Do Influence Functions Work on Large Language Models?
作者: Zhe Li, Wei Zhao, Yige Li, Jun Sun
分类: cs.CL, cs.AI
发布日期: 2024-09-30 (更新: 2024-12-19)
备注: 15 pages, 4 figures
💡 一句话要点
研究表明影响函数在大型语言模型上的表现不佳,并分析了其原因。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 影响函数 大型语言模型 可解释性 训练数据 模型优化
📋 核心要点
- 现有影响函数在传统机器学习模型中应用广泛,但在大型语言模型(LLM)中的有效性尚不明确。
- 该研究通过系统评估影响函数在LLM上的表现,揭示其性能瓶颈并分析潜在原因。
- 实验结果表明,影响函数在LLM上表现不佳,并归因于近似误差、收敛问题以及定义本身。
📝 摘要(中文)
影响函数对于量化单个训练数据点对模型预测的影响至关重要。尽管在传统机器学习模型中对影响函数进行了广泛的研究,但它们在大型语言模型(LLM)中的应用受到限制。本文旨在系统地研究一个关键问题:影响函数在LLM上是否有效?具体而言,我们评估了影响函数在多个任务中的表现,发现它们在大多数情况下表现不佳。进一步的调查表明,其性能不佳可归因于:(1)由于LLM的规模,在估计iHVP分量时不可避免的近似误差;(2)微调期间的不确定收敛;以及,更根本的是,(3)定义本身,因为模型参数的变化不一定与LLM行为的变化相关。因此,我们的研究表明需要替代方法来识别有影响力的样本。
🔬 方法详解
问题定义:论文旨在评估影响函数在大型语言模型(LLM)上的有效性。现有方法在传统机器学习模型上表现良好,但直接应用于LLM时,其有效性受到质疑。痛点在于,LLM的规模和复杂性可能导致影响函数计算的不准确性,从而影响其在识别关键训练样本方面的作用。
核心思路:论文的核心思路是通过实验评估影响函数在不同LLM任务上的表现,并分析其失效的原因。通过深入研究影响函数在LLM上的局限性,为未来开发更有效的LLM训练数据选择方法提供指导。
技术框架:该研究采用实验驱动的方法。首先,选择多个LLM和不同的任务。然后,使用标准的影响函数计算方法,评估每个训练样本对模型预测的影响。最后,分析影响函数的预测结果与实际情况的偏差,并尝试找出导致偏差的原因。主要模块包括:数据准备、影响函数计算、结果评估和误差分析。
关键创新:该研究的关键创新在于系统性地评估了影响函数在LLM上的有效性,并深入分析了其失效的原因。以往的研究主要集中在传统机器学习模型上,而忽略了LLM的特殊性。该研究揭示了LLM规模、训练过程和模型行为对影响函数的影响,为未来研究提供了新的视角。
关键设计:研究中使用了标准的影响函数计算方法,包括计算Hessian矩阵的逆(iHVP)。由于LLM的规模,iHVP的计算采用了近似方法。此外,研究还考虑了微调过程中的收敛问题,以及模型参数变化与模型行为之间的关系。具体的参数设置和损失函数取决于所使用的LLM和任务。
🖼️ 关键图片

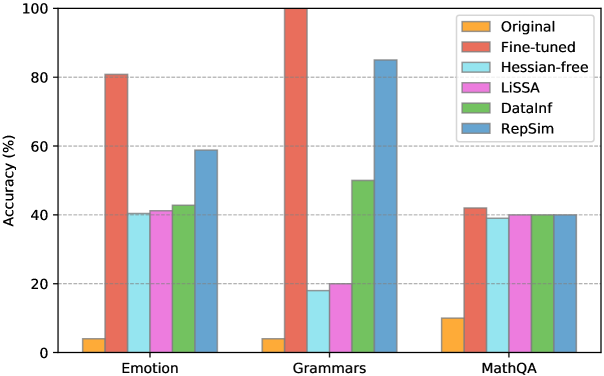
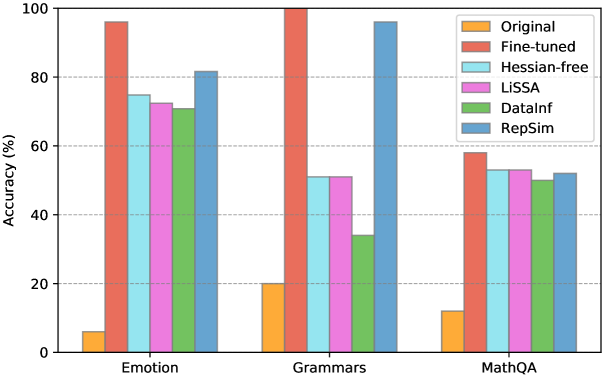
📊 实验亮点
实验结果表明,影响函数在大多数LLM任务中表现不佳。研究发现,影响函数预测的样本重要性与实际情况存在显著偏差。例如,在某些任务中,影响函数错误地将对模型性能有负面影响的样本识别为重要样本。这些结果表明,需要开发更适合LLM的训练数据选择方法。
🎯 应用场景
该研究结果对大型语言模型的训练和优化具有重要意义。了解影响函数在LLM上的局限性,有助于开发更有效的训练数据选择方法,从而提高模型性能并降低训练成本。此外,该研究还可以应用于模型调试和安全分析,例如识别导致模型产生有害输出的训练样本。
📄 摘要(原文)
Influence functions are important for quantifying the impact of individual training data points on a model's predictions. Although extensive research has been conducted on influence functions in traditional machine learning models, their application to large language models (LLMs) has been limited. In this work, we conduct a systematic study to address a key question: do influence functions work on LLMs? Specifically, we evaluate influence functions across multiple tasks and find that they consistently perform poorly in most settings. Our further investigation reveals that their poor performance can be attributed to: (1) inevitable approximation errors when estimating the iHVP component due to the scale of LLMs, (2) uncertain convergence during fine-tuning, and, more fundamentally, (3) the definition itself, as changes in model parameters do not necessarily correlate with changes in LLM behavior. Thus, our study suggests the need for alternative approaches for identifying influential samples.