Hit the Sweet Spot! Span-Level Ensemble for Large Language Models
作者: Yangyifan Xu, Jianghao Chen, Junhong Wu, Jiajun Zhang
分类: cs.CL
发布日期: 2024-09-27
💡 一句话要点
提出SweetSpan:一种面向大语言模型的跨度级集成方法,提升生成质量和鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型集成 跨度级集成 困惑度 语言生成
📋 核心要点
- 现有token级集成方法因token信息有限,导致大语言模型生成过程中集成决策欠优。
- SweetSpan通过跨度级集成,平衡了实时调整的需求和准确集成决策所需的信息量。
- 实验表明,SweetSpan在标准和更具挑战性的设置下,均优于现有集成方法。
📝 摘要(中文)
本文提出了一种新的跨度级集成方法SweetSpan,旨在结合不同大语言模型的优势。现有集成方法主要分为样本级和token级。样本级集成在生成后选择或融合完整输出,无法在生成过程中动态修正。Token级集成虽然能实时修正,但单个token信息有限,导致决策欠优。SweetSpan通过让各模型基于共享前缀独立生成候选跨度,并利用困惑度进行互评估,从而实现稳健的跨度选择。此外,本文提出了一个更具挑战性的评估设置(集成性能差距大的模型),以更真实地评估集成方法的性能。实验结果表明,在标准和挑战性设置下,SweetSpan在各种语言生成任务中均优于现有方法,展现了其有效性、鲁棒性和通用性。
🔬 方法详解
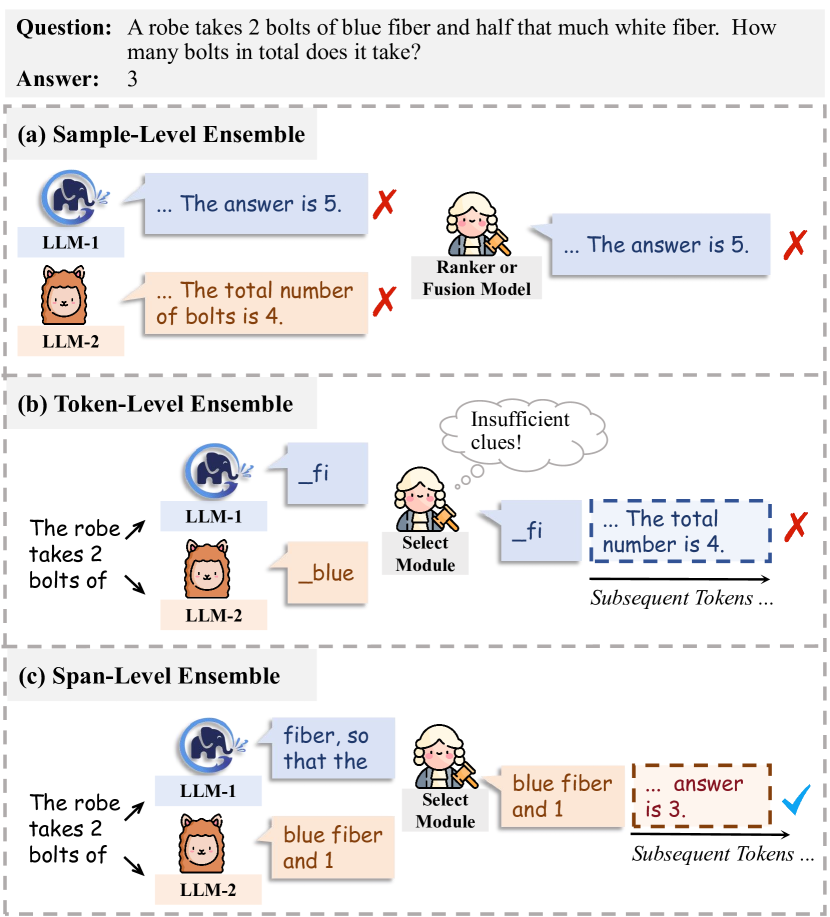
问题定义:现有的大语言模型集成方法,如token级集成,由于每个token携带的信息量有限,导致在生成过程中做出的集成决策不够理想,影响最终生成质量。样本级集成则无法在生成过程中进行动态调整。因此,需要一种能够在生成过程中进行实时调整,同时又能利用足够信息进行决策的集成方法。
核心思路:SweetSpan的核心思路是在跨度级别进行集成。每个模型基于共享的前缀独立生成候选跨度,然后通过互评估的方式选择最佳跨度。这种方法既能保证实时调整,又能利用跨度所包含的更丰富的信息进行更准确的决策。
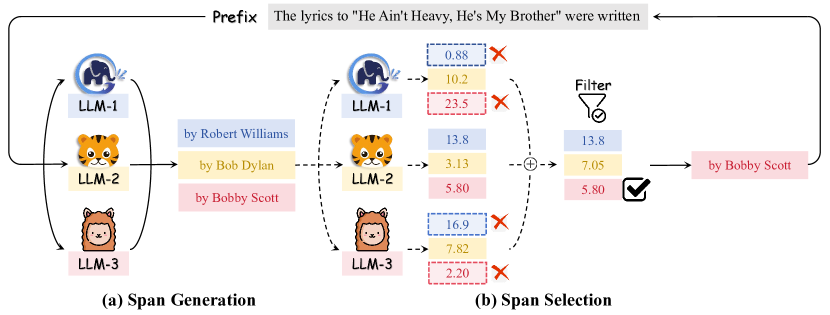
技术框架:SweetSpan主要包含两个阶段:1) 候选跨度生成阶段:每个候选模型基于共享的前缀独立生成多个候选跨度。2) 跨度选择阶段:计算各模型生成跨度的困惑度,进行互评估,并根据评估结果选择最佳跨度。具体来说,使用一个模型生成的跨度作为另一个模型的上下文,计算另一个模型在该上下文下的困惑度,困惑度越低,说明该跨度与另一个模型越一致,越可信。
关键创新:SweetSpan的关键创新在于提出了跨度级别的集成方法,并利用困惑度进行互评估。与token级集成相比,跨度包含更丰富的信息,有助于做出更准确的集成决策。与样本级集成相比,SweetSpan可以在生成过程中进行动态调整。困惑度互评估能够有效过滤掉不忠实的跨度,提高集成的鲁棒性。
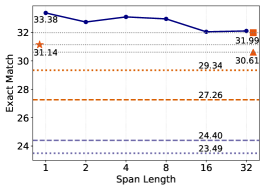
关键设计:在跨度生成阶段,可以设置生成跨度的长度范围。在跨度选择阶段,可以使用不同的策略来融合困惑度信息,例如,选择困惑度最低的跨度,或者根据困惑度进行加权平均。此外,论文还提出了一个新的评估设置,即集成性能差距较大的模型,以更真实地评估集成方法的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SweetSpan在各种语言生成任务中均优于现有的token级和样本级集成方法。在标准设置下,SweetSpan能够有效提升生成质量。在更具挑战性的设置下(集成性能差距大的模型),SweetSpan仍然表现出良好的鲁棒性,证明了其在实际应用中的潜力。具体性能提升数据未知,需查阅原文。
🎯 应用场景
SweetSpan可应用于各种语言生成任务,例如机器翻译、文本摘要、对话生成等。通过集成不同模型的优势,可以提高生成质量、鲁棒性和多样性。该方法尤其适用于需要高质量和可靠性的应用场景,例如智能客服、内容创作等。未来,可以将SweetSpan扩展到更多模态,例如图像和语音,以实现更强大的多模态生成能力。
📄 摘要(原文)
Ensembling various LLMs to unlock their complementary potential and leverage their individual strengths is highly valuable. Previous studies typically focus on two main paradigms: sample-level and token-level ensembles. Sample-level ensemble methods either select or blend fully generated outputs, which hinders dynamic correction and enhancement of outputs during the generation process. On the other hand, token-level ensemble methods enable real-time correction through fine-grained ensemble at each generation step. However, the information carried by an individual token is quite limited, leading to suboptimal decisions at each step. To address these issues, we propose SweetSpan, a span-level ensemble method that effectively balances the need for real-time adjustments and the information required for accurate ensemble decisions. Our approach involves two key steps: First, we have each candidate model independently generate candidate spans based on the shared prefix. Second, we calculate perplexity scores to facilitate mutual evaluation among the candidate models and achieve robust span selection by filtering out unfaithful scores. To comprehensively evaluate ensemble methods, we propose a new challenging setting (ensemble models with significant performance gaps) in addition to the standard setting (ensemble the best-performing models) to assess the performance of model ensembles in more realistic scenarios. Experimental results in both standard and challenging settings across various language generation tasks demonstrate the effectiveness, robustness, and versatility of our approach compared with previous ensemble methods.