Can Large Language Models Analyze Graphs like Professionals? A Benchmark, Datasets and Models
作者: Xin Li, Weize Chen, Qizhi Chu, Haopeng Li, Zhaojun Sun, Ran Li, Chen Qian, Yiwei Wei, Zhiyuan Liu, Chuan Shi, Maosong Sun, Cheng Yang
分类: cs.CL, cs.AI
发布日期: 2024-09-29 (更新: 2025-11-03)
备注: NeurIPS 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出ProGraph基准测试,评估并提升大语言模型在图分析任务中的专业能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图分析 大语言模型 基准测试 代码生成 文档检索 微调 LLM4Graph
📋 核心要点
- 现有LLM图分析基准测试局限于小规模图,无法模拟专业人员使用编程库处理大规模图的场景。
- 提出ProGraph基准测试,要求LLM通过编程解决图分析问题,更贴近实际应用。
- 构建LLM4Graph数据集,通过检索增强和代码微调,显著提升LLM在ProGraph上的性能。
📝 摘要(中文)
图分析在诸多领域至关重要。本文旨在评估并提升大语言模型(LLM)处理图数据的能力。现有图分析基准测试要求模型直接推理图拓扑结构,因此仅限于小规模图。为解决此问题,本文提出了ProGraph,一个手工构建的包含三类图任务的基准测试,要求模型基于编程解决问题。实验表明,现有LLM性能不佳,最佳模型准确率仅为36%。为弥补差距,本文构建了LLM4Graph数据集,包含爬取的文档和基于六个常用图库自动生成的代码。通过文档检索增强闭源LLM,以及在代码上微调开源LLM,准确率提升了11-32%。结果表明,LLM处理结构化数据的能力仍有待探索,LLM4Graph能有效提升LLM的图分析能力。基准测试、数据集和增强的开源模型已公开。
🔬 方法详解
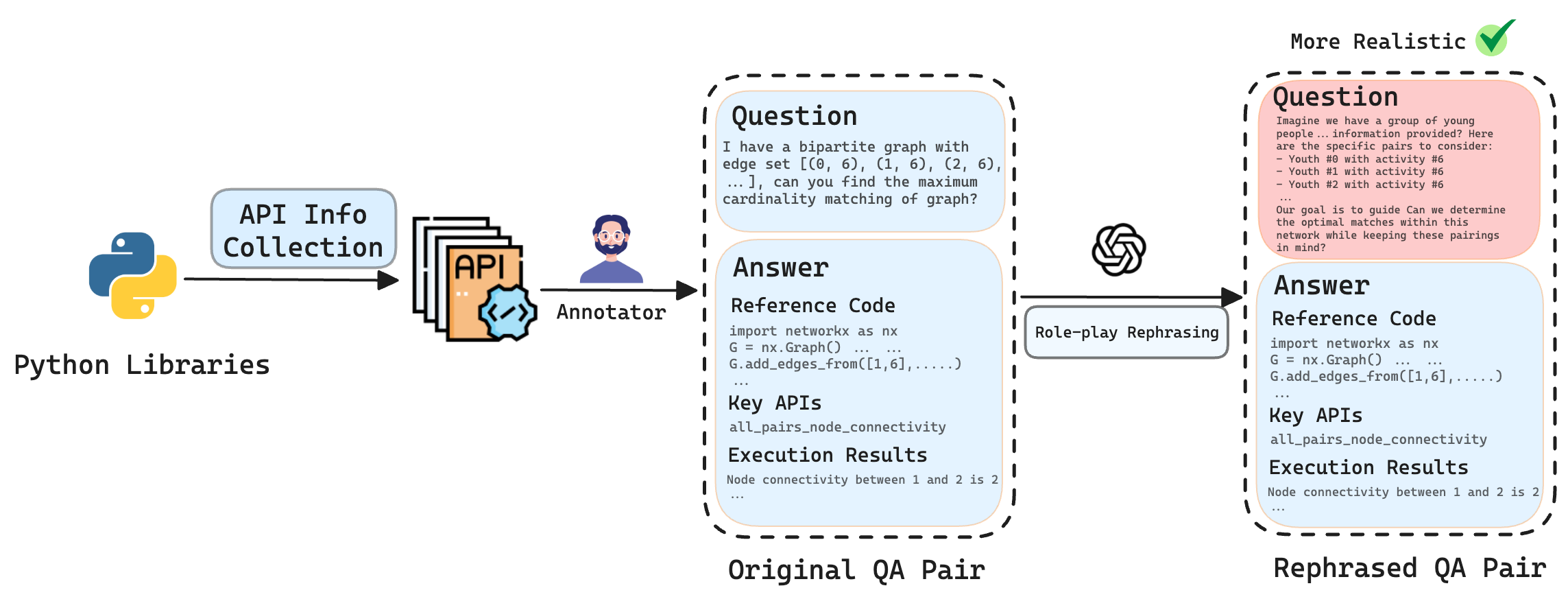
问题定义:现有的大语言模型在图分析任务中,通常直接基于图的拓扑结构进行推理,这限制了它们处理大规模图的能力。专业人员通常会使用编程库来解决图分析问题,而现有的基准测试无法有效评估LLM在这种场景下的能力。因此,需要一个更贴近实际应用场景的基准测试,以及相应的方法来提升LLM的图分析能力。
核心思路:本文的核心思路是构建一个更真实的图分析基准测试ProGraph,该基准测试要求LLM通过编写代码来解决图分析问题,而不是直接推理图的拓扑结构。此外,通过构建LLM4Graph数据集,利用文档检索和代码微调等技术,提升LLM在ProGraph上的性能。
技术框架:整体框架包含以下几个主要部分:1) 构建ProGraph基准测试,包含三个类别的图分析任务。2) 构建LLM4Graph数据集,包括从网络上爬取的文档和基于六个常用图库自动生成的代码。3) 使用文档检索增强闭源LLM,使其能够更好地利用文档信息。4) 在LLM4Graph数据集上微调开源LLM,提升其代码生成能力。5) 在ProGraph基准测试上评估不同模型的性能。
关键创新:本文的关键创新点在于:1) 提出了ProGraph基准测试,更真实地模拟了专业人员解决图分析问题的方式。2) 构建了LLM4Graph数据集,为LLM的图分析能力提升提供了数据支持。3) 结合文档检索和代码微调等技术,有效提升了LLM在图分析任务中的性能。与现有方法相比,本文的方法更注重LLM的编程能力和对图库的利用。
关键设计:在构建LLM4Graph数据集时,使用了六个常用的图库,包括NetworkX, PyG, DGL等。在文档检索方面,使用了标准的检索模型,例如BM25。在代码微调方面,使用了标准的语言模型微调方法,例如使用交叉熵损失函数进行训练。具体的参数设置和网络结构取决于所使用的LLM。
🖼️ 关键图片

📊 实验亮点
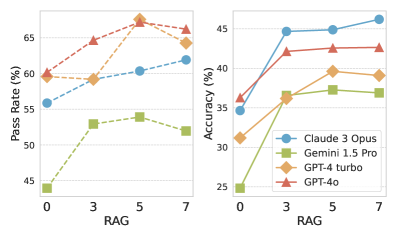
实验结果表明,现有LLM在ProGraph基准测试上的性能不佳,最佳模型准确率仅为36%。通过使用LLM4Graph数据集进行文档检索增强和代码微调,闭源LLM和开源LLM的准确率分别提升了11%和32%。这些结果表明,LLM4Graph能够有效提升LLM在图分析任务中的性能。
🎯 应用场景
该研究成果可应用于社交网络分析、生物网络分析、推荐系统等领域。通过提升LLM的图分析能力,可以更高效地处理大规模图数据,从而为相关应用提供更准确、更智能的解决方案。未来,该研究可以进一步扩展到其他结构化数据分析领域,例如知识图谱、数据库等。
📄 摘要(原文)
The need to analyze graphs is ubiquitous across various fields, from social networks to biological research and recommendation systems. Therefore, enabling the ability of large language models (LLMs) to process graphs is an important step toward more advanced general intelligence. However, current LLM benchmarks on graph analysis require models to directly reason over the prompts describing graph topology, and are thus limited to small graphs with only a few dozens of nodes. In contrast, human experts typically write programs based on popular libraries for task solving, and can thus handle graphs with different scales. To this end, a question naturally arises: can LLMs analyze graphs like professionals? In this paper, we introduce ProGraph, a manually crafted benchmark containing 3 categories of graph tasks. The benchmark expects solutions based on programming instead of directly reasoning over raw inputs. Our findings reveal that the performance of current LLMs is unsatisfactory, with the best model achieving only 36% accuracy. To bridge this gap, we propose LLM4Graph datasets, which include crawled documents and auto-generated codes based on 6 widely used graph libraries. By augmenting closed-source LLMs with document retrieval and fine-tuning open-source ones on the codes, we show 11-32% absolute improvements in their accuracies. Our results underscore that the capabilities of LLMs in handling structured data are still under-explored, and show the effectiveness of LLM4Graph in enhancing LLMs' proficiency of graph analysis. The benchmark, datasets and enhanced open-source models are available at https://github.com/BUPT-GAMMA/ProGraph.