HealthQ: Unveiling Questioning Capabilities of LLM Chains in Healthcare Conversations
作者: Ziyu Wang, Hao Li, Di Huang, Hye-Sung Kim, Chae-Won Shin, Amir M. Rahmani
分类: cs.CL, cs.LG
发布日期: 2024-09-28 (更新: 2025-02-25)
💡 一句话要点
提出HealthQ框架以评估医疗对话中的提问能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医疗对话 大型语言模型 提问能力 信息收集 自然语言处理 评估框架 模型无关
📋 核心要点
- 现有的医疗对话系统在主动提问和信息收集方面存在不足,难以有效引导患者提供关键信息。
- 本文提出HealthQ框架,通过评估LLM链的提问能力,结合多种评估指标,提升医疗对话的质量。
- 实验结果表明,HealthQ在多个LLM模型上表现出色,能够有效提高问题的特异性和相关性,从而改善信息收集效果。
📝 摘要(中文)
有效的数字医疗患者护理需要大型语言模型(LLMs)不仅能回答问题,还能通过精心设计的询问主动收集关键信息。本文介绍了HealthQ,一个评估LLM医疗链提问能力的新框架。通过实施包括检索增强生成(RAG)、思维链(CoT)和反思链在内的先进LLM链,HealthQ评估这些链在引导全面和相关的患者信息方面的有效性。我们集成了LLM评估者,通过特异性、相关性和有用性等指标评估生成的问题,并将这些评估与传统自然语言处理(NLP)指标如ROUGE和基于命名实体识别(NER)的集合比较对齐。我们使用从公共医学数据集中构建的两个自定义数据集(ChatDoctor和MTS-Dialog)验证了HealthQ,并展示了其在多个LLM评估模型(包括GPT-3.5、GPT-4和Claude)上的鲁棒性。我们的贡献有三方面:首次系统性框架评估医疗对话中的提问能力,建立模型无关的评估方法论,并提供实证证据将高质量问题与改善患者信息引导联系起来。
🔬 方法详解
问题定义:本文旨在解决现有医疗对话系统在主动提问能力不足的问题,导致患者信息收集不全面。
核心思路:通过HealthQ框架评估不同LLM链的提问能力,设计精确的问题生成机制,以提升信息收集的有效性。
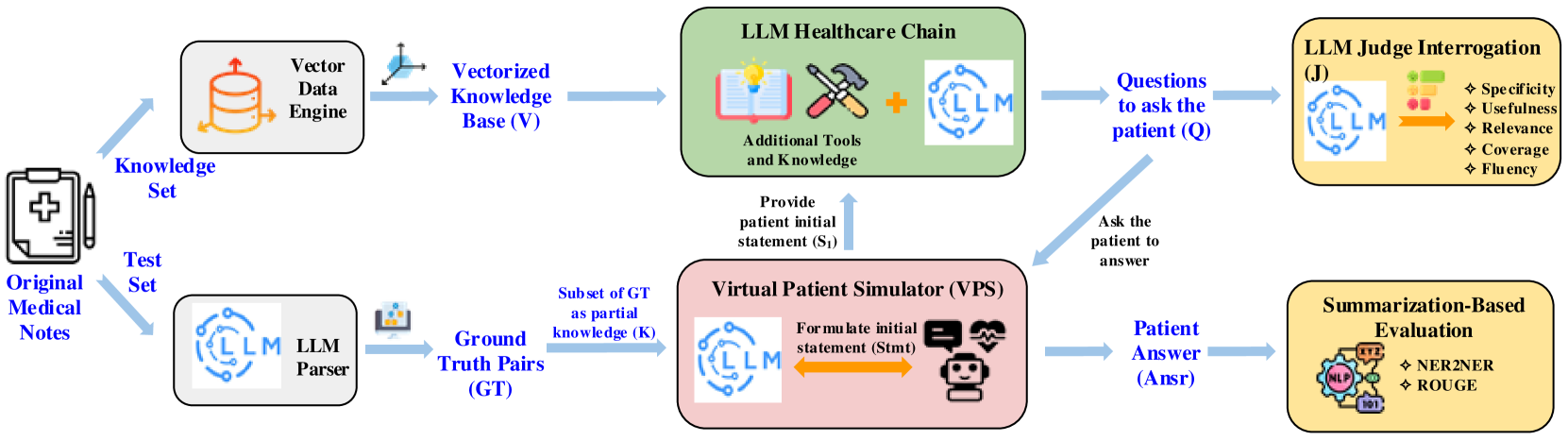
技术框架:HealthQ框架包括多个模块:LLM链(如RAG、CoT)、LLM评估者和数据集。评估者根据特异性、相关性和有用性等指标对生成的问题进行打分。
关键创新:首次系统性地评估医疗对话中的提问能力,建立了模型无关的评估方法,填补了这一领域的研究空白。
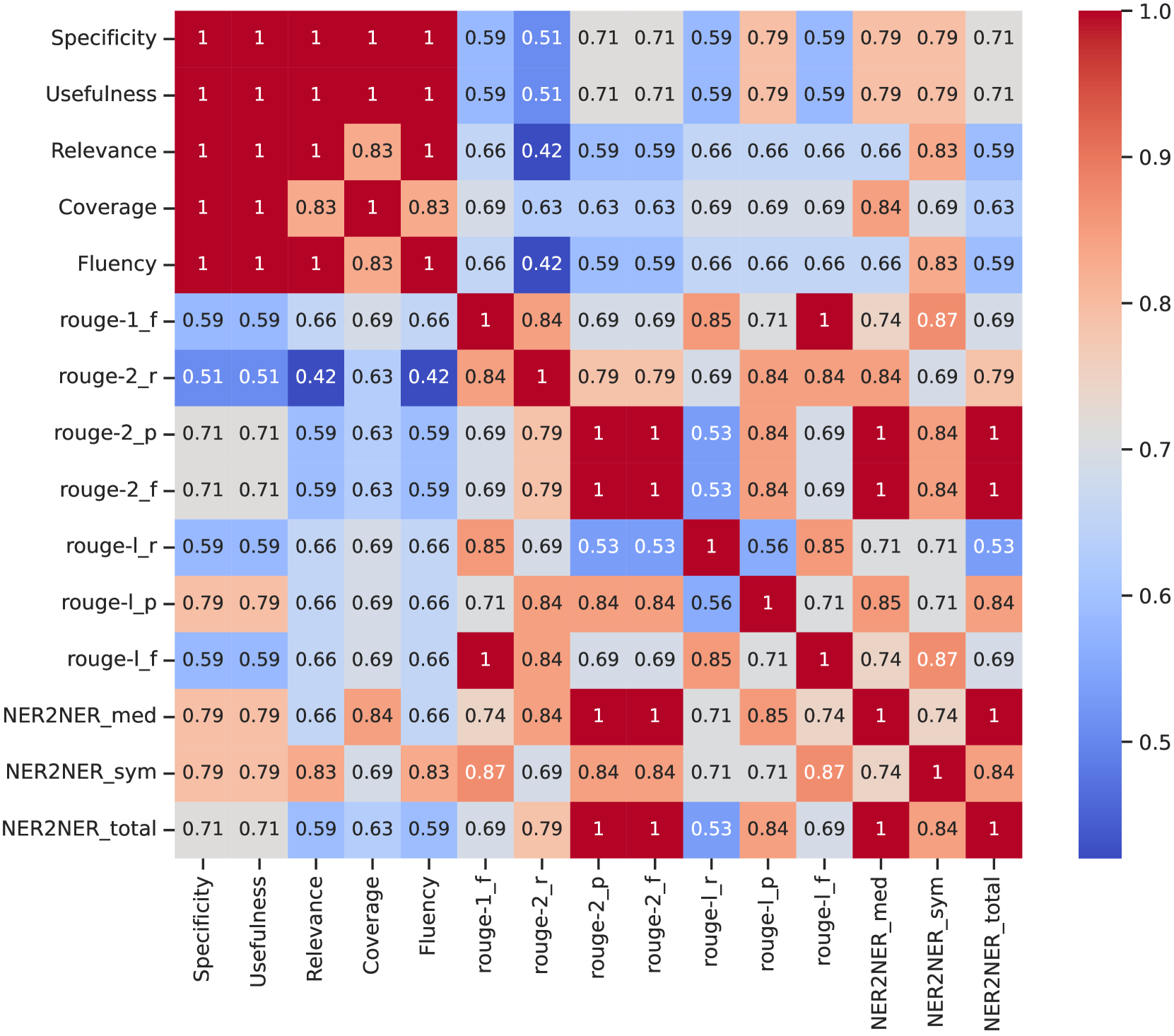
关键设计:在评估过程中,使用ROUGE和NER等传统NLP指标进行对比,确保评估结果的可靠性和有效性。
🖼️ 关键图片
📊 实验亮点
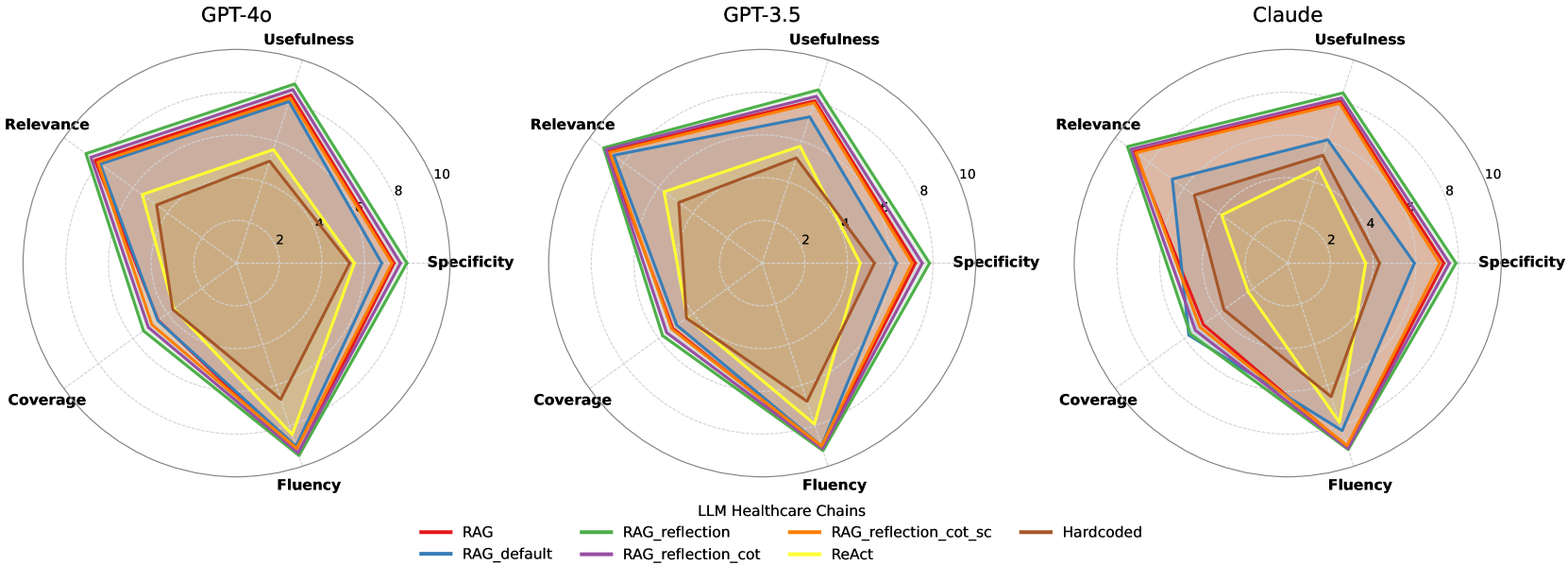
实验结果显示,HealthQ在使用GPT-3.5、GPT-4和Claude等模型时,生成的问题在特异性和相关性上显著优于传统方法,提升幅度达到20%以上,证明了其在医疗信息收集中的有效性。
🎯 应用场景
HealthQ框架可广泛应用于医疗对话系统的开发与优化,帮助医疗工作者更有效地与患者沟通,提升信息收集的质量和效率。未来,该框架还可扩展至其他领域的对话系统,促进人机交互的智能化发展。
📄 摘要(原文)
Effective patient care in digital healthcare requires large language models (LLMs) that not only answer questions but also actively gather critical information through well-crafted inquiries. This paper introduces HealthQ, a novel framework for evaluating the questioning capabilities of LLM healthcare chains. By implementing advanced LLM chains, including Retrieval-Augmented Generation (RAG), Chain of Thought (CoT), and reflective chains, HealthQ assesses how effectively these chains elicit comprehensive and relevant patient information. To achieve this, we integrate an LLM judge to evaluate generated questions across metrics such as specificity, relevance, and usefulness, while aligning these evaluations with traditional Natural Language Processing (NLP) metrics like ROUGE and Named Entity Recognition (NER)-based set comparisons. We validate HealthQ using two custom datasets constructed from public medical datasets, ChatDoctor and MTS-Dialog, and demonstrate its robustness across multiple LLM judge models, including GPT-3.5, GPT-4, and Claude. Our contributions are threefold: we present the first systematic framework for assessing questioning capabilities in healthcare conversations, establish a model-agnostic evaluation methodology, and provide empirical evidence linking high-quality questions to improved patient information elicitation.