Aggressive Post-Training Compression on Extremely Large Language Models
作者: Zining Zhang, Yao Chen, Bingsheng He, Zhenjie Zhang
分类: cs.CL, cs.AI
发布日期: 2024-09-30
💡 一句话要点
提出一种激进的后训练压缩方法,在保证精度下高效压缩超大语言模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型压缩 后训练量化 网络剪枝 模型部署
📋 核心要点
- 现有LLM体积庞大,难以在算力受限的设备上部署,模型压缩是关键。
- 论文提出一种高稀疏度剪枝和低比特量化相结合的压缩方法,旨在大幅降低模型大小。
- 实验表明,该方法能在较短时间内压缩LLM,并在精度损失可接受范围内实现高效压缩。
📝 摘要(中文)
大型语言模型(LLMs)日益增长的规模和复杂性给它们在个人电脑和移动设备上的部署带来了挑战。激进的后训练模型压缩对于减小模型尺寸是必要的,但它通常会导致显著的精度损失。为了解决这个挑战,我们提出了一种新颖的网络剪枝技术,该技术利用超过0.7的稀疏性和小于8比特的量化。我们的方法能够在几个小时内压缩主流LLMs,同时保持相对较小的精度损失。在实验评估中,我们的方法展示了有效性和实际部署的潜力。通过使LLMs能够在本地设备上使用,我们的工作可以促进自然语言处理应用的新时代,并产生广泛的影响。
🔬 方法详解
问题定义:论文旨在解决超大型语言模型(LLMs)在资源受限设备上部署的问题。现有模型压缩方法,如传统的剪枝和量化,在压缩率较高时往往会导致显著的精度下降,难以满足实际应用的需求。因此,如何在保证模型精度的前提下,实现对LLMs的高效压缩是本研究要解决的核心问题。
核心思路:论文的核心思路是采用一种激进的后训练压缩策略,即在模型训练完成后,通过高比例的稀疏化剪枝和低比特量化,尽可能地减小模型的大小。这种策略的关键在于如何在剪枝和量化的过程中,最大程度地保留模型的重要信息,从而避免严重的精度损失。
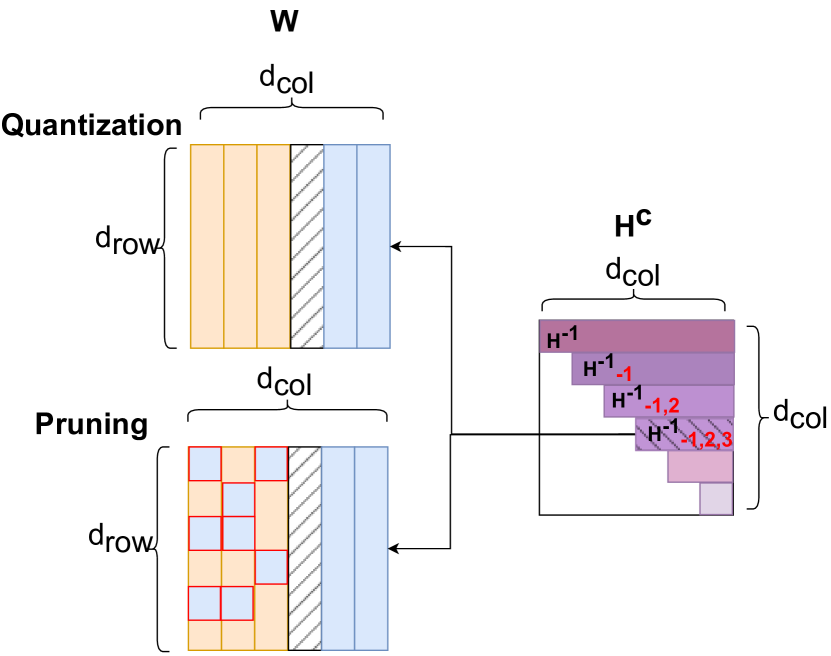
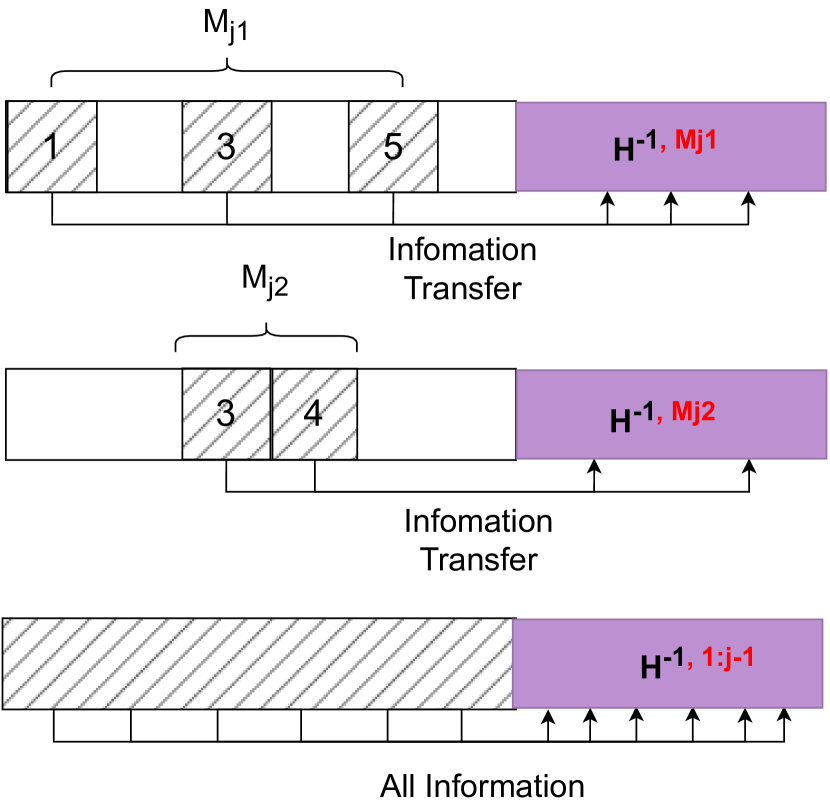
技术框架:论文提出的压缩方法主要包含两个阶段:高稀疏度剪枝和低比特量化。首先,通过网络剪枝技术,移除模型中冗余的连接,实现模型结构的稀疏化。然后,对模型中的权重和激活值进行量化,将浮点数转换为低比特的整数,进一步减小模型的大小。这两个阶段可以独立进行,也可以结合使用,以达到最佳的压缩效果。
关键创新:论文的关键创新在于提出了一种能够有效结合高稀疏度剪枝和低比特量化的压缩方法,能够在保证模型精度的前提下,实现对LLMs的高效压缩。该方法通过精细的剪枝策略和量化方案,最大程度地保留了模型的重要信息,从而避免了严重的精度损失。
关键设计:论文中关于剪枝和量化的具体技术细节未知,摘要中没有明确说明。但可以推测,剪枝策略可能采用了某种重要性评估方法,例如基于梯度或激活值的剪枝,以保留对模型性能影响较大的连接。量化方案可能采用了对称量化或非对称量化,并针对LLMs的特点进行了优化。
🖼️ 关键图片
📊 实验亮点
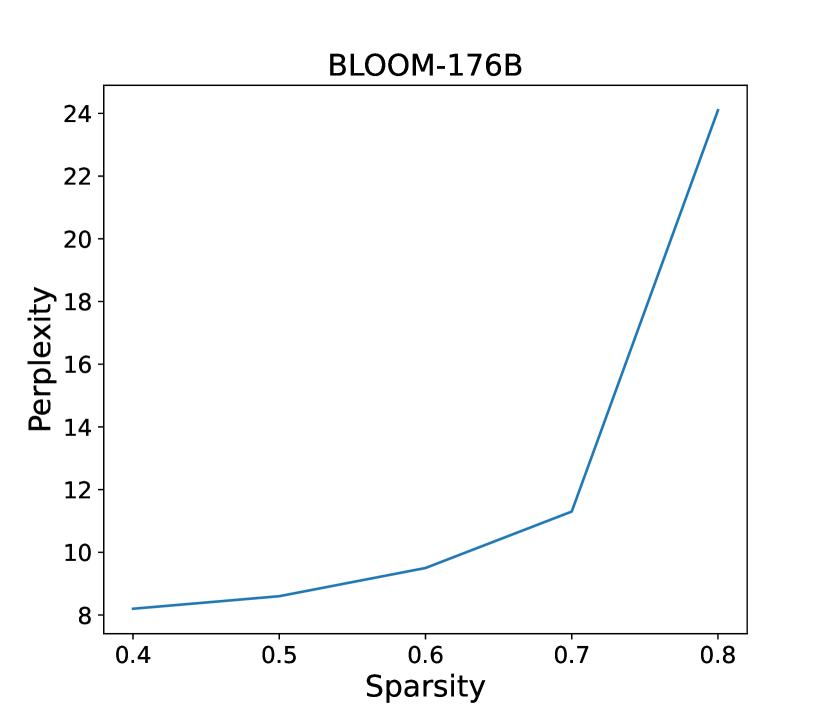
论文提出了一种激进的后训练压缩方法,能够在几个小时内压缩主流LLMs,同时保持相对较小的精度损失。具体性能数据和对比基线在摘要中未提及,但强调了该方法在压缩效率和精度保持方面的潜力,使其具备实际部署的可能性。
🎯 应用场景
该研究成果可应用于将大型语言模型部署到算力受限的设备上,如个人电脑、移动设备和嵌入式系统。这使得在本地设备上运行复杂的自然语言处理应用成为可能,例如离线翻译、智能助手和文本生成,从而提高用户隐私和响应速度。此外,该技术还有助于降低LLM的部署成本,促进其在更广泛领域的应用。
📄 摘要(原文)
The increasing size and complexity of Large Language Models (LLMs) pose challenges for their deployment on personal computers and mobile devices. Aggressive post-training model compression is necessary to reduce the models' size, but it often results in significant accuracy loss. To address this challenge, we propose a novel network pruning technology that utilizes over 0.7 sparsity and less than 8 bits of quantization. Our approach enables the compression of prevailing LLMs within a couple of hours while maintaining a relatively small accuracy loss. In experimental evaluations, our method demonstrates effectiveness and potential for practical deployment. By making LLMs available on domestic devices, our work can facilitate a new era of natural language processing applications with wide-ranging impacts.