Extracting Affect Aggregates from Longitudinal Social Media Data with Temporal Adapters for Large Language Models
作者: Georg Ahnert, Max Pellert, David Garcia, Markus Strohmaier
分类: cs.CY, cs.CL
发布日期: 2024-09-26 (更新: 2025-01-09)
期刊: Proceedings of the Nineteenth International AAAI Conference on Web and Social Media (2025)
DOI: 10.1609/icwsm.v19i1.35801
💡 一句话要点
提出基于时间适配器的大语言模型,用于从纵向社交媒体数据中提取情感聚合信息。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 纵向分析 社交媒体数据 情感分析 大语言模型 时间适配器 Llama 3 舆情监测
📋 核心要点
- 现有方法难以有效分析社交媒体数据中的情感随时间变化趋势,缺乏对时间信息的有效建模。
- 本文提出使用时间适配器微调大语言模型,使其能够捕捉社交媒体数据中的时间依赖关系,从而进行纵向情感分析。
- 实验表明,该方法在估计集体情绪方面与英国调查数据高度相关,且在不同训练设置和提示下具有鲁棒性。
📝 摘要(中文)
本文提出了一种时间对齐的大语言模型(LLM),作为纵向分析社交媒体数据的工具。我们针对Llama 3 8B微调了时间适配器,使用了来自英国Twitter用户面板的完整时间线数据,并使用已建立的问卷调查提取了情感和态度的纵向聚合信息。我们的分析重点是COVID-19疫情初期,该疫情对公众舆论和集体情绪产生了强烈影响。我们将估计结果与具有代表性的英国调查数据进行验证,发现几种集体情绪之间存在显著的正相关关系。获得的估计结果在多个训练种子和提示公式中均具有鲁棒性,并且与使用在标记数据上训练的传统分类模型提取的集体情绪一致。我们还在没有预训练分类器可用的公众舆论问题上展示了该方法的灵活性。我们的工作通过时间适配器将LLM中的情感分析扩展到纵向设置,从而为社交媒体数据的纵向分析提供了灵活的新方法。
🔬 方法详解
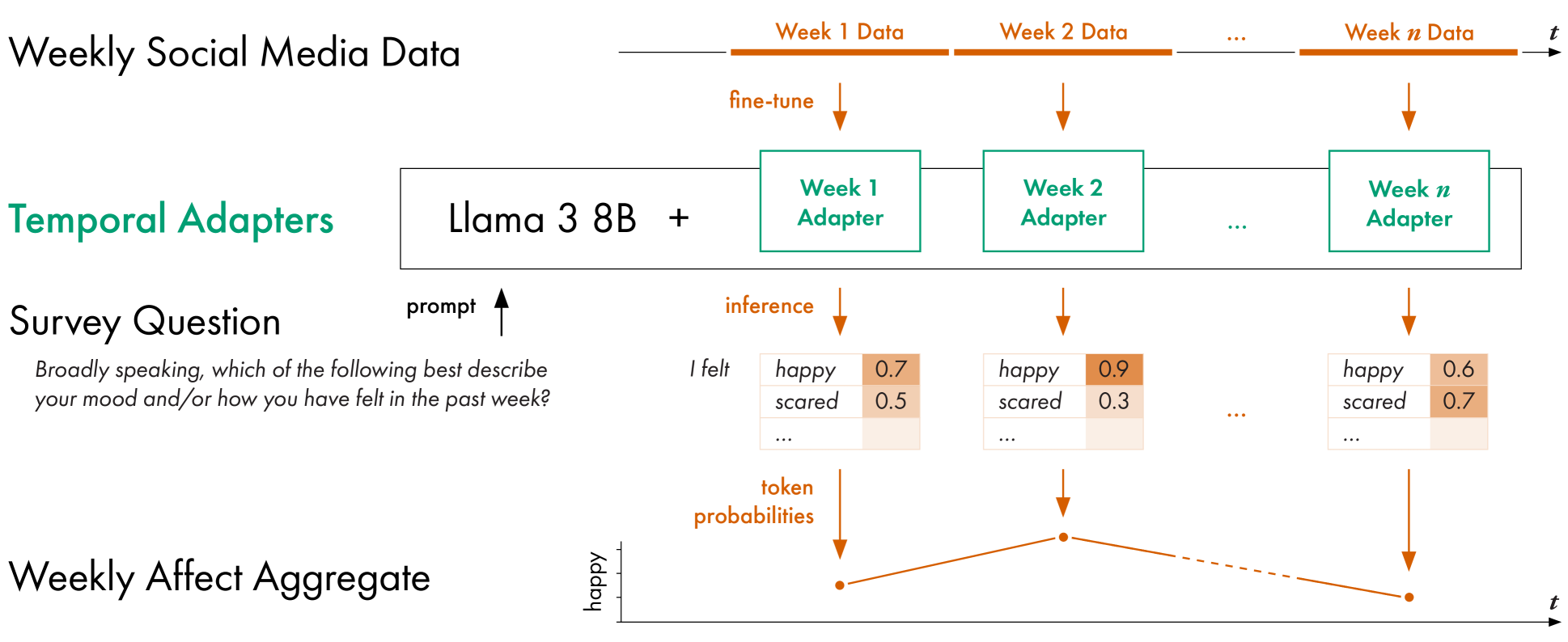
问题定义:本文旨在解决如何从纵向社交媒体数据中准确提取情感聚合信息的问题。现有方法,如传统的分类模型,通常需要大量标注数据,且难以适应不断变化的社会环境和公众舆论。此外,这些方法缺乏对时间信息的有效建模,难以捕捉情感随时间演变的趋势。
核心思路:本文的核心思路是利用大语言模型(LLM)强大的语义理解能力,并通过时间适配器(Temporal Adapters)对其进行微调,使其能够理解和处理时间序列数据。通过这种方式,模型可以学习到情感随时间变化的模式,从而更准确地提取情感聚合信息。
技术框架:该方法的技术框架主要包括以下几个步骤:1) 数据准备:收集纵向社交媒体数据,例如来自Twitter用户的时间线数据。2) 模型选择:选择一个预训练的大语言模型,例如Llama 3 8B。3) 时间适配器:在LLM中添加时间适配器模块,用于捕捉时间依赖关系。4) 模型微调:使用纵向社交媒体数据对LLM和时间适配器进行微调。5) 情感提取:使用微调后的模型提取情感聚合信息,例如情感得分或情感类别。6) 结果验证:将提取的情感聚合信息与外部数据(例如调查数据)进行比较,以验证模型的准确性。
关键创新:本文的关键创新在于提出了使用时间适配器来增强LLM对时间序列数据的处理能力。与直接微调整个LLM相比,时间适配器只需要训练少量参数,从而降低了计算成本和数据需求。此外,时间适配器可以灵活地插入到LLM的不同层中,以捕捉不同层次的时间依赖关系。
关键设计:时间适配器通常由几个全连接层组成,用于将时间信息编码到LLM的隐藏状态中。在训练过程中,可以使用各种损失函数来优化模型,例如交叉熵损失或均方误差损失。此外,可以使用不同的提示工程技术来引导LLM提取特定的情感信息。例如,可以使用包含情感关键词的提示来鼓励模型关注与情感相关的文本内容。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在估计集体情绪方面与代表性的英国调查数据之间存在显著的正相关关系。此外,该方法在多个训练种子和提示公式中均表现出鲁棒性。与使用传统分类模型提取的集体情绪相比,该方法的结果也具有一致性。这些结果表明,该方法能够有效地从纵向社交媒体数据中提取情感聚合信息。
🎯 应用场景
该研究成果可应用于舆情监测、公共卫生事件分析、市场调研等领域。通过分析社交媒体数据中的情感变化,可以及时了解公众情绪,为政府决策、企业战略制定提供参考。此外,该方法还可以用于预测社会事件的发生,例如预测疫情爆发、经济危机等。
📄 摘要(原文)
This paper proposes temporally aligned Large Language Models (LLMs) as a tool for longitudinal analysis of social media data. We fine-tune Temporal Adapters for Llama 3 8B on full timelines from a panel of British Twitter users, and extract longitudinal aggregates of emotions and attitudes with established questionnaires. We focus our analysis on the beginning of the COVID-19 pandemic that had a strong impact on public opinion and collective emotions. We validate our estimates against representative British survey data and find strong positive, significant correlations for several collective emotions. The obtained estimates are robust across multiple training seeds and prompt formulations, and in line with collective emotions extracted using a traditional classification model trained on labeled data. We demonstrate the flexibility of our method on questions of public opinion for which no pre-trained classifier is available. Our work extends the analysis of affect in LLMs to a longitudinal setting through Temporal Adapters. It enables flexible, new approaches towards the longitudinal analysis of social media data.