T3: A Novel Zero-shot Transfer Learning Framework Iteratively Training on an Assistant Task for a Target Task
作者: Xindi Tong, Yujin Zhu, Shijian Fan, Liang Xu
分类: cs.CL, cs.AI
发布日期: 2024-09-26 (更新: 2025-01-22)
💡 一句话要点
提出T3框架,通过迭代训练辅助任务提升LLM在长文本摘要任务上的零样本迁移能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本摘要 零样本学习 迁移学习 大型语言模型 问答系统
📋 核心要点
- 长文本摘要对LLM构成挑战,原因在于缺乏训练数据和对上下文细节的高要求。
- T3框架的核心思想是利用数据丰富的辅助任务迭代训练LLM,提升其在目标任务上的零样本迁移能力。
- 实验表明,T3在长文本摘要任务上显著提升了ROUGE、BLEU和Factscore等指标,效果显著。
📝 摘要(中文)
针对大型语言模型(LLMs)如GPT和LLaMA系列在长文本摘要任务中,因缺乏开源训练数据集和对上下文细节处理的高要求而面临的挑战,本文设计了一种名为T3的零样本迁移学习框架。该框架通过迭代地训练一个基线LLM,使其在与目标任务具有结构或语义相似性且拥有更丰富数据资源的辅助任务上进行学习,从而提升其在目标任务上的表现。实践中,T3被应用于长文本摘要任务,并利用问答作为辅助任务。在BBC summary、NarraSum、FairytaleQA和NLQuAD数据集上的验证结果表明,与三个基线LLM相比,ROUGE指标提升近14%,BLEU指标提升35%,Factscore指标提升16%,证明了T3在更多辅助-目标任务组合中的潜力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在长文本摘要任务中面临的挑战。现有方法由于缺乏足够的训练数据,以及模型难以有效处理长文本中的上下文信息,导致摘要质量不高,事实性错误较多。
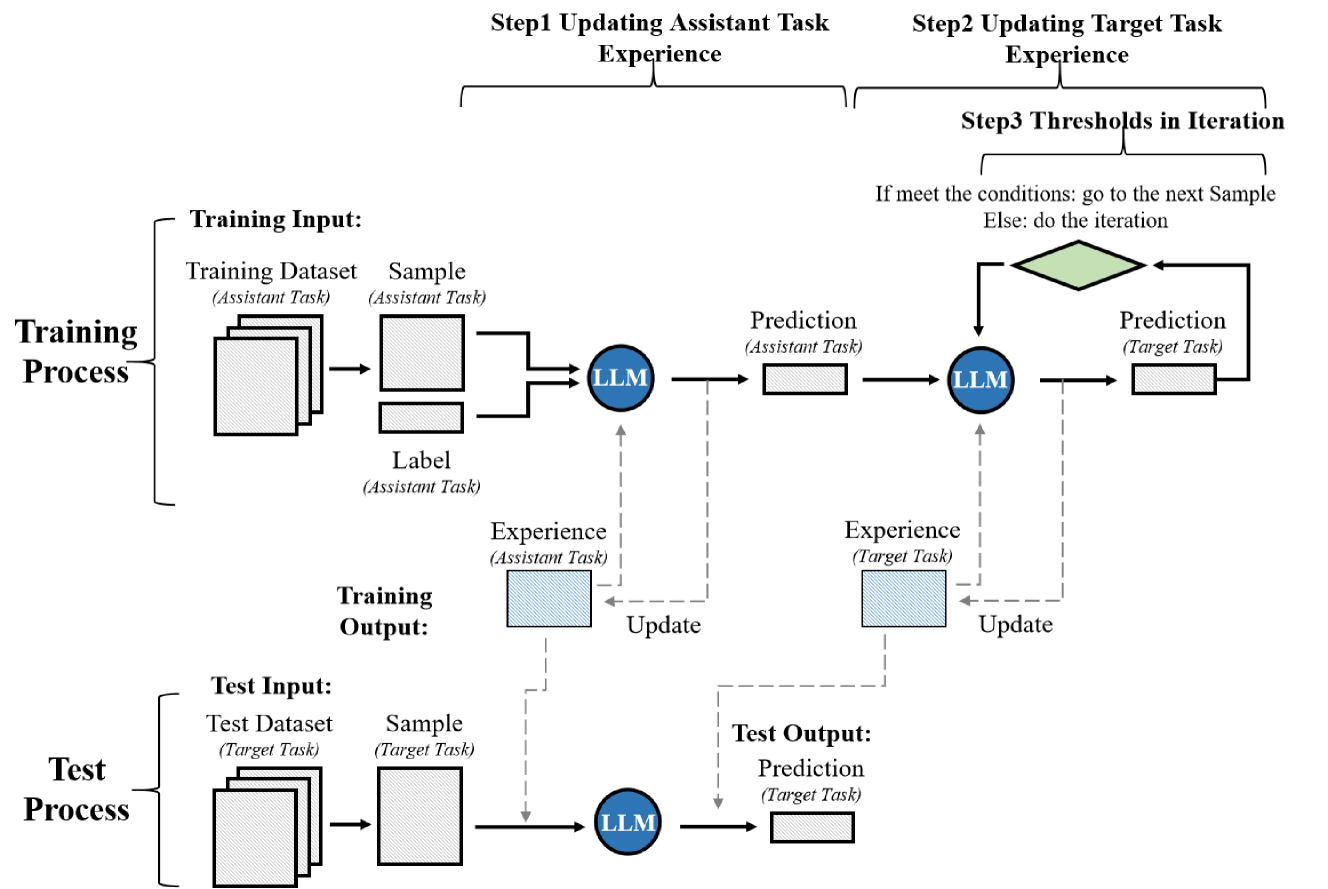
核心思路:论文的核心思路是利用迁移学习,通过在与长文本摘要任务相关的辅助任务上进行预训练,使模型学习到通用的文本理解和生成能力,从而提升其在长文本摘要任务上的表现。选择辅助任务的关键在于其数据资源丰富,并且与目标任务在结构或语义上具有相似性。
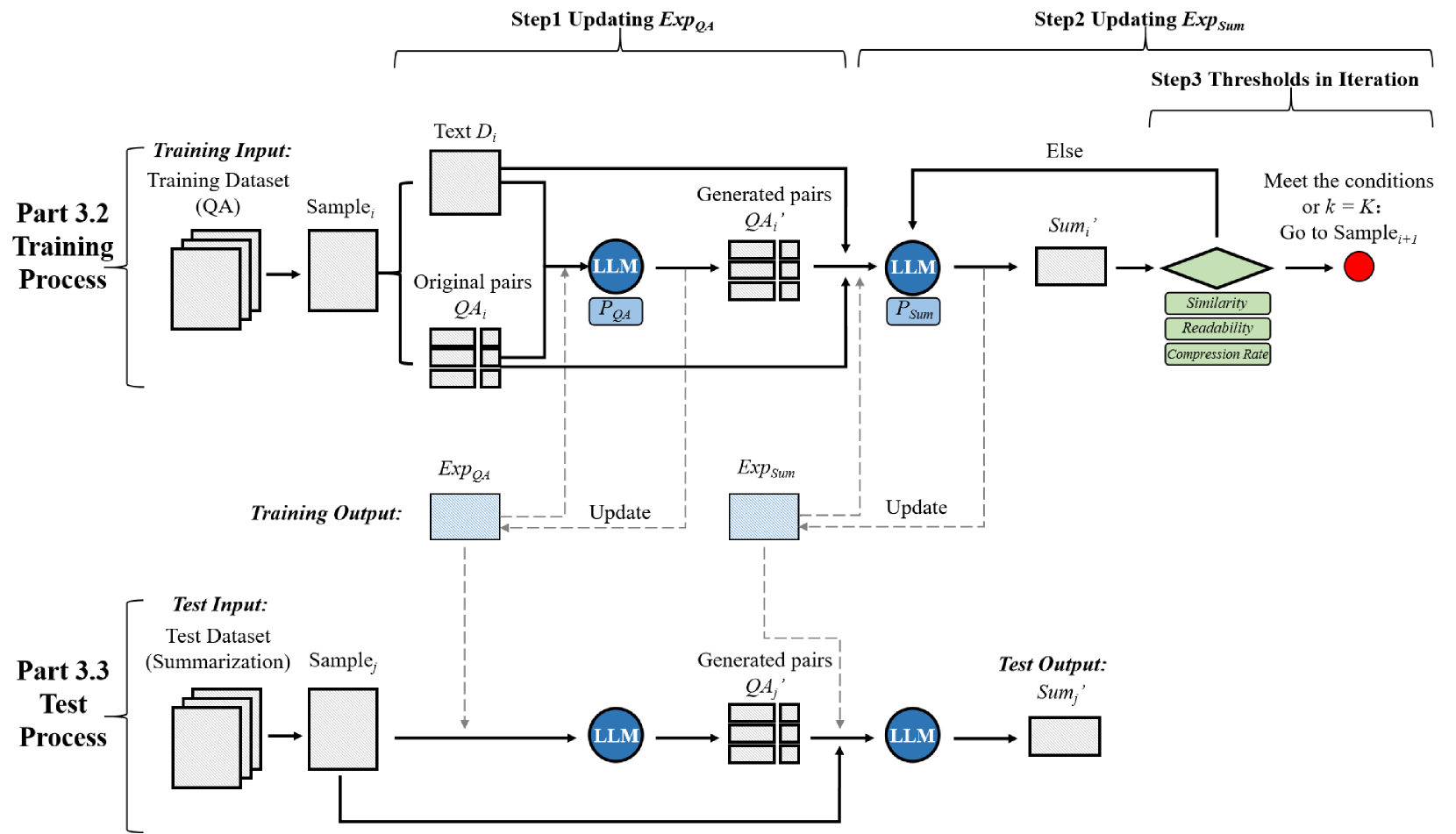
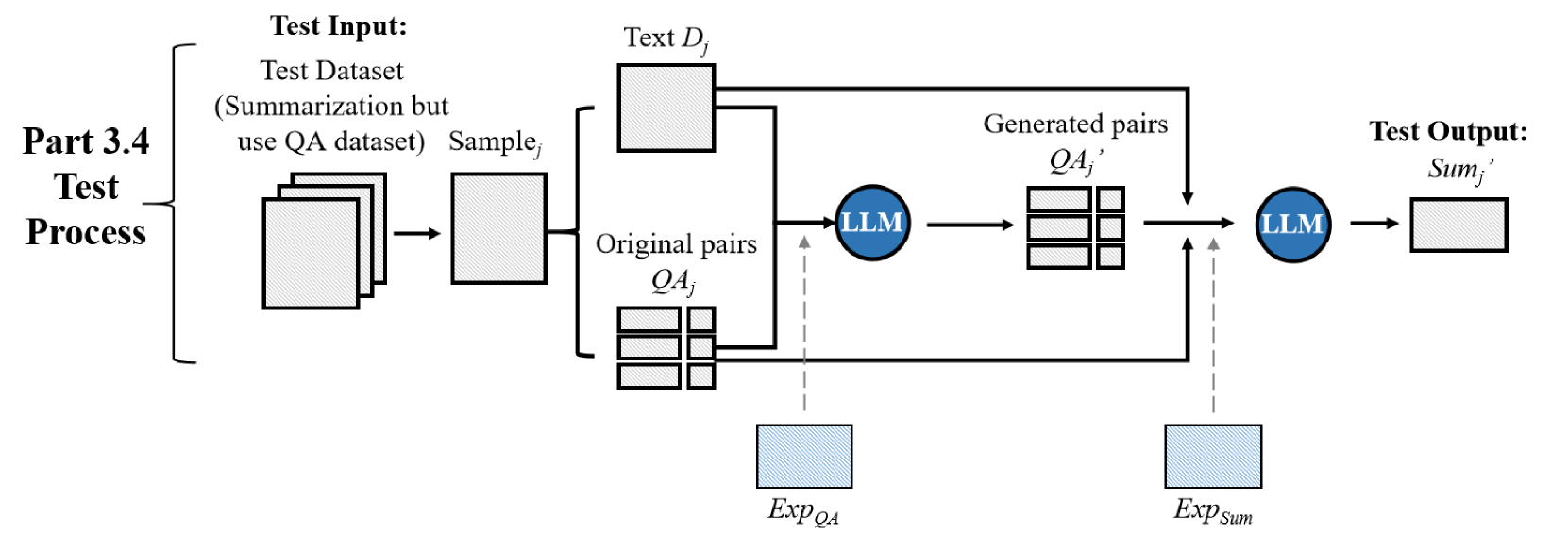
技术框架:T3框架包含以下主要步骤:1) 选择一个与目标任务相关的辅助任务,例如问答;2) 使用辅助任务的数据集对基线LLM进行训练;3) 使用目标任务的数据集对训练后的LLM进行微调或直接进行零样本推理。该过程可以迭代进行,即每次训练后,将模型在目标任务上的表现作为反馈,调整辅助任务的训练策略。
关键创新:T3框架的关键创新在于其迭代训练的策略。通过迭代地在辅助任务上训练,模型可以逐步学习到更有效的文本理解和生成能力,从而更好地适应目标任务。此外,T3框架还强调了辅助任务的选择,认为选择与目标任务具有结构或语义相似性的辅助任务可以更好地提升迁移效果。
关键设计:论文中,辅助任务选择为问答任务,因为问答任务需要模型理解文本并生成简洁的答案,这与长文本摘要任务的目标相似。具体的训练细节和参数设置在论文中没有详细描述,需要参考论文原文。
🖼️ 关键图片
📊 实验亮点
实验结果表明,T3框架在BBC summary、NarraSum、FairytaleQA和NLQuAD数据集上取得了显著的性能提升。与三个基线LLM相比,ROUGE指标提升近14%,BLEU指标提升35%,Factscore指标提升16%。这些结果表明,T3框架能够有效提升LLM在长文本摘要任务上的性能。
🎯 应用场景
T3框架具有广泛的应用前景,可应用于新闻摘要、报告生成、法律文档摘要等领域。通过选择合适的辅助任务,可以提升LLM在各种长文本处理任务上的性能,降低对大规模标注数据的依赖,具有重要的实际应用价值和商业潜力。
📄 摘要(原文)
Long text summarization, gradually being essential for efficiently processing large volumes of information, stays challenging for Large Language Models (LLMs) such as GPT and LLaMA families because of the insufficient open-sourced training datasets and the high requirement of contextual details dealing. To address the issue, we design a novel zero-shot transfer learning framework, abbreviated as T3, to iteratively training a baseline LLM on an assistant task for the target task, where the former should own richer data resources and share structural or semantic similarity with the latter. In practice, T3 is approached to deal with the long text summarization task by utilizing question answering as the assistant task, and further validated its effectiveness on the BBC summary, NarraSum, FairytaleQA, and NLQuAD datasets, with up to nearly 14% improvement in ROUGE, 35% improvement in BLEU, and 16% improvement in Factscore compared to three baseline LLMs, demonstrating its potential for more assistant-target task combinations.