PEDRO: Parameter-Efficient Fine-tuning with Prompt DEpenDent Representation MOdification
作者: Tianfang Xie, Tianjing Li, Wei Zhu, Wei Han, Yi Zhao
分类: cs.CL
发布日期: 2024-09-26
备注: arXiv admin note: text overlap with arXiv:2405.18203
💡 一句话要点
提出PEDRO以解决大语言模型的高效微调问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 参数高效微调 Transformer 向量生成 多租户部署 推理效率 语义输出 深度学习
📋 核心要点
- 现有的PEFT方法在推理效率和下游任务性能之间存在权衡,难以满足实际应用需求。
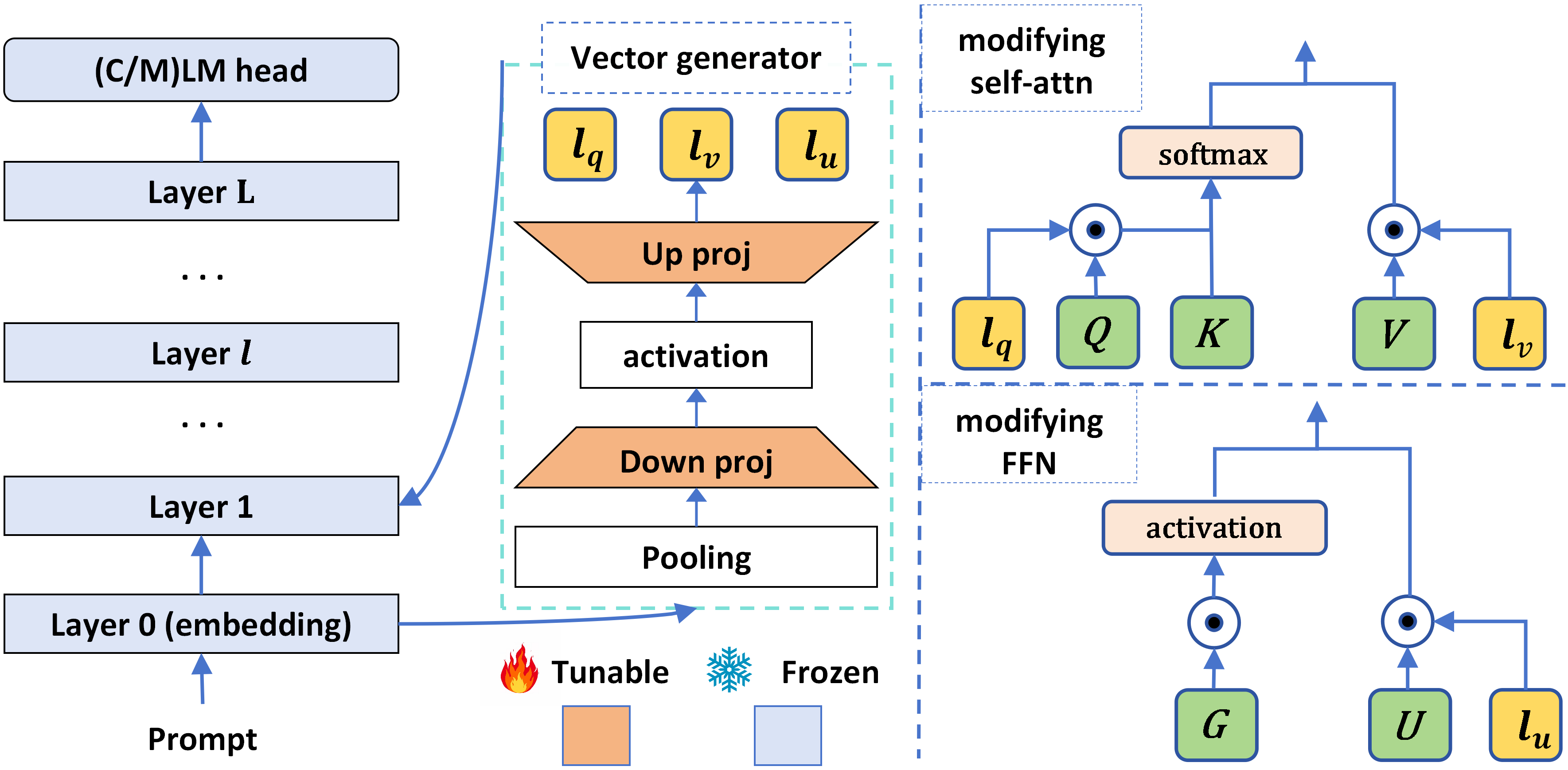
- PEDRO通过在Transformer层中集成轻量级向量生成器,依据输入提示动态调整隐藏表示,提升了微调效率。
- 实验结果表明,PEDRO在多个任务上超越了LoRA等基准,展示了更高的推理效率和竞争力的性能。
📝 摘要(中文)
由于大语言模型(LLMs)的规模庞大,通常在单一骨干多租户框架中部署。此框架下,单个LLM骨干必须通过多种参数高效微调(PEFT)模型来满足多个用户或任务的需求。尽管已有多种有效的PEFT技术,如LoRA,但仍需一种在推理时高效且在下游任务上表现竞争力的PEFT方法。本文提出了一种新颖且简单的PEFT方法,称为Prompt Dependent Representation Modification(PEDRO)。该方法在每个Transformer层中集成了轻量级向量生成器,根据输入提示生成向量,进而通过点积操作修改LLM生成的隐藏表示,影响模型的语义输出和生成内容。大量实验表明,PEDRO在使用相似可调参数的情况下超越了近期PEFT基准,并在单一骨干多租户部署模型下展现出优于LoRA的效率,具有显著的工业潜力。
🔬 方法详解
问题定义:本文旨在解决大语言模型在多租户环境下的高效微调问题。现有方法如LoRA在推理效率和性能之间存在矛盾,难以满足实际应用的需求。
核心思路:PEDRO的核心思路是通过在每个Transformer层中集成一个轻量级的向量生成器,依据输入提示生成动态向量,从而修改隐藏表示。这种设计使得模型能够更灵活地适应不同任务的需求。
技术框架:PEDRO的整体架构包括多个Transformer层,每层都配备了向量生成器。输入提示经过处理后,生成的向量通过点积操作与隐藏表示结合,最终影响模型的输出。
关键创新:PEDRO的主要创新在于其动态生成的向量能够根据具体任务调整隐藏表示,这与传统的静态微调方法形成了鲜明对比,显著提升了模型的适应性和效率。
关键设计:PEDRO在参数设置上保持轻量化,向量生成器的设计确保了在不显著增加计算负担的情况下,能够有效地调整模型的输出。此外,损失函数的选择也经过精心设计,以确保模型在不同任务上的性能优化。
🖼️ 关键图片

📊 实验亮点
在多个任务的实验中,PEDRO在使用相似数量的可调参数时,超越了LoRA等现有PEFT基准,展现出更高的推理效率和竞争力的性能,表明其在工业应用中的巨大潜力。
🎯 应用场景
PEDRO方法在多租户环境下的高效微调具有广泛的应用潜力,特别是在需要快速响应不同用户需求的场景中,如在线客服、个性化推荐和智能助手等。其高效性和灵活性使得大语言模型能够更好地服务于实际应用,提升用户体验。
📄 摘要(原文)
Due to their substantial sizes, large language models (LLMs) are typically deployed within a single-backbone multi-tenant framework. In this setup, a single instance of an LLM backbone must cater to multiple users or tasks through the application of various parameter-efficient fine-tuning (PEFT) models. Despite the availability of numerous effective PEFT techniques such as LoRA, there remains a need for a PEFT approach that achieves both high efficiency during inference and competitive performance on downstream tasks. In this research, we introduce a new and straightforward PEFT methodology named \underline{P}rompt D\underline{E}pen\underline{D}ent \underline{R}epresentation M\underline{O}dification (PEDRO). The proposed method involves integrating a lightweight vector generator into each Transformer layer, which generates vectors contingent upon the input prompts. These vectors then modify the hidden representations created by the LLM through a dot product operation, thereby influencing the semantic output and generated content of the model. Extensive experimentation across a variety of tasks indicates that: (a) PEDRO surpasses recent PEFT benchmarks when using a similar number of tunable parameters. (b) Under the single-backbone multi-tenant deployment model, PEDRO exhibits superior efficiency compared to LoRA, indicating significant industrial potential.