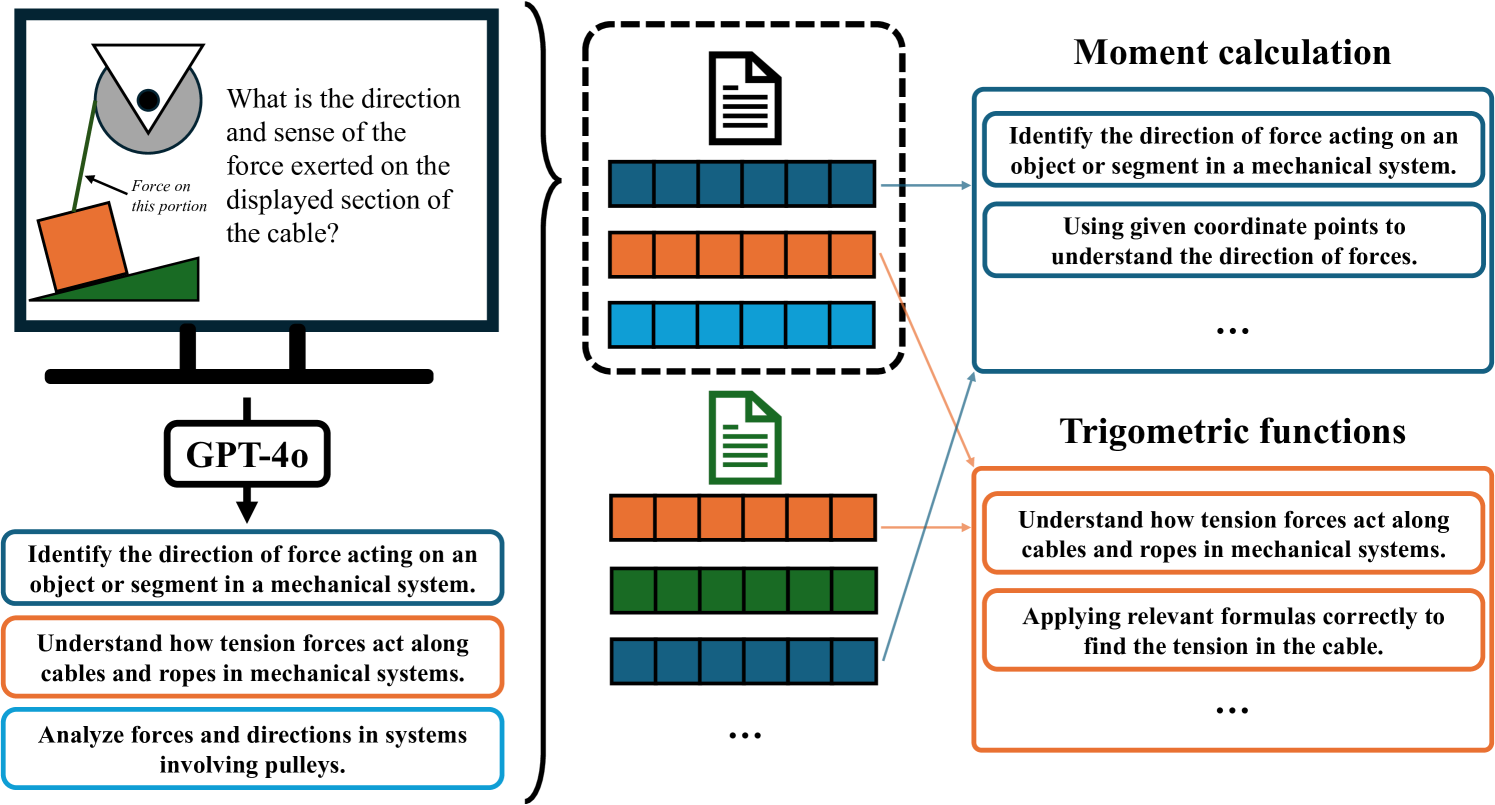
核心思路:论文的核心思路是利用大型多模态模型(LMMs)的强大理解和推理能力,自动从多媒体教育内容中提取知识成分。通过指令调优,使LMMs能够理解教育内容并识别其中蕴含的知识点,从而替代人工标注。
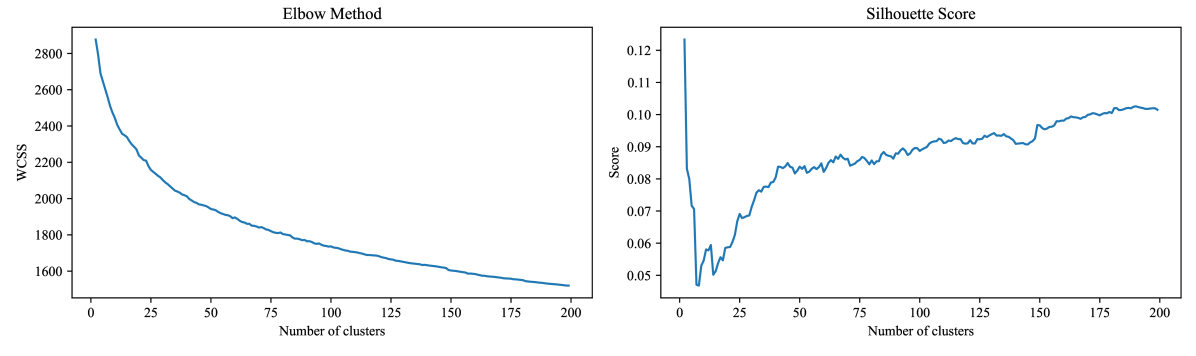
技术框架:该方法主要包含以下几个阶段:1) 数据准备:收集包含多媒体问题信息的教育内容。2) 模型选择与指令调优:选择预训练的大型多模态模型,并使用教育领域的特定指令进行微调,使其能够理解教育内容并提取知识成分。3) 知识成分提取:利用调优后的LMMs,从教育内容中提取知识成分。4) 知识追踪模型训练与评估:将提取的知识成分用于训练知识追踪模型,并在基准数据集上进行评估。
关键创新:该方法最重要的创新点在于利用大型多模态模型自动提取知识成分,从而摆脱了对人工标注的依赖。与传统方法相比,该方法能够更高效、更经济地获取知识成分,并具有更好的可扩展性和适应性。
关键设计:论文中,指令调优是关键的设计环节。通过精心设计的指令,引导LMMs理解教育内容并提取知识成分。具体的指令形式和调优策略(例如,使用的损失函数、学习率等)对最终的知识成分提取效果至关重要。此外,如何将提取的知识成分有效地融入到知识追踪模型中,也是一个重要的设计考虑。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用自动提取的知识成分训练的知识追踪模型,在五个领域的基准数据集上取得了与人工标注标签相媲美的性能。这表明,大型多模态模型能够有效地理解教育内容并提取有用的知识成分,为知识追踪提供了一种新的解决方案。
🎯 应用场景
该研究成果可应用于智能辅导系统、在线教育平台和自动化评估工具等领域。通过自动提取知识成分,可以降低知识追踪模型的构建成本,提高模型的准确性和可解释性,并为个性化学习提供更精准的支持。未来,该方法有望推动教育领域的智能化发展,实现更高效、更公平的教育资源分配。
📄 摘要(原文)
Knowledge tracing models have enabled a range of intelligent tutoring systems to provide feedback to students. However, existing methods for knowledge tracing in learning sciences are predominantly reliant on statistical data and instructor-defined knowledge components, making it challenging to integrate AI-generated educational content with traditional established methods. We propose a method for automatically extracting knowledge components from educational content using instruction-tuned large multimodal models. We validate this approach by comprehensively evaluating it against knowledge tracing benchmarks in five domains. Our results indicate that the automatically extracted knowledge components can effectively replace human-tagged labels, offering a promising direction for enhancing intelligent tutoring systems in limited-data scenarios, achieving more explainable assessments in educational settings, and laying the groundwork for automated assessment.