On the Power of Decision Trees in Auto-Regressive Language Modeling
作者: Yulu Gan, Tomer Galanti, Tomaso Poggio, Eran Malach
分类: cs.CL
发布日期: 2024-09-27
备注: Accepted to NeurIPS 2024
💡 一句话要点
探索自回归决策树在语言建模中的潜力,实现复杂函数计算与文本生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自回归决策树 语言建模 思维链 可解释性AI Transformer 推理任务 文本生成
📋 核心要点
- 现有语言模型架构同质化,缺乏多样性,本文旨在探索自回归决策树在语言建模中的潜力。
- 论文提出利用自回归决策树的“思维链”计算能力,使其能够模拟复杂函数,解决语言建模任务。
- 实验结果表明,ARDT在语言生成和复杂推理任务中表现出色,与小型Transformer模型性能相当。
📝 摘要(中文)
本文研究了自回归决策树(ARDT)在语言建模中的理论和实践应用。理论上,证明了ARDT可以通过利用“思维链”计算来模拟自动机、图灵机和稀疏电路等复杂函数,并分析了ARDT的大小、深度和计算效率的界限,突显了其强大的计算能力。实验上,在简单的语言生成任务上训练ARDT,表明它可以学习生成连贯且语法正确的文本,与较小的Transformer模型相当。此外,还展示了ARDT可以用于Transformer表示之上,以解决复杂的推理任务。这项研究揭示了ARDT独特的计算能力,旨在扩展语言模型开发中的架构多样性。
🔬 方法详解
问题定义:现有语言模型主要依赖Transformer等架构,计算复杂度高,模型参数量大。本文旨在探索一种更轻量级、更具可解释性的语言建模方法,并验证自回归决策树(ARDT)在处理语言任务方面的潜力。现有方法在处理复杂推理和长序列依赖时存在挑战。
核心思路:论文的核心思路是利用ARDT的决策树结构来模拟语言的生成过程,通过树的路径来表示“思维链”,从而实现对复杂逻辑和推理的建模。ARDT的自回归特性使其能够逐步生成文本,并根据之前的输出调整后续的生成策略。
技术框架:整体框架包括以下几个阶段:1) 数据预处理:将文本数据转换为适合ARDT训练的格式。2) ARDT模型训练:使用自回归的方式训练决策树,使其能够预测下一个词或token。3) 模型评估:在语言生成和推理任务上评估ARDT的性能。4) 与Transformer模型结合:将ARDT应用于Transformer的输出之上,以增强其推理能力。
关键创新:最重要的技术创新点在于将ARDT应用于语言建模领域,并证明了其在计算能力和可解释性方面的优势。与传统的神经网络模型相比,ARDT具有更强的可解释性,因为可以通过树的结构来理解模型的决策过程。此外,ARDT的计算复杂度较低,使其更适合于资源受限的场景。
关键设计:关键设计包括:1) 树的深度和宽度:需要根据任务的复杂程度进行调整。2) 分裂准则:选择合适的分裂准则(例如信息增益或基尼系数)来优化树的结构。3) 正则化方法:采用合适的正则化方法来防止过拟合。4) 与Transformer结合的方式:探索不同的结合方式,例如将ARDT作为Transformer的后处理模块或与Transformer进行联合训练。
🖼️ 关键图片
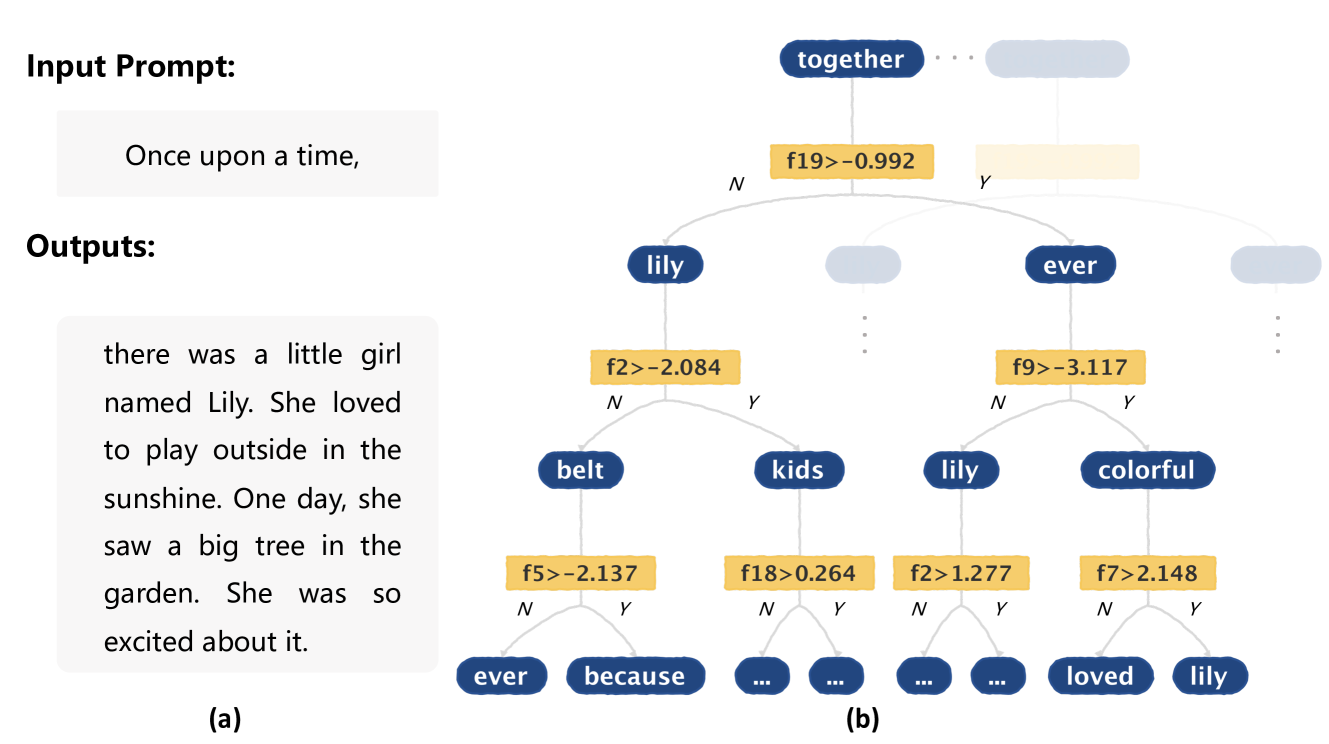


📊 实验亮点
实验结果表明,ARDT在简单的语言生成任务上可以达到与小型Transformer模型相当的性能。此外,ARDT与Transformer结合后,在复杂推理任务上取得了显著的提升,证明了ARDT在增强Transformer推理能力方面的潜力。具体性能数据和提升幅度在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于低资源语言建模、可解释性AI、以及需要快速推理和决策的场景,例如对话系统、智能助手和自动化报告生成。ARDT的轻量级特性使其在移动设备和嵌入式系统中具有潜在的应用价值,并为开发更高效、更可解释的语言模型提供了新的思路。
📄 摘要(原文)
Originally proposed for handling time series data, Auto-regressive Decision Trees (ARDTs) have not yet been explored for language modeling. This paper delves into both the theoretical and practical applications of ARDTs in this new context. We theoretically demonstrate that ARDTs can compute complex functions, such as simulating automata, Turing machines, and sparse circuits, by leveraging "chain-of-thought" computations. Our analysis provides bounds on the size, depth, and computational efficiency of ARDTs, highlighting their surprising computational power. Empirically, we train ARDTs on simple language generation tasks, showing that they can learn to generate coherent and grammatically correct text on par with a smaller Transformer model. Additionally, we show that ARDTs can be used on top of transformer representations to solve complex reasoning tasks. This research reveals the unique computational abilities of ARDTs, aiming to broaden the architectural diversity in language model development.