MIO: A Foundation Model on Multimodal Tokens
作者: Zekun Wang, King Zhu, Chunpu Xu, Wangchunshu Zhou, Jiaheng Liu, Yibo Zhang, Jiashuo Wang, Ning Shi, Siyu Li, Yizhi Li, Haoran Que, Zhaoxiang Zhang, Yuanxing Zhang, Ge Zhang, Ke Xu, Jie Fu, Wenhao Huang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-09-26 (更新: 2025-10-16)
备注: EMNLP 2025 (Oral). Codes and models are available in https://github.com/MIO-Team/MIO
期刊: EMNLP 2025
💡 一句话要点
MIO:基于多模态Token的端到端自回归通用基础模型,支持语音、文本、图像和视频的理解与生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 基础模型 自回归模型 语音识别 图像生成 视频理解 任意到任意生成
📋 核心要点
- 现有LLM和MM-LLM缺乏真正的任意到任意的理解和生成能力,限制了其在复杂现实世界任务中的应用。
- MIO通过构建在多模态token上的端到端自回归模型,实现了语音、文本、图像和视频的统一理解和生成。
- 实验表明,MIO在多种任务上表现出与现有模型相当甚至更优越的性能,并展现了其独特的任意到任意特性。
📝 摘要(中文)
本文介绍了MIO,一种新型的基于多模态token构建的基础模型,它能够以端到端、自回归的方式理解和生成语音、文本、图像和视频。虽然大型语言模型(LLM)和多模态大型语言模型(MM-LLM)的出现通过其多功能性推动了通用人工智能的进步,但它们仍然缺乏真正的任意到任意的理解和生成能力。最近,GPT-4o的发布展示了任意到任意LLM在复杂现实世界任务中的巨大潜力,实现了跨图像、语音和文本的全方位输入和输出。然而,它是闭源的,并且不支持多模态交错序列的生成。为了解决这个差距,我们提出了MIO,它使用因果多模态建模在四种模态的离散token混合数据上进行训练。MIO经历了一个四个阶段的训练过程:(1)对齐预训练,(2)交错预训练,(3)语音增强预训练,以及(4)对各种文本、视觉和语音任务进行全面的监督微调。我们的实验结果表明,与之前的双模态基线、任意到任意模型基线,甚至特定模态基线相比,MIO表现出具有竞争力的性能,在某些情况下甚至更优越。此外,MIO展示了其任意到任意特性所固有的高级能力,例如交错的视频-文本生成、视觉思维链推理、视觉指导生成、指令式图像编辑等。
🔬 方法详解
问题定义:现有的大型语言模型和多模态大型语言模型虽然在多种任务上表现出色,但它们在处理任意模态之间的转换和生成时仍然存在局限性。特别是,它们难以实现真正端到端的、任意到任意的理解和生成,例如,无法直接根据语音生成图像,或者生成包含交错文本和视频的序列。此外,一些先进的模型(如GPT-4o)虽然展现了强大的任意到任意能力,但却是闭源的,限制了研究和应用。
核心思路:MIO的核心思路是构建一个基于多模态token的统一模型,通过自回归的方式学习不同模态之间的关联。通过将语音、文本、图像和视频都表示为离散的token序列,MIO能够以统一的方式处理各种模态的输入和输出,从而实现任意模态之间的转换和生成。这种设计使得模型能够更好地捕捉不同模态之间的语义关系,并生成连贯的多模态内容。
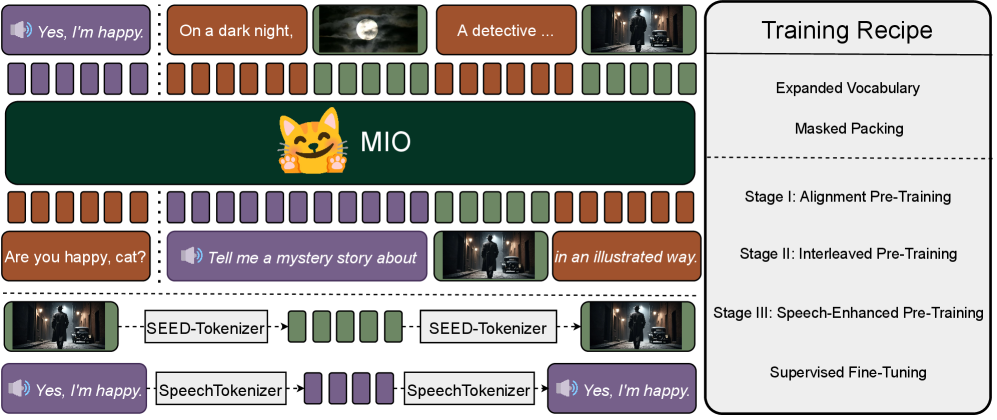
技术框架:MIO的训练过程分为四个阶段:(1) 对齐预训练:旨在将不同模态的token映射到统一的语义空间,使模型能够理解不同模态之间的对应关系。(2) 交错预训练:训练模型生成包含多种模态交错的序列,例如,文本和图像交替出现的序列。(3) 语音增强预训练:侧重于提升模型在语音相关任务上的性能。(4) 综合监督微调:在各种文本、视觉和语音任务上进行微调,以提升模型的整体性能。
关键创新:MIO的关键创新在于其基于多模态token的统一表示方法和端到端的自回归生成框架。与以往需要针对不同模态设计特定模块的模型不同,MIO能够以统一的方式处理各种模态,从而简化了模型的设计和训练过程。此外,MIO的自回归生成框架使得模型能够生成连贯的多模态内容,例如,交错的视频-文本序列。
关键设计:MIO使用了因果多模态建模,这意味着模型在生成下一个token时,只能依赖于之前的token。这种设计保证了生成的序列的连贯性。此外,MIO在训练过程中使用了多种损失函数,以平衡不同模态之间的学习。具体的参数设置和网络结构细节在论文中没有详细说明,属于未知信息。
🖼️ 关键图片

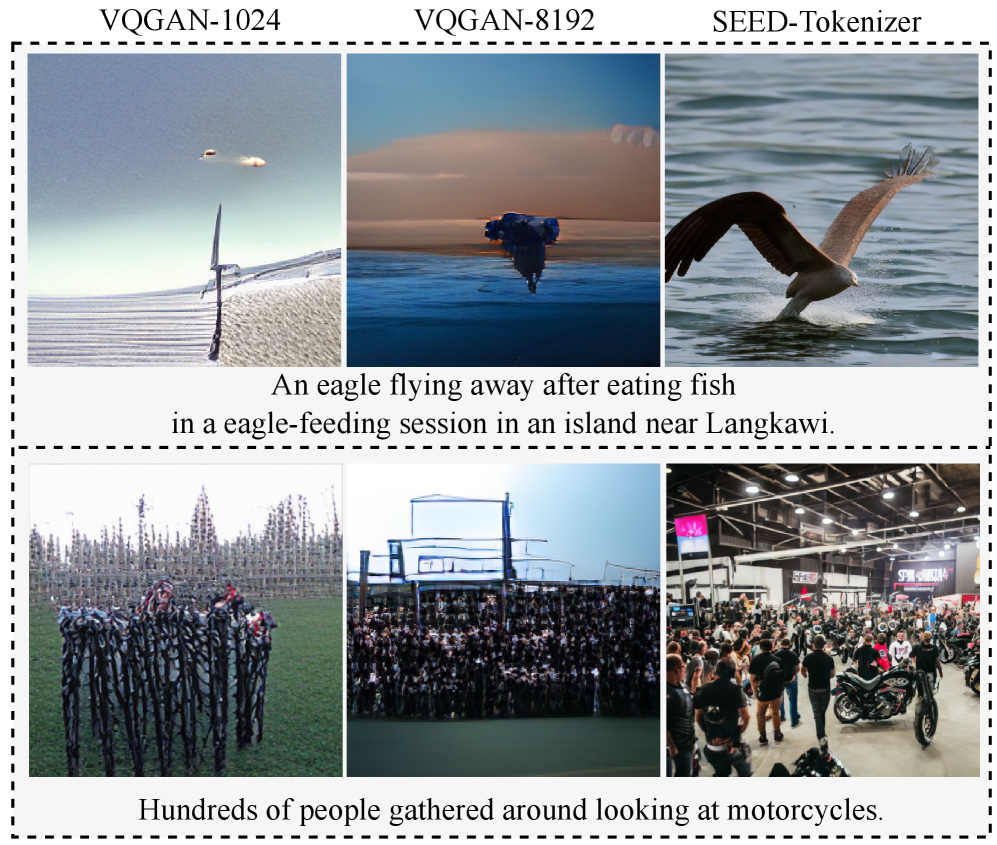
📊 实验亮点
MIO在多个任务上取得了具有竞争力的性能,甚至超越了之前的双模态和特定模态基线模型。更重要的是,MIO展示了其独特的任意到任意能力,例如,能够生成交错的视频-文本序列,进行视觉思维链推理,生成视觉指导,以及进行指令式图像编辑。这些结果表明,MIO在多模态理解和生成方面具有巨大的潜力。
🎯 应用场景
MIO具有广泛的应用前景,包括多模态对话系统、智能创作工具、教育辅助应用等。例如,它可以用于生成带有解说的视频,根据用户的语音指令编辑图像,或者创建包含文本和图像的交互式学习材料。MIO的任意到任意特性使其能够适应各种复杂的现实世界场景,并为用户提供更加自然和便捷的交互体验。
📄 摘要(原文)
In this paper, we introduce MIO, a novel foundation model built on multimodal tokens, capable of understanding and generating speech, text, images, and videos in an end-to-end, autoregressive manner. While the emergence of large language models (LLMs) and multimodal large language models (MM-LLMs) propels advancements in artificial general intelligence through their versatile capabilities, they still lack true any-to-any understanding and generation. Recently, the release of GPT-4o has showcased the remarkable potential of any-to-any LLMs for complex real-world tasks, enabling omnidirectional input and output across images, speech, and text. However, it is closed-source and does not support the generation of multimodal interleaved sequences. To address this gap, we present MIO, which is trained on a mixture of discrete tokens across four modalities using causal multimodal modeling. MIO undergoes a four-stage training process: (1) alignment pre-training, (2) interleaved pre-training, (3) speech-enhanced pre-training, and (4) comprehensive supervised fine-tuning on diverse textual, visual, and speech tasks. Our experimental results indicate that MIO exhibits competitive, and in some cases superior, performance compared to previous dual-modal baselines, any-to-any model baselines, and even modality-specific baselines. Moreover, MIO demonstrates advanced capabilities inherent to its any-to-any feature, such as interleaved video-text generation, chain-of-visual-thought reasoning, visual guideline generation, instructional image editing, etc.