Self-supervised Preference Optimization: Enhance Your Language Model with Preference Degree Awareness
作者: Jian Li, Haojing Huang, Yujia Zhang, Pengfei Xu, Xi Chen, Rui Song, Lida Shi, Jingwen Wang, Hao Xu
分类: cs.CL, cs.AI
发布日期: 2024-09-26
备注: Accepted at EMNLP 2024 Findings
🔗 代码/项目: GITHUB
💡 一句话要点
提出自监督偏好优化SPO,提升语言模型对偏好程度的理解能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自监督学习 偏好优化 大型语言模型 人类反馈 偏好程度
📋 核心要点
- 现有基于偏好优化的LLM方法忽略了不同响应中存在的偏好程度差异,限制了模型对人类偏好的充分理解。
- 论文提出自监督偏好优化(SPO)框架,通过构建自监督偏好程度损失,提升LLM对偏好程度的感知能力。
- 实验结果表明,SPO可以无缝集成到现有偏好优化方法中,并在多个数据集上显著提升性能,达到SOTA水平。
📝 摘要(中文)
近来,使用直接偏好优化(DPO)及其变体等方法,以取代强化学习与人类反馈(RLHF)中的奖励模型,受到了大型语言模型(LLM)领域的广泛关注。这些方法通常在成对样本上使用二元交叉熵机制,即分别基于偏好或不偏好的响应来最小化和最大化损失。然而,虽然这种训练策略省略了奖励模型,但它也忽略了不同响应中存在的偏好程度差异。我们假设这是阻碍LLM充分理解人类偏好的一个关键因素。为了解决这个问题,我们提出了一种新颖的自监督偏好优化(SPO)框架,该框架构建了一个自监督偏好程度损失,并将其与对齐损失相结合,从而帮助LLM提高其理解偏好程度的能力。在两个广泛使用的不同任务数据集上进行了大量实验。结果表明,SPO可以与现有的偏好优化方法无缝集成,并显著提高它们的性能,从而达到最先进的水平。我们还进行了详细的分析,以提供对SPO的全面见解,验证了其有效性。代码可在https://github.com/lijian16/SPO获取。
🔬 方法详解
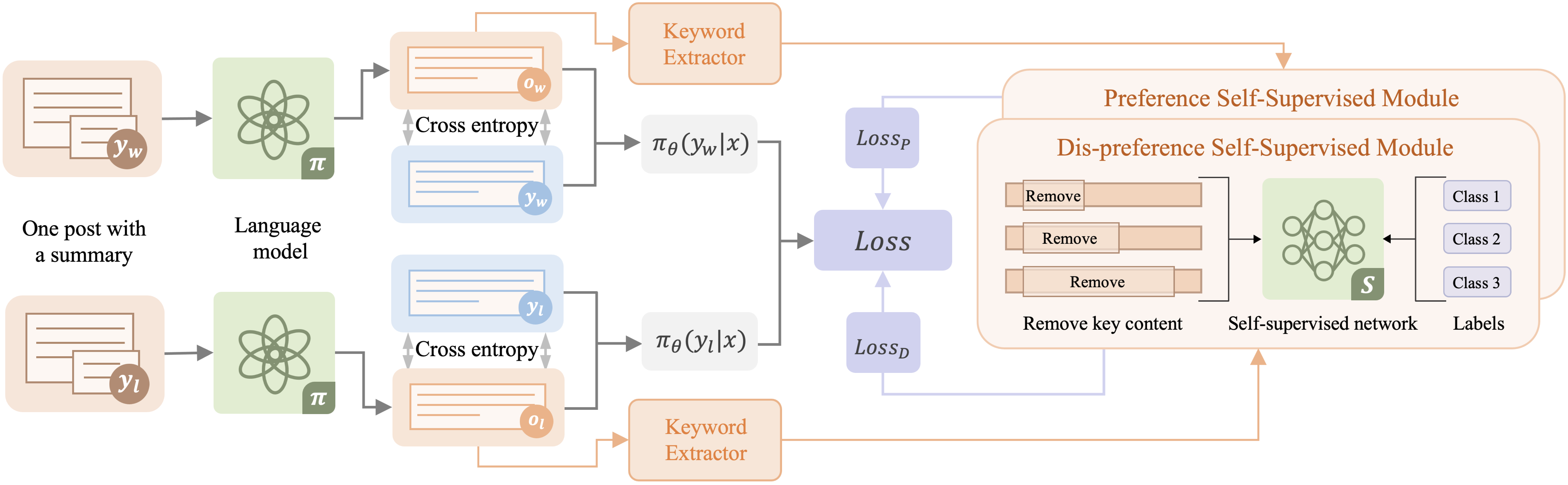
问题定义:现有基于直接偏好优化(DPO)及其变体的LLM训练方法,在利用人类反馈进行模型对齐时,通常采用二元交叉熵损失,仅区分偏好和不偏好,忽略了人类偏好程度的差异。这种简化处理导致模型无法充分学习和理解人类偏好的细微差别,限制了模型性能的进一步提升。
核心思路:论文的核心思路是引入自监督学习机制,让模型能够学习和理解不同响应之间的偏好程度。通过构建一个自监督偏好程度损失,模型可以从数据中自动学习偏好程度的分布,从而更好地对齐人类偏好。这种方法无需额外的标注数据,利用模型自身的能力来挖掘偏好信息。
技术框架:SPO框架主要包含两个部分:一是现有的偏好优化方法(如DPO),用于进行基本的偏好对齐;二是自监督偏好程度损失,用于提升模型对偏好程度的理解。这两个部分共同作用,使得模型既能学习到人类的偏好,又能理解偏好的强弱。整体流程是,首先使用现有的偏好优化方法进行训练,然后加入自监督偏好程度损失进行微调,从而提升模型性能。
关键创新:该论文的关键创新在于提出了自监督偏好程度损失,这是一种全新的损失函数,能够让模型学习和理解偏好程度。与传统的二元交叉熵损失相比,自监督偏好程度损失能够提供更丰富的信息,帮助模型更好地对齐人类偏好。此外,SPO框架可以无缝集成到现有的偏好优化方法中,具有很强的通用性。
关键设计:自监督偏好程度损失的具体形式未知,论文中可能使用了某种方式来衡量不同响应之间的偏好程度差异,并将其转化为损失函数。具体的技术细节需要参考论文原文。此外,如何将自监督偏好程度损失与现有的偏好优化方法进行有效结合,也是一个关键的设计问题。具体的权重设置、训练策略等都需要仔细考虑。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SPO可以显著提升现有偏好优化方法的性能,在两个广泛使用的数据集上均取得了SOTA结果。具体的性能提升幅度未知,需要参考论文原文。实验还进行了详细的分析,验证了SPO的有效性,并提供了对SPO的全面见解。
🎯 应用场景
该研究成果可广泛应用于各种需要与人类偏好对齐的语言模型应用场景,例如对话系统、文本生成、推荐系统等。通过提升模型对偏好程度的理解,可以生成更符合用户期望的响应,提高用户满意度。未来,该方法有望应用于更复杂的场景,例如多轮对话、个性化推荐等,进一步提升语言模型的智能化水平。
📄 摘要(原文)
Recently, there has been significant interest in replacing the reward model in Reinforcement Learning with Human Feedback (RLHF) methods for Large Language Models (LLMs), such as Direct Preference Optimization (DPO) and its variants. These approaches commonly use a binary cross-entropy mechanism on pairwise samples, i.e., minimizing and maximizing the loss based on preferred or dis-preferred responses, respectively. However, while this training strategy omits the reward model, it also overlooks the varying preference degrees within different responses. We hypothesize that this is a key factor hindering LLMs from sufficiently understanding human preferences. To address this problem, we propose a novel Self-supervised Preference Optimization (SPO) framework, which constructs a self-supervised preference degree loss combined with the alignment loss, thereby helping LLMs improve their ability to understand the degree of preference. Extensive experiments are conducted on two widely used datasets of different tasks. The results demonstrate that SPO can be seamlessly integrated with existing preference optimization methods and significantly boost their performance to achieve state-of-the-art performance. We also conduct detailed analyses to offer comprehensive insights into SPO, which verifies its effectiveness. The code is available at https://github.com/lijian16/SPO.