INSIGHTBUDDY-AI: Medication Extraction and Entity Linking using Large Language Models and Ensemble Learning
作者: Pablo Romero, Lifeng Han, Goran Nenadic
分类: cs.CL, cs.AI
发布日期: 2024-09-28 (更新: 2024-12-27)
备注: ongoing work, 24 pages
🔗 代码/项目: GITHUB
💡 一句话要点
INSIGHTBUDDY-AI:利用大型语言模型和集成学习进行药物提取和实体链接
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 药物提取 实体链接 大型语言模型 集成学习 医疗NLP SNOMED-CT 文本挖掘
📋 核心要点
- 医疗领域的药物提取和挖掘至关重要,但现有方法在处理复杂医学文本时仍面临挑战。
- 该研究利用大型语言模型并结合集成学习,旨在提高药物及其属性提取的准确性和鲁棒性。
- 实验结果表明,集成的模型性能超越了单独微调的多个基线模型,并在实体链接方面取得了进展。
📝 摘要(中文)
本研究探讨了最先进的大型语言模型(LLMs)在药物文本挖掘任务中的应用,重点关注药物及其相关属性,如剂量、途径、强度和不良反应。此外,我们探索了不同的集成学习方法(Stack-Ensemble和Voting-Ensemble)以提升单个LLM模型的性能。集成学习结果表明,在通用和特定领域,其性能优于单独微调的基础模型BERT、RoBERTa、RoBERTa-L、BioBERT、BioClinicalBERT、BioMedRoBERTa、ClinicalBERT和PubMedBERT。最后,我们构建了一个实体链接功能,将提取的医学术语映射到SNOMED-CT代码和英国国家处方集(BNF)代码,这些代码进一步映射到药物和设备词典(dm+d)和ICD。我们的模型工具包和桌面应用程序已公开。
🔬 方法详解
问题定义:论文旨在解决医疗文本中药物及其相关属性(如剂量、途径、强度和不良反应)的自动提取和实体链接问题。现有方法,特别是基于传统机器学习的方法,在处理复杂的医学术语和上下文信息时表现不足,而直接使用预训练语言模型的效果也可能受限于领域知识的缺乏。
核心思路:论文的核心思路是利用大型语言模型(LLMs)强大的文本理解能力,并通过集成学习的方法进一步提升模型的性能和泛化能力。通过结合多个LLM的预测结果,可以有效降低单个模型的偏差,提高整体的鲁棒性。此外,论文还构建了实体链接功能,将提取的药物术语映射到标准医学知识库,实现知识的整合和应用。
技术框架:整体框架包括三个主要阶段:1) 基于大型语言模型的药物实体识别(NER),使用多个预训练的LLM(如BERT、RoBERTa及其医学领域变体)进行微调;2) 集成学习,采用Stack-Ensemble和Voting-Ensemble两种方法,将多个LLM的预测结果进行融合;3) 实体链接,将提取的药物实体映射到SNOMED-CT、BNF、dm+d和ICD等标准医学知识库。
关键创新:论文的关键创新在于将集成学习应用于药物实体识别任务,并结合了多个领域相关的预训练语言模型。通过Stack-Ensemble和Voting-Ensemble,有效地利用了不同模型的优势,提高了整体性能。此外,实体链接功能的构建实现了提取信息的标准化和知识整合,为后续应用奠定了基础。
关键设计:在集成学习方面,Stack-Ensemble使用一个元学习器(如逻辑回归)来学习如何组合不同基础模型的预测结果,而Voting-Ensemble则采用简单的投票机制。在实体链接方面,论文使用了基于字符串匹配和知识库查询的方法,将提取的药物实体映射到相应的标准代码。具体的参数设置和损失函数等技术细节在论文中未详细描述,可能使用了默认或常用的设置。
🖼️ 关键图片
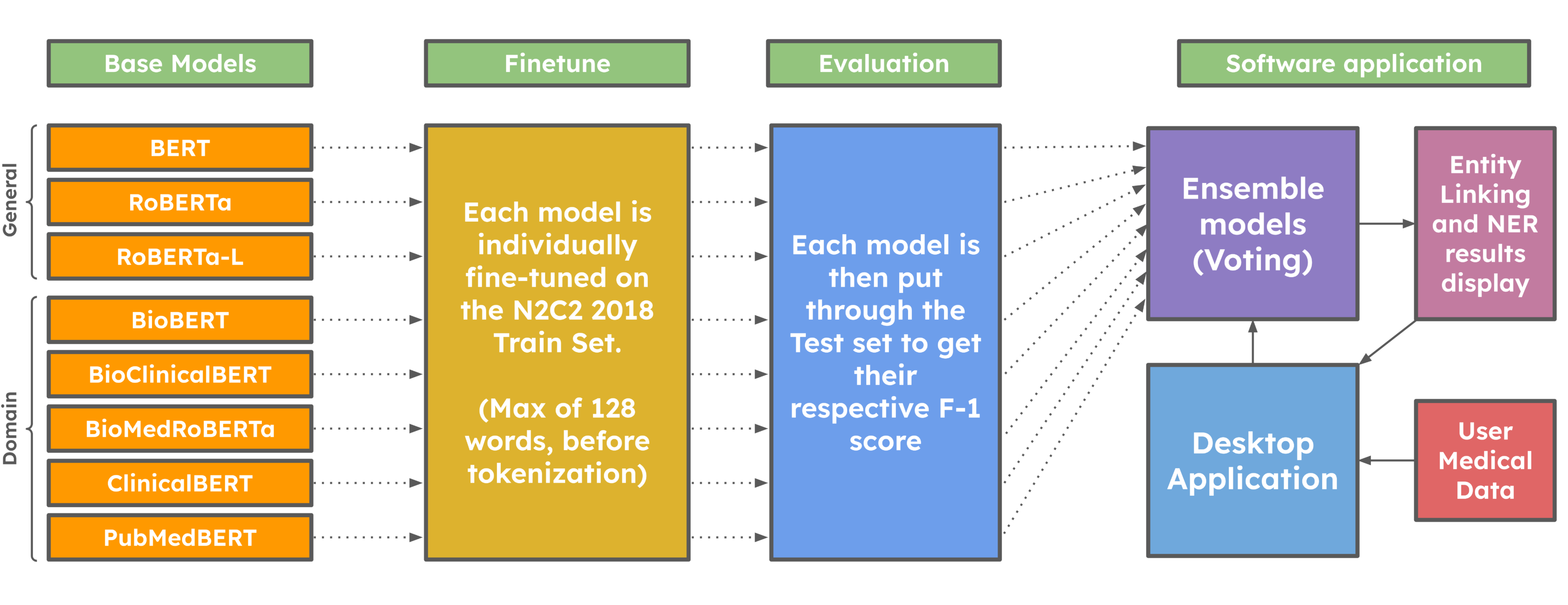


📊 实验亮点
实验结果表明,集成的模型在药物实体识别任务中取得了显著的性能提升,超越了单独微调的BERT、RoBERTa等多个基线模型。具体性能数据和提升幅度在摘要中未给出,但强调了集成学习的有效性。此外,实体链接功能的成功构建也为后续的知识整合和应用奠定了基础。
🎯 应用场景
该研究成果可应用于医院信息系统、药物警戒系统、临床决策支持系统等领域。通过自动提取和链接药物信息,可以提高医疗记录的准确性和完整性,辅助医生进行更精准的诊断和治疗,并促进药物安全监测和管理。未来,该技术有望进一步扩展到其他医疗领域的文本挖掘任务中。
📄 摘要(原文)
Medication Extraction and Mining play an important role in healthcare NLP research due to its practical applications in hospital settings, such as their mapping into standard clinical knowledge bases (SNOMED-CT, BNF, etc.). In this work, we investigate state-of-the-art LLMs in text mining tasks on medications and their related attributes such as dosage, route, strength, and adverse effects. In addition, we explore different ensemble learning methods (\textsc{Stack-Ensemble} and \textsc{Voting-Ensemble}) to augment the model performances from individual LLMs. Our ensemble learning result demonstrated better performances than individually fine-tuned base models BERT, RoBERTa, RoBERTa-L, BioBERT, BioClinicalBERT, BioMedRoBERTa, ClinicalBERT, and PubMedBERT across general and specific domains. Finally, we build up an entity linking function to map extracted medical terminologies into the SNOMED-CT codes and the British National Formulary (BNF) codes, which are further mapped to the Dictionary of Medicines and Devices (dm+d), and ICD. Our model's toolkit and desktop applications are publicly available (at \url{https://github.com/HECTA-UoM/ensemble-NER}).