Model-based Preference Optimization in Abstractive Summarization without Human Feedback
作者: Jaepill Choi, Kyubyung Chae, Jiwoo Song, Yohan Jo, Taesup Kim
分类: cs.CL, cs.AI
发布日期: 2024-09-27 (更新: 2024-10-02)
备注: Accepted by EMNLP 2024
💡 一句话要点
提出基于模型偏好优化的无人工反馈摘要方法,提升摘要质量和忠实度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 抽象式摘要 偏好优化 无监督学习 大型语言模型 文本生成
📋 核心要点
- 现有摘要方法,特别是基于LLM的摘要,容易产生幻觉,引入不忠实于原文的内容。
- 论文提出Model-based Preference Optimization (MPO),利用模型自身能力生成偏好数据,无需人工干预。
- 实验表明,MPO在标准摘要数据集上显著提升了摘要质量,且无需人工反馈。
📝 摘要(中文)
在抽取式摘要中,生成简洁准确的摘要面临着源文档信息量巨大的挑战。大型语言模型(LLM)虽然能生成流畅的文本,但常因幻觉而引入原文中不存在的不准确内容。监督式微调虽然能最大化似然,但并不能持续提升摘要的忠实度。基于偏好的优化方法,如直接偏好优化(DPO),可以进一步优化模型以符合人类偏好,但仍然依赖昂贵的人工反馈。本文提出了一种新颖且直接的方法,称为基于模型偏好优化(MPO),无需任何人工反馈即可微调LLM,从而提高摘要能力。通过利用模型固有的摘要能力,我们创建了一个完全由模型使用不同解码策略生成的偏好数据集。在标准摘要数据集上的实验和各种指标表明,我们提出的MPO在不依赖人工反馈的情况下显著提高了生成摘要的质量。
🔬 方法详解
问题定义:论文旨在解决在抽象式摘要生成任务中,大型语言模型(LLM)容易产生幻觉,生成不忠实于原文内容的摘要的问题。现有的监督式微调方法虽然可以提高摘要的流畅性,但无法有效提升摘要的忠实度。而基于人类反馈的偏好优化方法,如DPO,虽然可以提升忠实度,但需要大量昂贵的人工标注数据。
核心思路:论文的核心思路是利用模型自身的能力来生成偏好数据,从而避免对人工标注数据的依赖。具体来说,通过使用不同的解码策略,让模型生成多个不同的摘要,然后利用模型自身对这些摘要进行排序,从而构建一个偏好数据集。然后,使用这个偏好数据集来微调模型,使其能够生成更符合模型自身偏好的摘要。
技术框架:MPO方法的整体框架包括以下几个步骤:1) 使用LLM对源文档生成多个摘要,每个摘要使用不同的解码策略(例如,不同的temperature或top-p采样)。2) 使用LLM对生成的摘要进行排序,得到一个偏好数据集,其中包含摘要对以及模型对这些摘要的偏好关系。3) 使用偏好数据集对LLM进行微调,目标是使模型生成的摘要更符合模型自身的偏好。
关键创新:MPO方法最重要的创新点在于它完全避免了对人工标注数据的依赖,而是利用模型自身的能力来生成偏好数据。这使得MPO方法可以更容易地应用于各种摘要任务,而无需担心人工标注数据的成本和质量。
关键设计:MPO的关键设计包括:1) 如何选择合适的解码策略来生成多样化的摘要。2) 如何设计排序算法来准确地评估摘要的质量。3) 如何设计损失函数来有效地利用偏好数据进行模型微调。论文中具体使用了不同的temperature和top-p采样策略来生成摘要,并使用模型自身的困惑度(perplexity)来评估摘要的质量。损失函数使用了标准的偏好优化损失函数,例如DPO损失函数。
🖼️ 关键图片
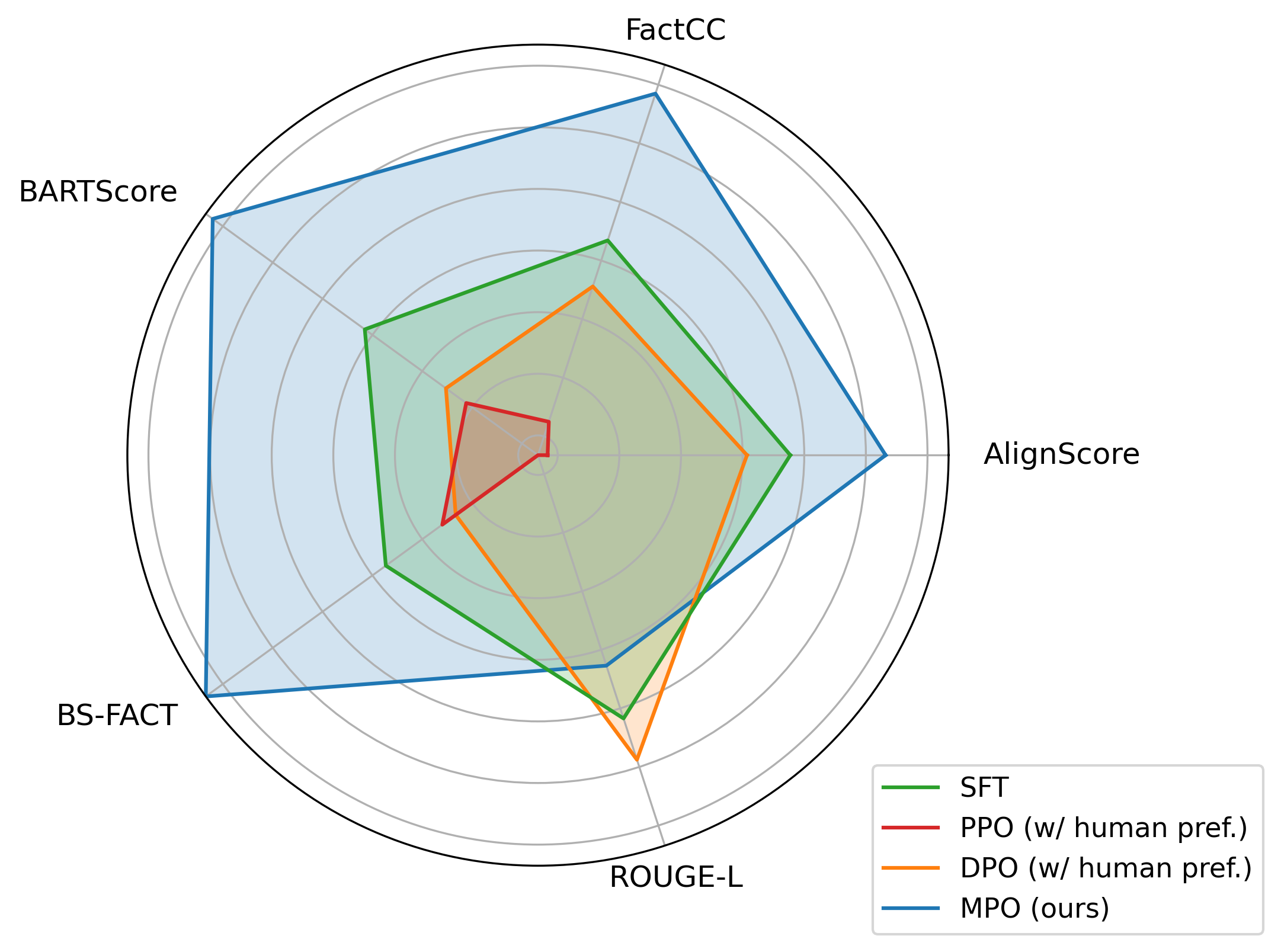


📊 实验亮点
实验结果表明,MPO在多个标准摘要数据集上显著提升了摘要质量,例如在CNN/DailyMail数据集上,ROUGE-1、ROUGE-2和ROUGE-L指标分别提升了1-2个百分点。更重要的是,MPO在不依赖任何人工反馈的情况下,达到了与使用人工反馈的DPO方法相媲美的性能。
🎯 应用场景
该研究成果可广泛应用于各种需要自动生成摘要的场景,例如新闻摘要、文档摘要、会议记录摘要等。它降低了对人工标注数据的依赖,使得在资源有限的情况下也能训练出高质量的摘要模型。未来,该方法可以进一步扩展到其他自然语言生成任务中,例如机器翻译、对话生成等。
📄 摘要(原文)
In abstractive summarization, the challenge of producing concise and accurate summaries arises from the vast amount of information contained in the source document. Consequently, although Large Language Models (LLMs) can generate fluent text, they often introduce inaccuracies by hallucinating content not found in the original source. While supervised fine-tuning methods that maximize likelihood contribute to this issue, they do not consistently enhance the faithfulness of the summaries. Preference-based optimization methods, such as Direct Preference Optimization (DPO), can further refine the model to align with human preferences. However, these methods still heavily depend on costly human feedback. In this work, we introduce a novel and straightforward approach called Model-based Preference Optimization (MPO) to fine-tune LLMs for improved summarization abilities without any human feedback. By leveraging the model's inherent summarization capabilities, we create a preference dataset that is fully generated by the model using different decoding strategies. Our experiments on standard summarization datasets and various metrics demonstrate that our proposed MPO significantly enhances the quality of generated summaries without relying on human feedback.