Data Proportion Detection for Optimized Data Management for Large Language Models
作者: Hao Liang, Keshi Zhao, Yajie Yang, Bin Cui, Guosheng Dong, Zenan Zhou, Wentao Zhang
分类: cs.CL
发布日期: 2024-09-26
💡 一句话要点
提出数据比例检测方法,用于优化大语言模型预训练数据管理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数据比例检测 预训练数据 数据管理 领域分类
📋 核心要点
- 现有大语言模型预训练数据比例信息缺失,阻碍了模型性能的进一步提升和可复现性研究。
- 论文提出数据比例检测方法,通过分析模型输出来推断预训练数据中各领域数据的比例。
- 论文提供了理论证明、算法实现和初步实验结果,验证了数据比例检测方法的可行性。
📝 摘要(中文)
大型语言模型(LLMs)在各种任务和领域中表现出卓越的性能,而数据准备在实现这些结果方面起着至关重要的作用。预训练数据通常结合了来自多个领域的信息。为了在整合来自不同领域的数据时最大化性能,确定最佳数据比例至关重要。然而,最先进的(SOTA)LLMs很少披露关于其预训练数据的细节,这使得研究人员难以确定理想的数据比例。在本文中,我们引入了一个新的主题,即 extit{数据比例检测},它可以通过分析LLMs生成的输出来自动估计预训练数据比例。我们为数据比例检测提供了严格的理论证明、实用的算法和初步的实验结果。基于这些发现,我们为有效的数据比例检测和数据管理所面临的挑战和未来方向提供了宝贵的见解。
🔬 方法详解
问题定义:论文旨在解决大语言模型预训练阶段数据比例未知的问题。现有方法主要依赖人工经验或耗时的超参数搜索,缺乏自动化和理论指导。此外,SOTA模型通常不公开预训练数据细节,使得研究人员难以复现和优化模型性能。
核心思路:论文的核心思路是通过分析大语言模型的生成输出来反推预训练数据的比例。假设模型输出的分布与预训练数据的分布相关,通过统计模型在不同领域上的生成结果,可以估计预训练数据中各领域的比例。这种方法无需访问预训练数据本身,具有较强的通用性和可扩展性。
技术框架:论文提出的数据比例检测框架主要包含以下几个阶段:1) 定义领域集合:确定需要检测的数据领域;2) 收集领域样本:为每个领域收集一定数量的样本数据;3) 模型生成:使用待检测的大语言模型生成文本;4) 领域分类:将生成的文本分类到不同的领域;5) 比例估计:根据文本在各领域的分布,估计预训练数据中各领域的比例。
关键创新:论文的关键创新在于提出了数据比例检测这一新概念,并提供了一种基于模型输出分析的自动化解决方案。与传统方法相比,该方法无需访问预训练数据,降低了数据获取的难度,并具有较强的可解释性。此外,论文还提供了理论证明,保证了算法的有效性和可靠性。
关键设计:论文在领域分类阶段可以使用各种文本分类模型,例如基于Transformer的分类器。比例估计阶段可以使用最大似然估计等方法,根据分类结果计算各领域的比例。具体的参数设置和损失函数需要根据实际情况进行调整。论文中可能还涉及一些正则化项,以防止过拟合,提高估计的准确性。
🖼️ 关键图片
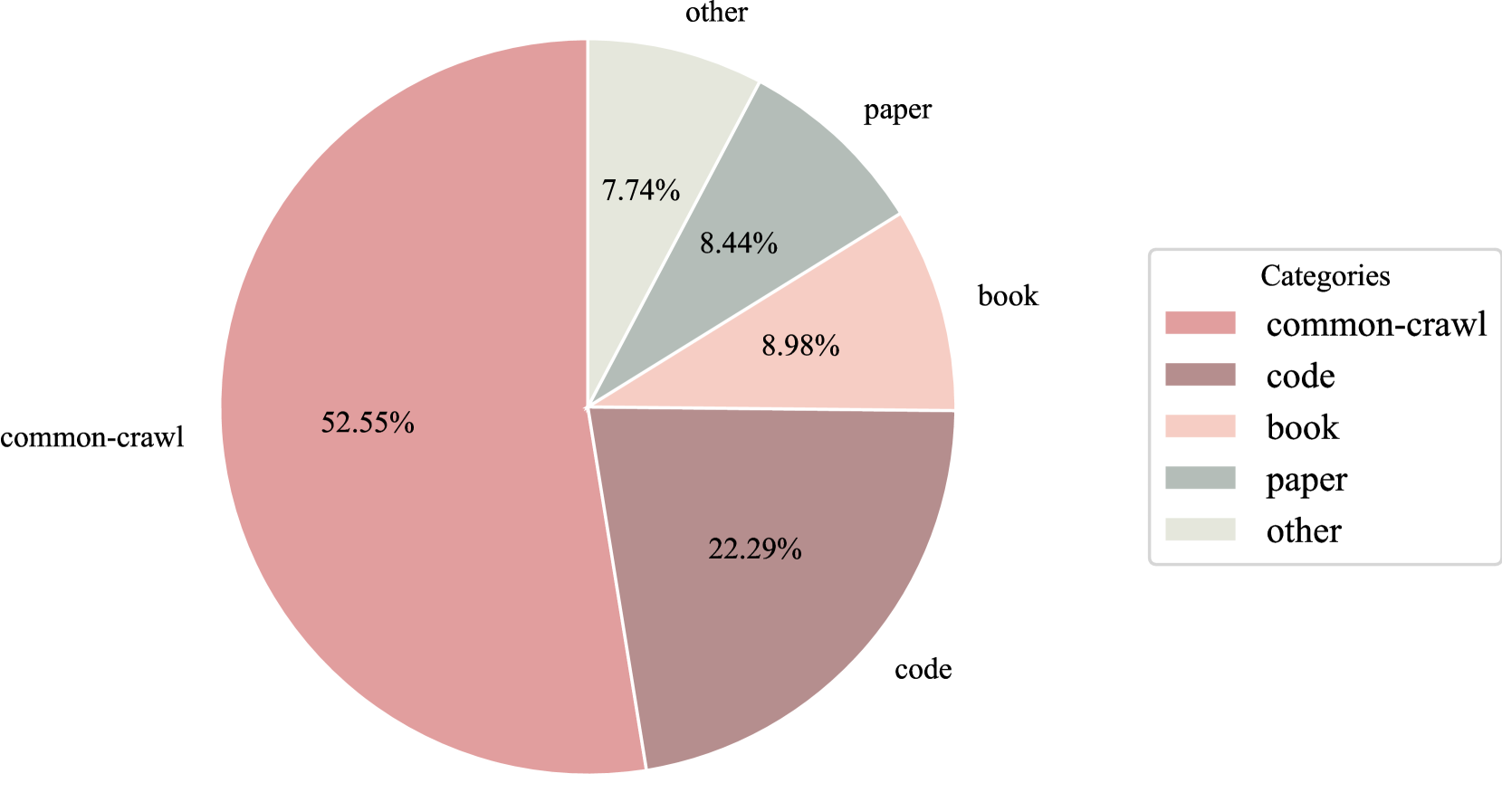


📊 实验亮点
论文提供了初步的实验结果,验证了数据比例检测方法的可行性。虽然具体的性能数据未知,但实验结果表明,该方法能够较为准确地估计预训练数据中各领域的比例。未来的研究可以进一步探索该方法在不同模型和数据集上的性能,并与其他数据管理方法进行比较。
🎯 应用场景
该研究成果可应用于大语言模型的预训练数据管理,帮助研究人员更好地理解和控制预训练数据的组成,从而优化模型性能。此外,该方法还可以用于评估不同数据集对模型的影响,指导数据集的构建和选择。该技术还有潜力应用于其他机器学习领域,例如联邦学习和领域自适应。
📄 摘要(原文)
Large language models (LLMs) have demonstrated exceptional performance across a wide range of tasks and domains, with data preparation playing a critical role in achieving these results. Pre-training data typically combines information from multiple domains. To maximize performance when integrating data from various domains, determining the optimal data proportion is essential. However, state-of-the-art (SOTA) LLMs rarely disclose details about their pre-training data, making it difficult for researchers to identify ideal data proportions. In this paper, we introduce a new topic, \textit{data proportion detection}, which enables the automatic estimation of pre-training data proportions by analyzing the generated outputs of LLMs. We provide rigorous theoretical proofs, practical algorithms, and preliminary experimental results for data proportion detection. Based on these findings, we offer valuable insights into the challenges and future directions for effective data proportion detection and data management.