EMMA-500: Enhancing Massively Multilingual Adaptation of Large Language Models
作者: Shaoxiong Ji, Zihao Li, Jaakko Paavola, Peiqin Lin, Pinzhen Chen, Dayyán O'Brien, Hengyu Luo, Hinrich Schütze, Jörg Tiedemann, Barry Haddow
分类: cs.CL
发布日期: 2024-09-26 (更新: 2025-12-04)
💡 一句话要点
EMMA-500:增强大规模多语言LLM适应性,提升低资源语言覆盖
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言模型 低资源语言 持续预训练 语言适应 跨语言迁移
📋 核心要点
- 现有大型语言模型在低资源语言上的表现不足,限制了其多语言应用。
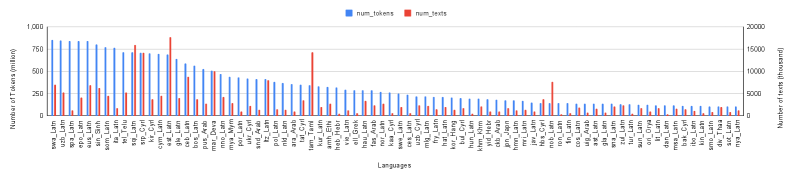
- 通过构建包含546种语言的MaLA语料库,并对Llama 2 7B进行持续预训练,提升模型的多语言能力。
- EMMA-500在多语言基准测试中表现出色,尤其在低资源语言上,显著提升了跨语言迁移和泛化能力。
📝 摘要(中文)
本文介绍了EMMA-500,一个大规模多语言语言模型,它在546种语言的文本上进行了持续训练,旨在增强多语言性能,特别关注于提高低资源语言的覆盖率。为了促进持续预训练,我们构建了MaLA语料库,这是一个全面的多语言数据集,其中包含了来自不同领域的精选数据集。我们利用这个语料库,对Llama 2 7B模型进行了广泛的持续预训练,从而得到了EMMA-500。EMMA-500在一系列基准测试中表现出强大的性能,包括一套全面的多语言任务。我们的结果突出了持续预训练在扩展大型语言模型的语言能力方面的有效性,尤其是在代表性不足的语言方面,并在跨语言迁移、任务泛化和语言适应性方面表现出显著的提升。我们发布了MaLA语料库、EMMA-500模型权重、脚本和模型生成结果。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在处理低资源语言时表现不佳,这主要是由于训练数据不足导致的。这限制了LLM在全球范围内的应用,并可能加剧语言之间的数字鸿沟。因此,如何有效地提升LLM在低资源语言上的性能是一个重要的研究问题。
核心思路:本文的核心思路是通过持续预训练的方式,利用一个包含大量多语言数据的语料库(MaLA)来增强LLM的语言覆盖能力,特别是对于低资源语言。持续预训练允许模型在已有的知识基础上学习新的语言知识,从而更有效地适应新的语言。
技术框架:EMMA-500的训练框架主要包含以下几个阶段:1) 构建MaLA语料库,该语料库包含546种语言的文本数据,涵盖多个领域。2) 选择Llama 2 7B作为基础模型。3) 使用MaLA语料库对Llama 2 7B进行持续预训练,得到EMMA-500模型。4) 在一系列多语言基准测试中评估EMMA-500的性能。
关键创新:该论文的关键创新在于:1) 构建了一个大规模、多领域、多语言的MaLA语料库,为LLM的持续预训练提供了丰富的数据资源。2) 通过持续预训练的方式,有效地提升了LLM在低资源语言上的性能,而无需从头开始训练模型。
关键设计:MaLA语料库的构建过程中,作者精心挑选了来自不同领域的文本数据,以确保语料库的多样性和代表性。在持续预训练过程中,作者可能采用了特定的学习率策略和正则化方法,以防止模型在预训练过程中出现过拟合现象。具体的参数设置和损失函数细节在论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片
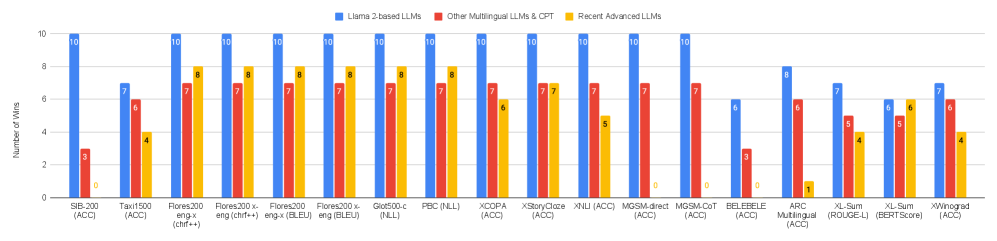

📊 实验亮点
EMMA-500在多语言基准测试中表现出强大的性能,尤其是在低资源语言上。实验结果表明,EMMA-500在跨语言迁移、任务泛化和语言适应性方面都取得了显著的提升。具体的性能数据和对比基线在论文中应该有详细的呈现,但在此处摘要中未明确提及。
🎯 应用场景
EMMA-500的潜在应用领域包括:多语言机器翻译、跨语言信息检索、多语言内容生成、以及面向全球用户的智能助手等。该研究的实际价值在于提升了LLM在低资源语言上的性能,从而使得更多的人能够受益于人工智能技术。未来,EMMA-500可以被进一步应用于开发面向特定语言或文化群体的定制化AI应用。
📄 摘要(原文)
In this work, we introduce EMMA-500, a large-scale multilingual language model continue-trained on texts across 546 languages designed for enhanced multilingual performance, focusing on improving language coverage for low-resource languages. To facilitate continual pre-training, we compile the MaLA corpus, a comprehensive multilingual dataset enriched with curated datasets across diverse domains. Leveraging this corpus, we conduct extensive continual pre-training of the Llama 2 7B model, resulting in EMMA-500, which demonstrates robust performance across a wide collection of benchmarks, including a comprehensive set of multilingual tasks. Our results highlight the effectiveness of continual pre-training in expanding large language models' language capacity, particularly for underrepresented languages, demonstrating significant gains in cross-lingual transfer, task generalization, and language adaptability. We release the MaLA corpus, EMMA-500 model weights, scripts, and model generations.