Beyond Scores: A Modular RAG-Based System for Automatic Short Answer Scoring with Feedback
作者: Menna Fateen, Bo Wang, Tsunenori Mine
分类: cs.CL, cs.AI
发布日期: 2024-09-30 (更新: 2024-10-10)
💡 一句话要点
提出基于模块化RAG的自动简答题评分与反馈系统,提升评分准确率并提供可解释反馈。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动简答题评分 检索增强生成 大型语言模型 零样本学习 少样本学习
📋 核心要点
- 现有ASAS-F方法依赖微调,泛化性差,且缺乏详细可解释的反馈。
- 提出模块化RAG系统,通过检索增强生成答案评分和反馈,无需大量提示工程。
- 实验表明,该系统在未见过的问题上评分准确率提升9%,具有良好的可扩展性。
📝 摘要(中文)
自动简答题评分(ASAS)有助于减轻教育工作者的评分负担,但通常缺乏详细、可解释的反馈。现有的ASAS与反馈(ASAS-F)方法依赖于使用有限数据集微调语言模型,这既耗费资源又难以在不同上下文中推广。最近使用大型语言模型(LLM)的方法主要集中在评分上,而没有进行广泛的微调。然而,它们通常严重依赖提示工程,要么无法生成详细的反馈,要么无法充分评估反馈。在本文中,我们提出了一种基于模块化检索增强生成(RAG)的ASAS-F系统,该系统在严格的零样本和少样本学习场景中对答案进行评分并生成反馈。我们设计该系统以适应各种教育任务,而无需使用自动提示生成框架进行大量的提示工程。结果表明,与微调相比,在未见过的问题上的评分准确率提高了9%,从而提供了一种可扩展且经济高效的解决方案。
🔬 方法详解
问题定义:论文旨在解决自动简答题评分(ASAS)中缺乏详细、可解释反馈的问题,并克服现有ASAS-F方法依赖于微调语言模型,导致泛化能力差和资源消耗大的问题。现有方法过度依赖prompt工程,且对生成反馈的质量评估不足。
核心思路:论文的核心思路是利用检索增强生成(RAG)框架,结合模块化设计,实现自动简答题评分和反馈生成。通过检索相关知识,增强LLM的生成能力,避免过度依赖prompt工程,并提高评分的准确性和反馈的可解释性。
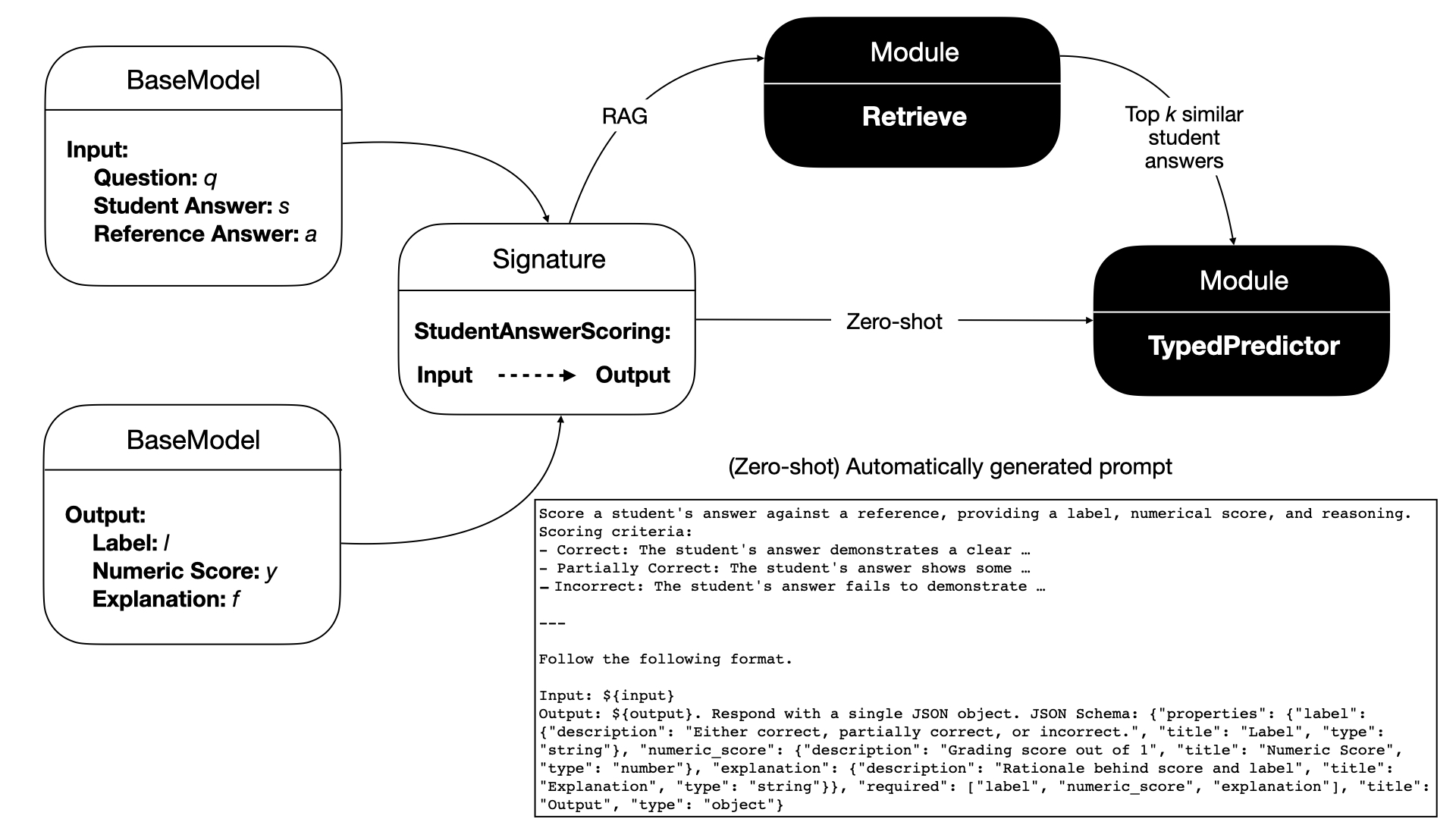
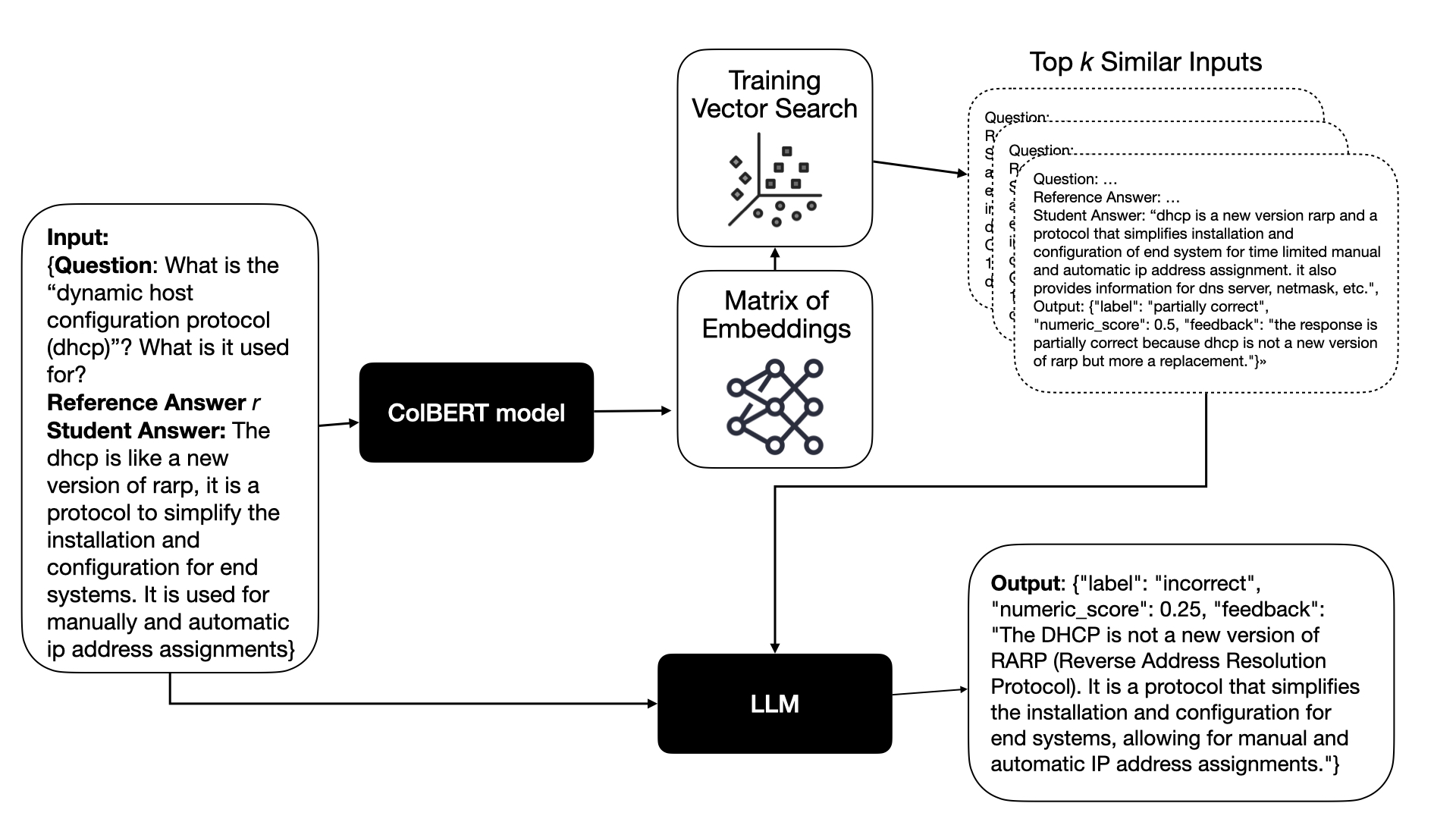
技术框架:该系统采用模块化RAG架构,包含以下主要模块:1) 自动prompt生成模块,用于生成适应不同教育任务的prompt;2) 检索模块,用于从知识库中检索与问题相关的文档;3) 生成模块,利用LLM基于检索到的文档和问题生成答案评分和反馈;4) 评估模块,用于评估生成反馈的质量。整个流程在零样本或少样本学习场景下进行,无需大量微调。
关键创新:该论文的关键创新在于:1) 提出了一种模块化的RAG框架,将ASAS-F任务分解为多个可独立优化的模块,提高了系统的灵活性和可扩展性;2) 采用自动prompt生成框架,减少了对人工prompt工程的依赖,降低了使用成本;3) 在严格的零样本和少样本学习场景下,实现了较高的评分准确率和可解释的反馈。
关键设计:自动prompt生成模块使用基于规则或基于学习的方法生成prompt。检索模块使用向量数据库存储知识库,并使用相似度搜索检索相关文档。生成模块使用预训练的LLM,并结合检索到的文档和问题生成答案评分和反馈。评估模块使用人工评估或自动指标评估生成反馈的质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该系统在未见过的问题上的评分准确率比微调方法提高了9%。该系统在零样本和少样本学习场景下表现良好,证明了其良好的泛化能力和可扩展性。此外,该系统生成的反馈具有较高的可解释性,能够帮助学生更好地理解错误原因。
🎯 应用场景
该研究成果可应用于在线教育平台、智能辅导系统等领域,实现自动化的简答题评分和个性化反馈,减轻教师的评分负担,提高教学效率。此外,该方法还可扩展到其他需要生成解释性文本的任务,例如自动代码审查、法律咨询等。
📄 摘要(原文)
Automatic short answer scoring (ASAS) helps reduce the grading burden on educators but often lacks detailed, explainable feedback. Existing methods in ASAS with feedback (ASAS-F) rely on fine-tuning language models with limited datasets, which is resource-intensive and struggles to generalize across contexts. Recent approaches using large language models (LLMs) have focused on scoring without extensive fine-tuning. However, they often rely heavily on prompt engineering and either fail to generate elaborated feedback or do not adequately evaluate it. In this paper, we propose a modular retrieval augmented generation based ASAS-F system that scores answers and generates feedback in strict zero-shot and few-shot learning scenarios. We design our system to be adaptable to various educational tasks without extensive prompt engineering using an automatic prompt generation framework. Results show an improvement in scoring accuracy by 9\% on unseen questions compared to fine-tuning, offering a scalable and cost-effective solution.