Evaluation of Large Language Models for Summarization Tasks in the Medical Domain: A Narrative Review
作者: Emma Croxford, Yanjun Gao, Nicholas Pellegrino, Karen K. Wong, Graham Wills, Elliot First, Frank J. Liao, Cherodeep Goswami, Brian Patterson, Majid Afshar
分类: cs.CL, cs.AI
发布日期: 2024-09-26
💡 一句话要点
评估大型语言模型在医学领域摘要任务中的应用及挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 医学摘要 自然语言生成 临床应用 评估方法 叙述性回顾 医疗信息管理
📋 核心要点
- 医学文本量巨大,利用大型语言模型进行自动摘要具有潜力,但医学领域的特殊性对模型提出了更高的可靠性要求。
- 该综述旨在评估当前大型语言模型在临床摘要任务中的评估方法,并探讨如何克服专家人工评估的资源限制。
- 文章通过叙述性回顾的方式,分析了现有评估方法的优缺点,并为未来的研究方向提供了建议。
📝 摘要(中文)
大型语言模型在临床自然语言生成方面取得了显著进展,为管理大量的医学文本创造了机会。然而,医学领域的高风险性要求对模型进行可靠的评估,而这仍然是一个挑战。本综述评估了当前临床摘要任务的评估现状,并提出了未来方向,以解决专家人工评估的资源约束问题。
🔬 方法详解
问题定义:论文关注的是如何可靠地评估大型语言模型在医学领域摘要任务中的表现。现有方法,特别是依赖专家人工评估的方法,面临着成本高昂、耗时长的挑战,难以满足实际需求。因此,需要探索更高效、更经济的评估策略。
核心思路:论文的核心思路是通过叙述性回顾,系统性地分析当前用于评估大型语言模型在医学摘要任务中的各种方法,识别它们的优势和局限性,并在此基础上提出未来研究方向的建议,旨在降低对专家人工评估的依赖。
技术框架:该论文采用叙述性回顾的方式,没有提出新的模型或算法。其框架主要包括:1) 确定评估目标:明确医学摘要任务的评估重点;2) 收集文献:系统性地搜索和筛选相关研究;3) 分析评估方法:深入分析现有评估方法的原理、优缺点和适用场景;4) 提出未来方向:基于分析结果,提出改进评估方法的建议。
关键创新:该论文的创新之处在于,它并非提出一种新的模型或算法,而是专注于对现有评估方法进行系统性的分析和总结,为未来的研究方向提供指导。这种研究思路对于推动医学领域自然语言处理的实际应用具有重要意义。
关键设计:由于是叙述性回顾,没有涉及具体的参数设置、损失函数或网络结构等技术细节。关键在于文献的选择和分析,需要保证文献的代表性和分析的深度。
🖼️ 关键图片
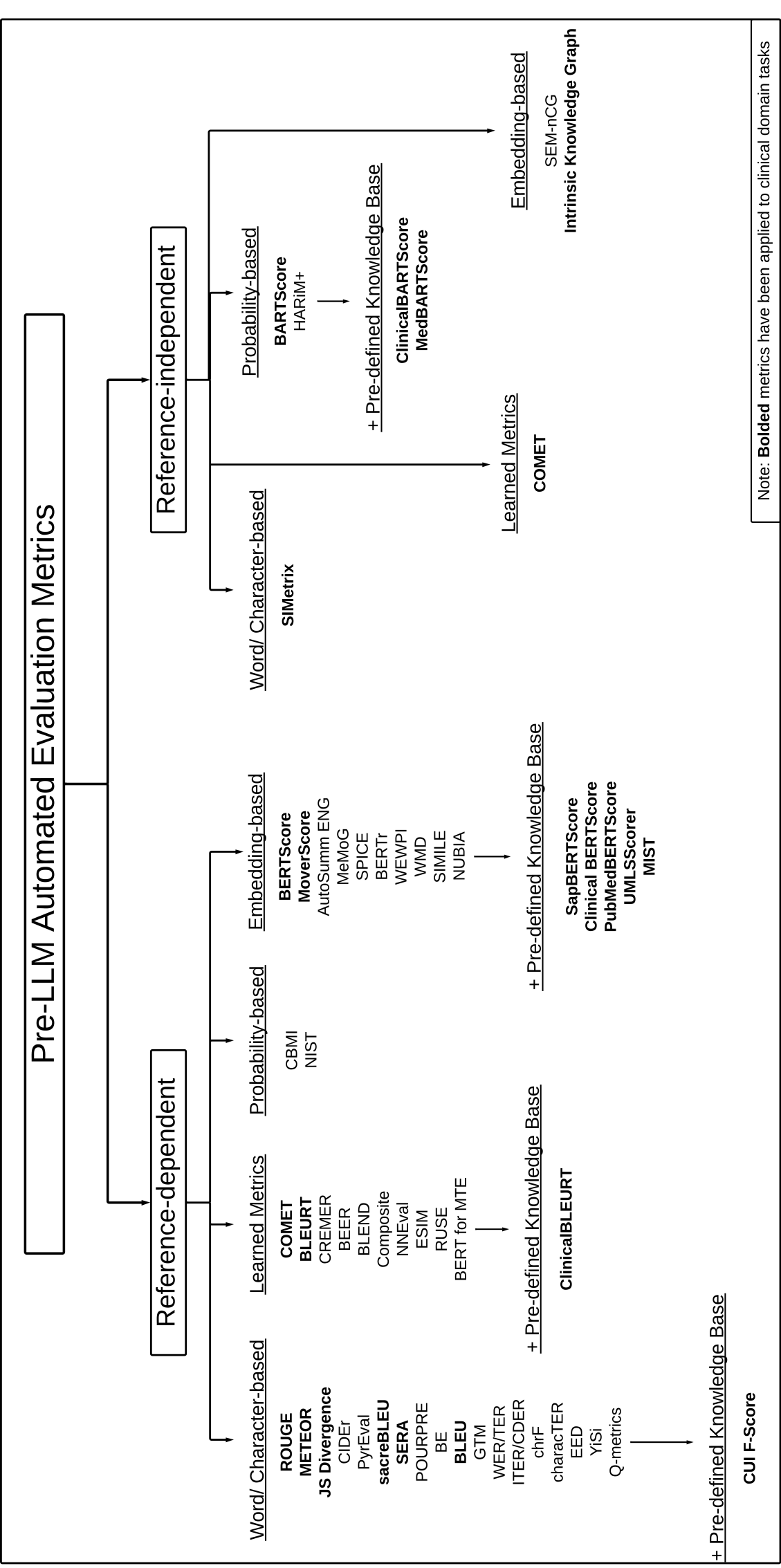
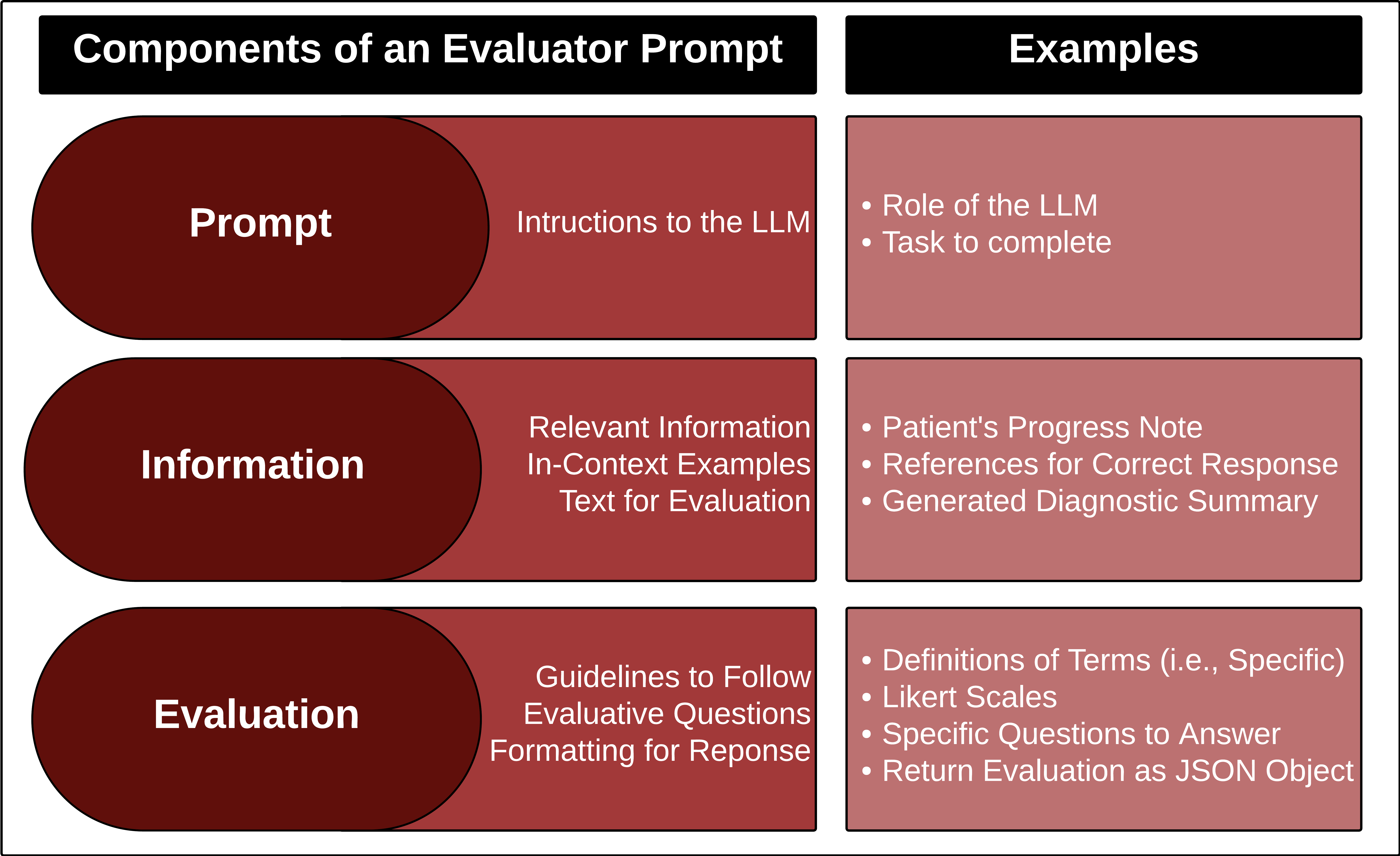
📊 实验亮点
该论文是一篇综述性文章,没有具体的实验结果。其亮点在于对现有评估方法进行了系统性的分析,并提出了未来研究方向的建议,例如探索更有效的自动评估指标、利用弱监督学习降低人工标注成本等。
🎯 应用场景
该研究成果可应用于医疗信息管理、临床决策支持、医学研究等领域。通过更可靠的自动摘要技术,医生可以快速获取关键信息,提高工作效率,辅助诊断和治疗。此外,高质量的医学摘要也有助于患者更好地理解病情和治疗方案。
📄 摘要(原文)
Large Language Models have advanced clinical Natural Language Generation, creating opportunities to manage the volume of medical text. However, the high-stakes nature of medicine requires reliable evaluation, which remains a challenge. In this narrative review, we assess the current evaluation state for clinical summarization tasks and propose future directions to address the resource constraints of expert human evaluation.