Performance Evaluation of Tokenizers in Large Language Models for the Assamese Language
作者: Sagar Tamang, Dibya Jyoti Bora
分类: cs.CL
发布日期: 2024-09-28
DOI: 10.1007/s41870-025-02454-8
💡 一句话要点
评估大型语言模型分词器在阿萨姆语上的性能,揭示低资源语言多语言支持的优劣。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 分词器 阿萨姆语 低资源语言 性能评估 归一化序列长度 多语言支持
📋 核心要点
- 现有大型语言模型对低资源语言(如阿萨姆语)的支持不足,分词器性能是关键瓶颈。
- 通过评估不同LLM的分词器在阿萨姆语上的归一化序列长度(NSL),分析其性能优劣。
- 实验表明,Two AI的SUTRA分词器在阿萨姆语上表现最佳,GPT-4o紧随其后,优于其他模型。
📝 摘要(中文)
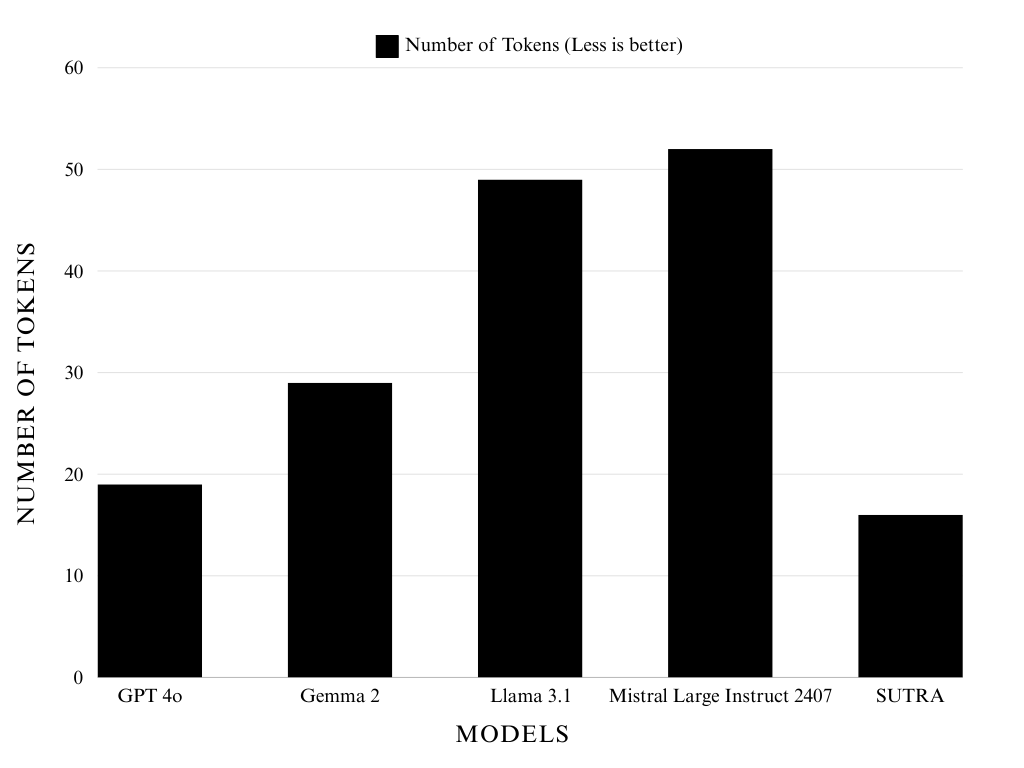
本研究旨在评估五种最先进的大型语言模型(LLM)的分词器在印度阿萨姆语上的性能。分词器的训练对深度学习模型的性能至关重要。这项研究对于理解像阿萨姆语这样低资源语言的多语言支持具有重要意义。研究结果表明,Two AI的SUTRA分词器表现最佳,平均归一化序列长度(NSL)值为0.45,紧随其后的是Open AI的GPT-4o分词器,平均NSL值为0.54,然后是Gemma 2、Meta Llama 3.1和Mistral Large Instruct 2407,平均NSL值分别为0.82、1.4和1.48。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在处理低资源语言(如阿萨姆语)时,分词器性能参差不齐的问题。现有方法缺乏对这些语言的针对性优化,导致分词效率低下,影响下游任务的性能。现有分词器在处理阿萨姆语等低资源语言时,可能存在词汇覆盖率不足、分词粒度不合理等问题,进而影响模型的整体性能。
核心思路:论文的核心思路是通过评估不同大型语言模型的分词器在阿萨姆语上的性能,来了解它们对低资源语言的支持程度。通过比较不同分词器的归一化序列长度(NSL),可以量化其分词效率,从而评估其性能。选择NSL作为评估指标,是因为它能够反映分词器将文本序列转换为token序列的效率,NSL越小,表示分词器能够用更少的token表示相同的文本,分词效率越高。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 收集阿萨姆语的文本数据;2) 选择五种具有代表性的大型语言模型(SUTRA, GPT-4o, Gemma 2, Meta Llama 3.1, Mistral Large Instruct 2407);3) 使用这些模型的tokenizer对阿萨姆语文本进行分词;4) 计算每个tokenizer的归一化序列长度(NSL);5) 比较不同tokenizer的NSL值,从而评估其性能。
关键创新:该研究的关键创新在于针对低资源语言阿萨姆语,系统性地评估了多个主流大型语言模型的分词器性能。以往的研究较少关注低资源语言的分词器性能,而该研究填补了这一空白。通过量化分词器的性能指标(NSL),为选择适合阿萨姆语的LLM提供了客观依据。与现有方法的本质区别在于,该研究不是直接改进分词算法,而是通过评估现有分词器在特定语言上的性能,为后续的优化工作提供指导。
关键设计:研究的关键设计在于选择归一化序列长度(NSL)作为评估指标。NSL的计算公式为:NSL = (Number of Tokens) / (Number of Characters)。选择NSL的原因在于它能够反映分词器将文本序列转换为token序列的效率,NSL越小,表示分词器能够用更少的token表示相同的文本,分词效率越高。此外,研究还精心选择了五种具有代表性的大型语言模型,以确保评估结果的广泛适用性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Two AI的SUTRA分词器在阿萨姆语上表现最佳,平均归一化序列长度(NSL)值为0.45,显著优于Meta Llama 3.1 (NSL=1.4) 和 Mistral Large Instruct 2407 (NSL=1.48)。GPT-4o的分词器表现也相对较好,NSL值为0.54。这些数据表明,不同LLM的分词器在低资源语言上的性能差异显著,选择合适的分词器至关重要。
🎯 应用场景
该研究成果可应用于提升阿萨姆语等低资源语言的自然语言处理能力,例如机器翻译、文本摘要、情感分析等。通过选择或优化适合特定低资源语言的分词器,可以提高LLM在该语言上的性能,促进文化传播和信息交流。未来,该研究方法可推广到其他低资源语言,为构建更具包容性的多语言AI系统提供支持。
📄 摘要(原文)
Training of a tokenizer plays an important role in the performance of deep learning models. This research aims to understand the performance of tokenizers in five state-of-the-art (SOTA) large language models (LLMs) in the Assamese language of India. The research is important to understand the multi-lingual support for a low-resourced language such as Assamese. Our research reveals that the tokenizer of SUTRA from Two AI performs the best with an average Normalized Sequence Length (NSL) value of 0.45, closely followed by the tokenizer of GPT-4o from Open AI with an average NSL value of 0.54, followed by Gemma 2, Meta Llama 3.1, and Mistral Large Instruct 2407 with an average NSL value of 0.82, 1.4, and 1.48 respectively.