Zero-Shot Multi-Hop Question Answering via Monte-Carlo Tree Search with Large Language Models
作者: Seongmin Lee, Jaewook Shin, Youngjin Ahn, Seokin Seo, Ohjoon Kwon, Kee-Eung Kim
分类: cs.CL
发布日期: 2024-09-28 (更新: 2024-10-01)
备注: Work in Progress
💡 一句话要点
提出基于蒙特卡洛树搜索的零样本多跳问答框架,提升复杂推理任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多跳问答 零样本学习 蒙特卡洛树搜索 大型语言模型 知识推理
📋 核心要点
- 多跳问答依赖多步推理,现有LLM自回归特性易导致中间步骤误差累积,影响最终答案准确性。
- 提出MZQA框架,利用蒙特卡洛树搜索寻找最优推理路径,缓解序列推理中的误差传播问题。
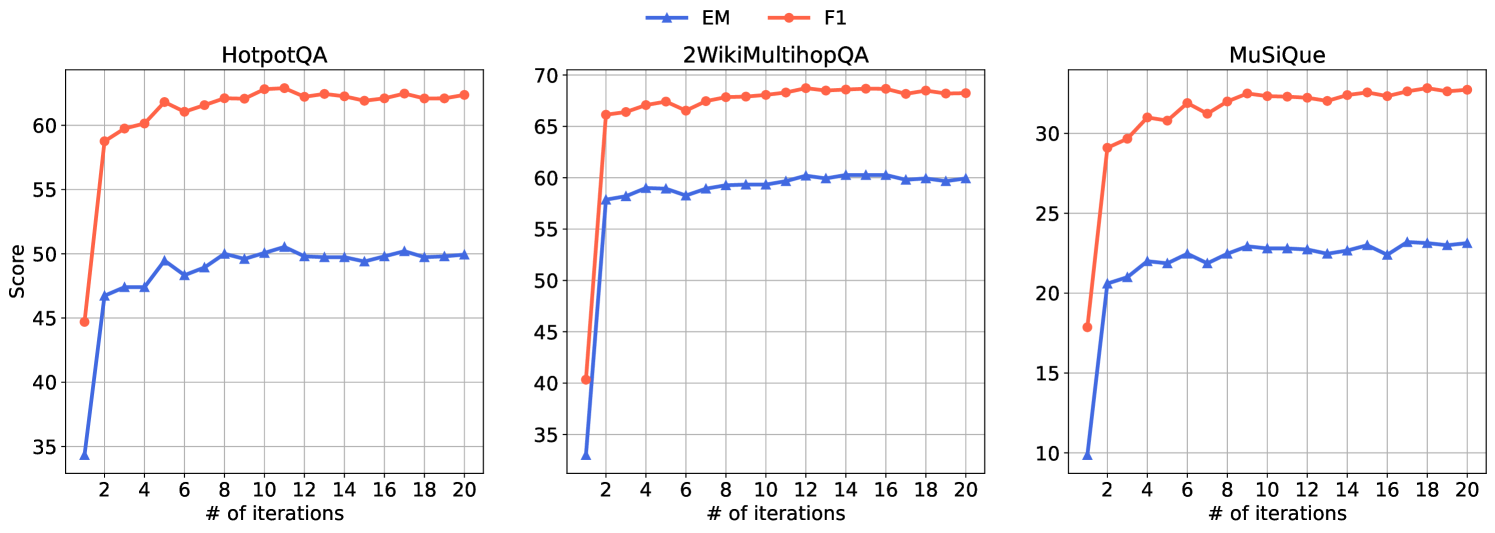
- 实验表明,MZQA在HotpotQA等基准测试中优于现有方法,并通过行为克隆提升推理速度。
📝 摘要(中文)
大型语言模型(LLMs)的最新进展显著影响了多跳问答(MHQA)领域,该领域要求系统整合信息并从不同的文本片段中推断答案。然而,LLM的自回归特性带来了一个固有的挑战,即如果在中间推理步骤中出现错误,错误可能会累积。本文提出了一种基于蒙特卡洛树搜索的零样本多跳问答框架(MZQA),该框架基于蒙特卡洛树搜索(MCTS)来识别MHQA任务中的最优推理路径,从而减轻序列推理过程中的误差传播。与以往的工作不同,我们提出了一种零样本提示方法,该方法仅依赖于指令,而不需要通常需要领域专业知识的手工制作的少样本示例的支持。我们还引入了一种行为克隆方法(MZQA-BC),该方法在自生成的MCTS推理轨迹上进行训练,在性能几乎没有下降的情况下,推理速度提高了10倍以上。我们的方法在HotpotQA、2WikiMultihopQA和MuSiQue等标准基准上得到了验证,证明其优于现有的框架。
🔬 方法详解
问题定义:多跳问答(MHQA)任务需要模型从多个文档中提取信息并进行推理才能回答问题。现有的基于大型语言模型(LLM)的MHQA方法,由于LLM的自回归特性,容易在推理过程中积累错误,导致最终答案不准确。尤其是在零样本场景下,缺乏示例指导使得错误传播问题更加严重。
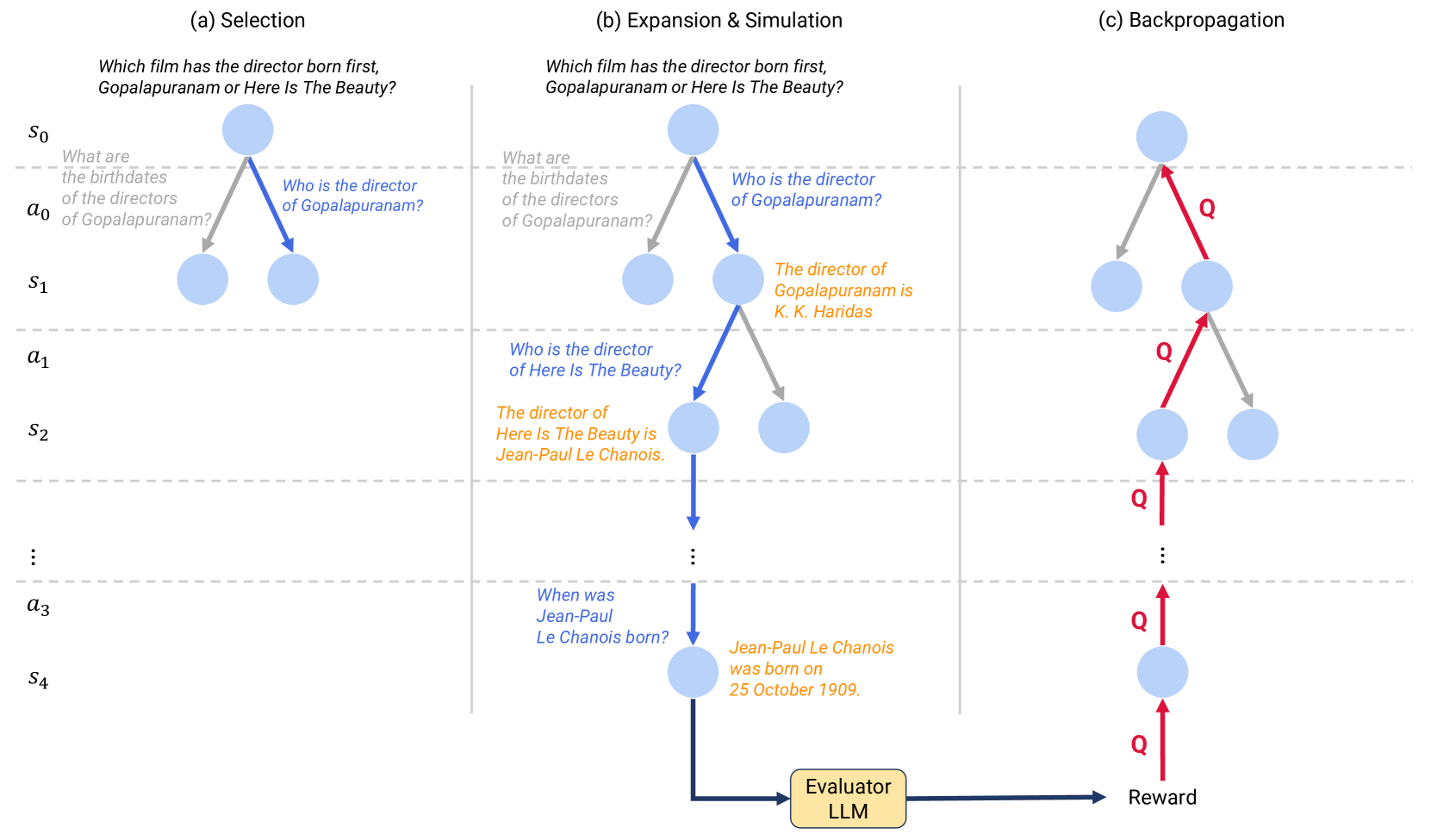
核心思路:本文的核心思路是利用蒙特卡洛树搜索(MCTS)来探索不同的推理路径,并选择最优的路径作为最终的答案。MCTS通过模拟多次推理过程,评估每条路径的潜在价值,从而避免了单一推理路径上的错误累积。这种方法类似于人类在解决复杂问题时,会尝试不同的思路并选择最合理的方案。
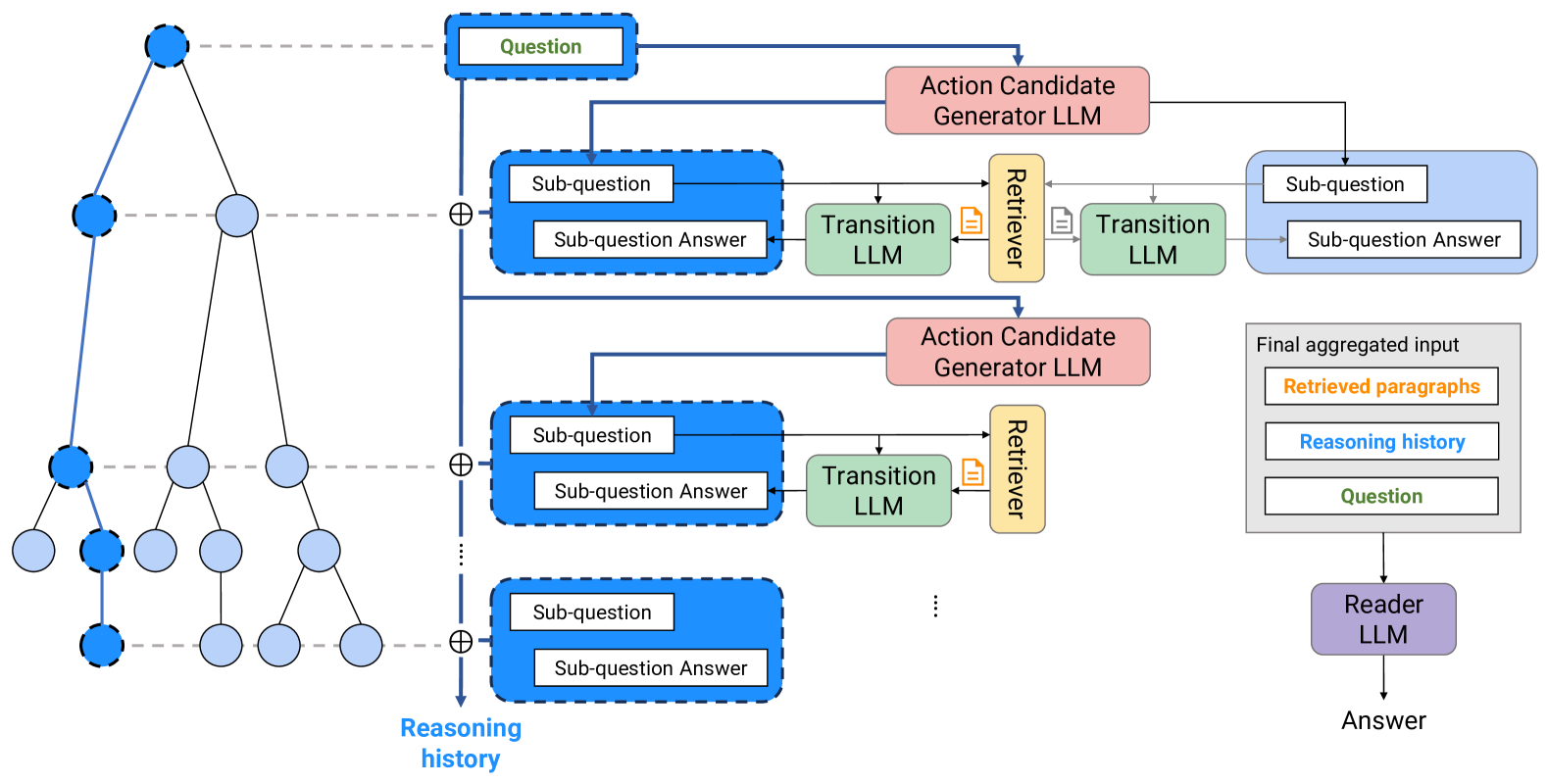
技术框架:MZQA框架主要包含以下几个阶段:1) 问题编码:将问题输入LLM,得到问题的向量表示。2) MCTS搜索:从根节点开始,每个节点代表一个中间推理状态。通过LLM生成可能的下一步推理步骤(例如,检索相关文档、进行逻辑推理等),并将其作为子节点扩展。MCTS通过模拟多次推理过程,评估每个节点的价值。3) 答案生成:当MCTS搜索达到一定深度或迭代次数后,选择价值最高的路径,并利用LLM生成最终答案。4) 行为克隆(MZQA-BC):使用MCTS生成的推理轨迹训练一个行为克隆模型,用于加速推理过程。
关键创新:本文的关键创新在于将MCTS引入到零样本多跳问答任务中。与以往依赖手工设计的少样本示例的方法不同,MZQA完全依赖于LLM的指令,无需领域专业知识。此外,通过行为克隆,可以在性能几乎没有下降的情况下,显著提高推理速度。
关键设计:MCTS的奖励函数是关键的设计之一。本文使用LLM对每个推理步骤的合理性进行评估,并将其作为奖励值。此外,MCTS的探索-利用平衡参数也需要仔细调整,以避免过早收敛到局部最优解。行为克隆模型的训练目标是最小化模型预测的动作与MCTS选择的动作之间的差异。
🖼️ 关键图片
📊 实验亮点
MZQA在HotpotQA、2WikiMultihopQA和MuSiQue等标准基准测试中取得了显著的性能提升,超越了现有的零样本多跳问答方法。特别是,通过行为克隆(MZQA-BC),在性能几乎没有下降的情况下,推理速度提高了10倍以上,使其更具实用性。
🎯 应用场景
该研究成果可应用于智能客服、知识图谱问答、自动报告生成等领域。通过提升复杂推理能力,可以帮助机器更好地理解人类问题,并提供更准确、更全面的答案。未来,该方法有望扩展到其他需要多步推理的任务中,例如代码生成、策略规划等。
📄 摘要(原文)
Recent advances in large language models (LLMs) have significantly impacted the domain of multi-hop question answering (MHQA), where systems are required to aggregate information and infer answers from disparate pieces of text. However, the autoregressive nature of LLMs inherently poses a challenge as errors may accumulate if mistakes are made in the intermediate reasoning steps. This paper introduces Monte-Carlo tree search for Zero-shot multi-hop Question Answering (MZQA), a framework based on Monte-Carlo tree search (MCTS) to identify optimal reasoning paths in MHQA tasks, mitigating the error propagation from sequential reasoning processes. Unlike previous works, we propose a zero-shot prompting method, which relies solely on instructions without the support of hand-crafted few-shot examples that typically require domain expertise. We also introduce a behavioral cloning approach (MZQA-BC) trained on self-generated MCTS inference trajectories, achieving an over 10-fold increase in reasoning speed with bare compromise in performance. The efficacy of our method is validated on standard benchmarks such as HotpotQA, 2WikiMultihopQA, and MuSiQue, demonstrating that it outperforms existing frameworks.