2D-TPE: Two-Dimensional Positional Encoding Enhances Table Understanding for Large Language Models
作者: Jia-Nan Li, Jian Guan, Wei Wu, Zhengtao Yu, Rui Yan
分类: cs.CL
发布日期: 2024-09-29 (更新: 2024-10-18)
💡 一句话要点
提出2D-TPE,增强大语言模型对表格理解的空间信息捕捉能力
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格理解 大型语言模型 位置编码 二维空间信息 Transformer模型
📋 核心要点
- 现有方法将表格扁平化为一维序列,破坏了表格固有的二维空间结构,导致信息损失,影响LLM的表格理解能力。
- 论文提出2D-TPE,通过动态选择token排列顺序,模拟不同的表格遍历方式,使LLM更好地捕捉表格的空间关系。
- 实验结果表明,2D-TPE在多个表格理解基准测试中优于现有方法,尤其在处理大型表格时表现出更好的可扩展性。
📝 摘要(中文)
表格在各个领域被广泛应用,以简洁地表示结构化信息。使大型语言模型(LLMs)能够对表格数据进行推理是一个积极探索的方向。然而,由于典型的LLMs只支持一维(1D)输入,现有方法通常将二维(2D)表格结构扁平化为token序列,这会严重破坏空间关系,并导致关键上下文信息的不可避免的丢失。本文首先通过两个精心设计的代理任务,实证地证明了这种扁平化操作对LLMs捕捉表格空间信息的性能的有害影响。随后,我们提出了一种简单而有效的 positional encoding 方法,称为“2D-TPE”(二维表格 positional encoding),以应对这一挑战。2D-TPE使每个注意力头能够动态地选择上下文中token的排列顺序以关注它们,其中每个排列代表表格的不同遍历模式,例如按列或按行遍历。2D-TPE有效地降低了丢失重要空间信息的风险,同时保持了计算效率,从而更好地保留了表格结构。在五个基准测试中进行的大量实验表明,2D-TPE优于强大的基线,突出了保留表格结构对于准确的表格理解的重要性。综合分析进一步揭示了2D-TPE比基线具有明显更好的大型表格可扩展性。
🔬 方法详解
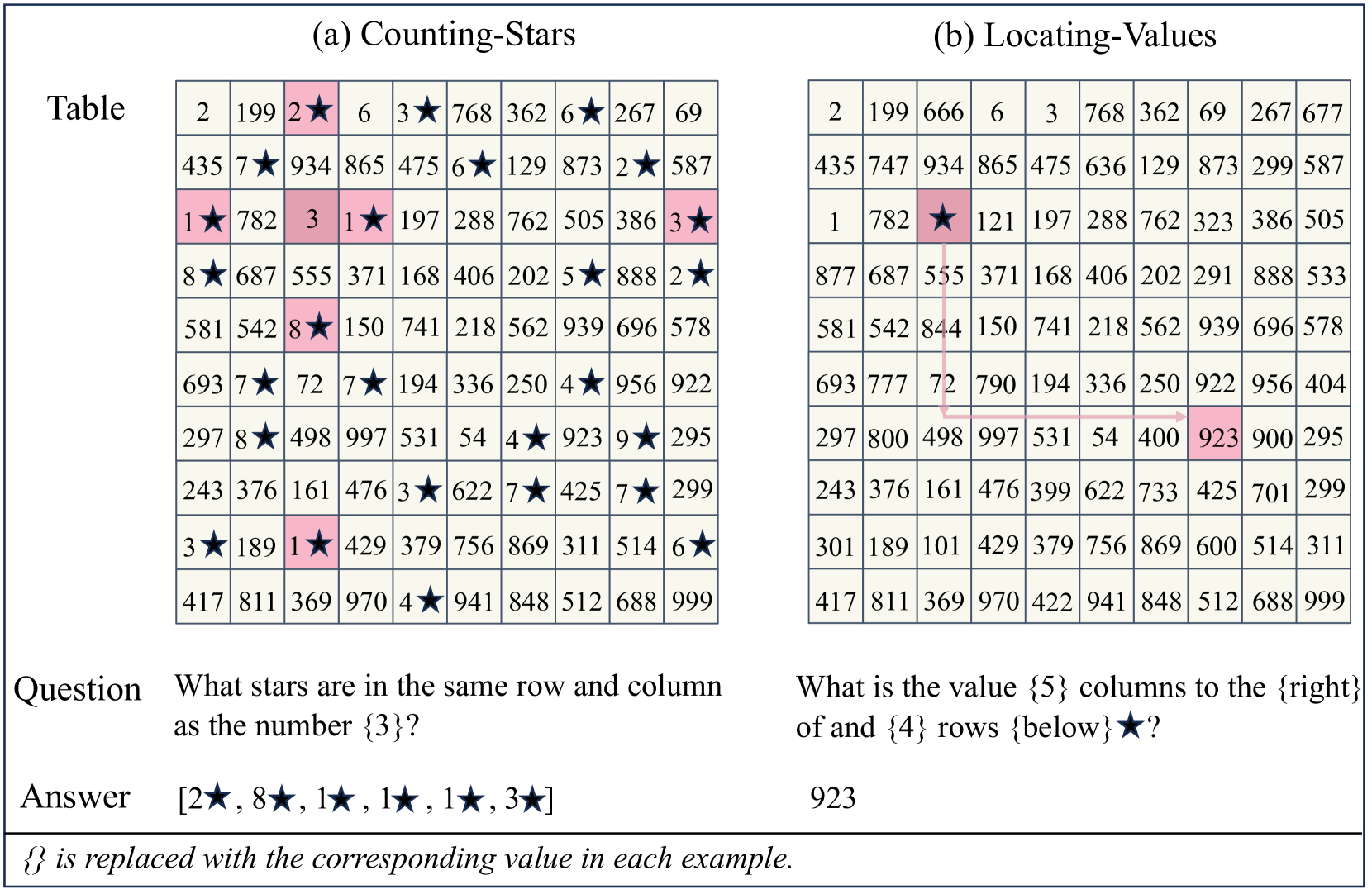
问题定义:现有的大型语言模型(LLMs)在处理表格数据时,通常需要将二维表格结构转换为一维的token序列。这种扁平化操作破坏了表格固有的空间信息,例如行、列之间的关系,导致LLMs难以准确理解表格内容。现有方法缺乏有效保留和利用表格空间信息的能力,限制了LLMs在表格理解任务中的性能。
核心思路:论文的核心思路是通过引入二维位置编码(2D-TPE)来显式地建模表格的空间结构。2D-TPE允许模型在处理表格数据时,动态地选择不同的token排列顺序,模拟不同的表格遍历方式(例如,按行、按列)。通过这种方式,模型可以更好地捕捉表格中不同位置之间的关系,从而提高表格理解的准确性。
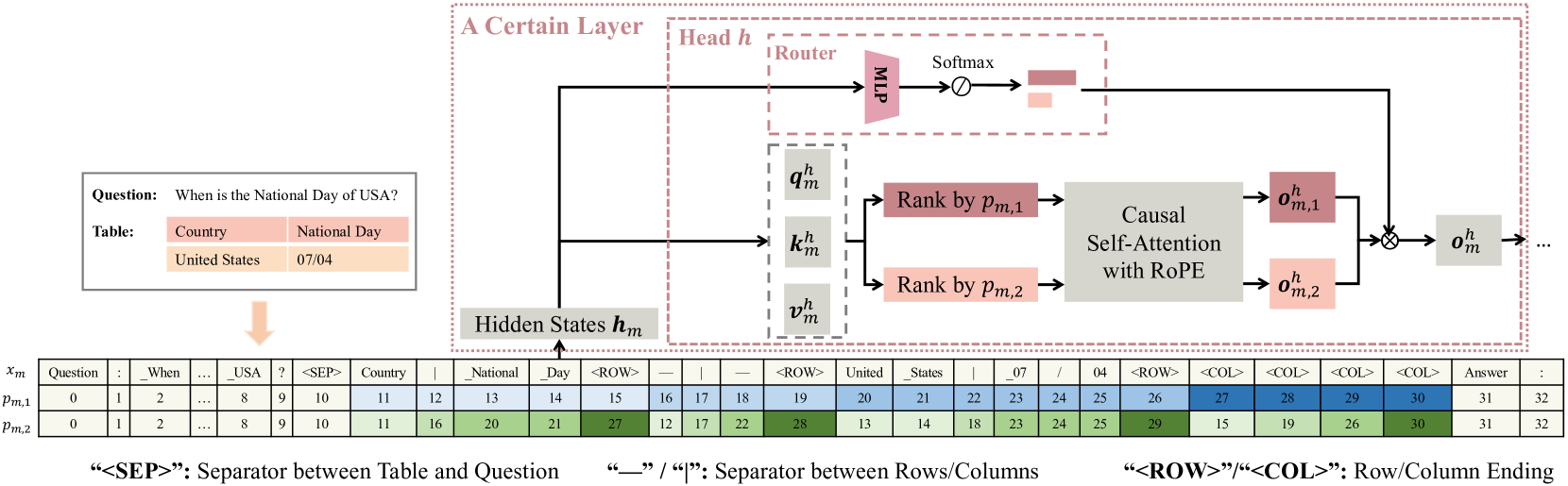
技术框架:2D-TPE方法主要包含以下几个步骤:1. 将二维表格转换为token序列。2. 为每个token生成二维位置编码。3. 将位置编码添加到token嵌入中。4. 使用Transformer模型进行处理,其中每个注意力头可以动态选择token的排列顺序。5. 使用选择的排列顺序计算注意力权重。
关键创新:2D-TPE的关键创新在于它允许每个注意力头动态地选择token的排列顺序。这种动态选择机制使得模型能够自适应地学习表格中不同位置之间的关系,从而更好地捕捉表格的空间结构。与传统的固定位置编码方法相比,2D-TPE更加灵活,能够更好地适应不同类型的表格数据。
关键设计:2D-TPE使用可学习的参数来控制token排列顺序的选择。具体来说,每个注意力头都有一个可学习的权重矩阵,用于计算不同排列顺序的得分。模型根据这些得分选择最佳的排列顺序。此外,论文还使用了多种不同的排列顺序,例如按行、按列、对角线等,以增加模型的表达能力。损失函数采用交叉熵损失,优化目标是使模型能够准确地预测表格中的内容。
🖼️ 关键图片
📊 实验亮点
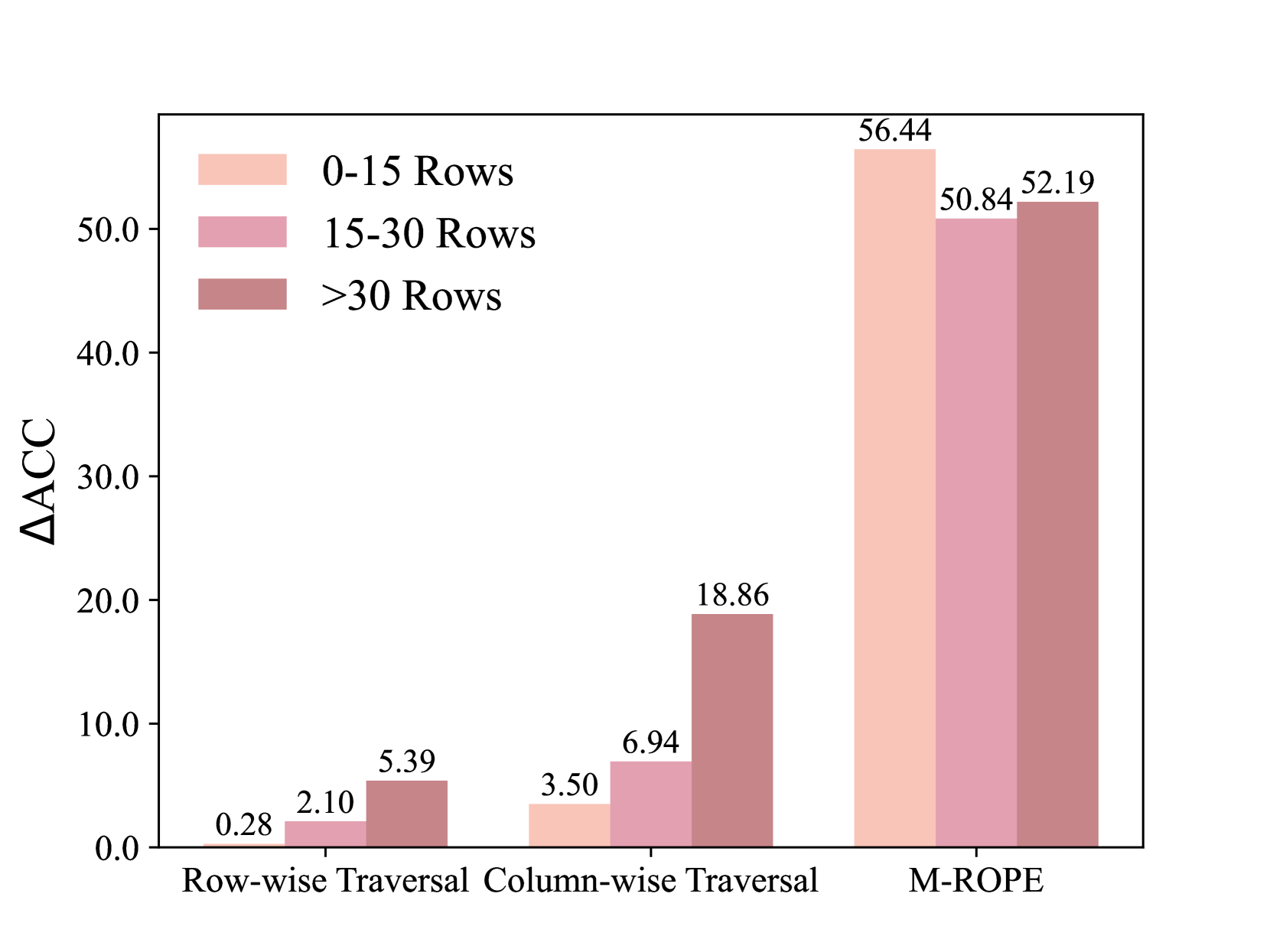
实验结果表明,2D-TPE在五个表格理解基准测试中均优于现有方法。例如,在某个基准测试中,2D-TPE的性能比最佳基线提高了5%。此外,实验还表明,2D-TPE在处理大型表格时表现出更好的可扩展性,这表明该方法具有很强的实用价值。
🎯 应用场景
该研究成果可广泛应用于需要理解表格数据的各种场景,例如金融报告分析、医学数据挖掘、知识图谱构建等。通过提升LLM对表格的理解能力,可以实现更智能的数据分析和决策支持,具有重要的实际应用价值和潜在的商业前景。未来,该技术可以进一步扩展到其他结构化数据的理解和推理。
📄 摘要(原文)
Tables are ubiquitous across various domains for concisely representing structured information. Empowering large language models (LLMs) to reason over tabular data represents an actively explored direction. However, since typical LLMs only support one-dimensional~(1D) inputs, existing methods often flatten the two-dimensional~(2D) table structure into a sequence of tokens, which can severely disrupt the spatial relationships and result in an inevitable loss of vital contextual information. In this paper, we first empirically demonstrate the detrimental impact of such flattening operations on the performance of LLMs in capturing the spatial information of tables through two elaborate proxy tasks. Subsequently, we introduce a simple yet effective positional encoding method, termed ``2D-TPE'' (Two-Dimensional Table Positional Encoding), to address this challenge. 2D-TPE enables each attention head to dynamically select a permutation order of tokens within the context for attending to them, where each permutation represents a distinct traversal mode for the table, such as column-wise or row-wise traversal. 2D-TPE effectively mitigates the risk of losing essential spatial information while preserving computational efficiency, thus better preserving the table structure. Extensive experiments across five benchmarks demonstrate that 2D-TPE outperforms strong baselines, underscoring the importance of preserving the table structure for accurate table comprehension. Comprehensive analysis further reveals the substantially better scalability of 2D-TPE to large tables than baselines.