DiaSynth: Synthetic Dialogue Generation Framework for Low Resource Dialogue Applications
作者: Sathya Krishnan Suresh, Wu Mengjun, Tushar Pranav, Eng Siong Chng
分类: cs.CL, cs.LG
发布日期: 2024-09-25 (更新: 2025-02-10)
备注: 13 pages, 1 figure
期刊: NAACL 2025
💡 一句话要点
DiaSynth:用于低资源对话应用的高质量合成对话生成框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 合成对话生成 低资源对话 大型语言模型 思维链推理 对话摘要
📋 核心要点
- 领域对话数据稀缺限制了对话系统发展,现有数据集规模不足。
- DiaSynth利用LLM和CoT推理,生成具有角色和多样化特征的动态对话。
- 实验表明,合成数据微调的模型在对话摘要上优于基线,性能接近领域内数据。
📝 摘要(中文)
领域特定对话数据集的稀缺性限制了对话系统在各种应用中的发展。现有的研究受到通用或特定领域数据集的约束,这些数据集缺乏训练对话系统所需的足够规模。为了解决这个问题,我们提出了DiaSynth——一个合成对话生成框架,它能够生成高质量、上下文丰富的、跨多个领域的对话。与现有的框架不同,DiaSynth使用大型语言模型(LLMs)和思维链(CoT)推理来生成具有模拟角色和多样化会话特征的动态、领域特定的对话。我们通过使用不同的LLM和来自DialogSum和SAMSum的少量样本生成合成数据来进行实验。在合成数据上微调的预训练语言模型在对话摘要任务上比基础模型提高了16.47%,而基于领域内数据和合成数据微调的模型之间的比较表明,合成数据能够捕捉到领域内数据在对话摘要任务上90.48%的性能分布。随着LLM规模从3B增加到8B,生成的数据质量也随之提高。这些结果验证了DiaSynth作为传统数据收集方法的强大替代方案的潜力。我们开源了代码和生成的数据,以供未来研究使用。
🔬 方法详解
问题定义:论文旨在解决领域特定对话数据稀缺的问题,现有方法依赖通用或小众数据集,无法满足对话系统训练的需求。现有方法难以生成高质量、上下文丰富的对话,限制了对话系统在特定领域的应用。
核心思路:论文的核心思路是利用大型语言模型(LLMs)和思维链(CoT)推理来合成对话数据。通过模拟角色和对话场景,生成具有多样化会话特征的动态对话,从而缓解数据稀缺问题。这种方法旨在生成更真实、更具上下文相关性的对话,以提高对话系统的性能。
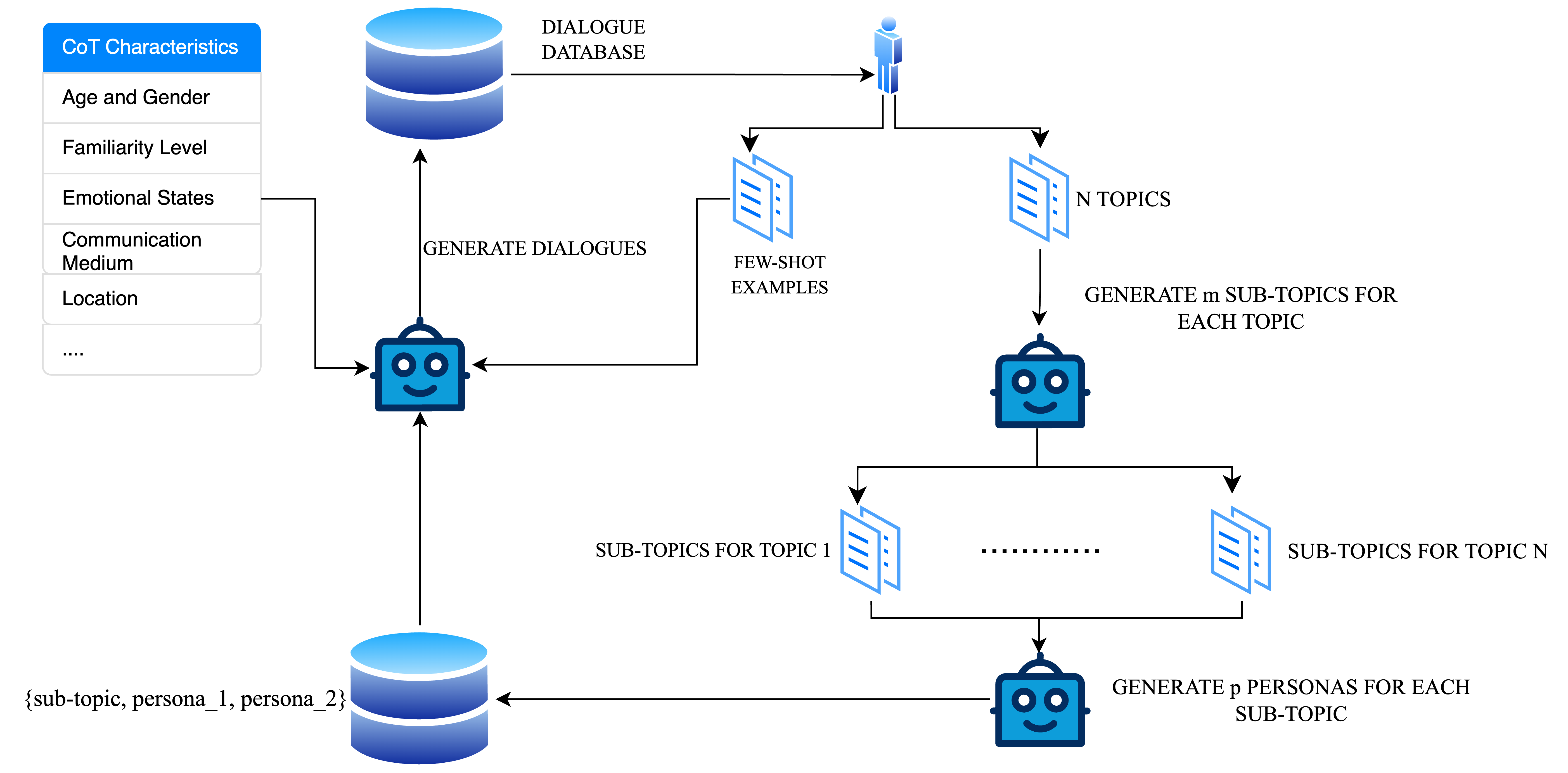
技术框架:DiaSynth框架主要包含以下几个阶段:1) 角色定义:定义对话参与者的角色和背景信息。2) 场景设定:设定对话发生的场景和目标。3) 对话生成:利用LLM和CoT推理,根据角色和场景生成对话内容。4) 数据增强:对生成的对话数据进行增强,例如添加噪声、改变语序等,以提高数据的鲁棒性。整个流程旨在自动化生成高质量的对话数据。
关键创新:DiaSynth的关键创新在于结合了LLM和CoT推理来生成对话。与传统的基于规则或模板的对话生成方法相比,DiaSynth能够生成更自然、更流畅的对话。CoT推理使得LLM能够更好地理解对话的上下文,从而生成更具逻辑性和连贯性的对话。此外,DiaSynth还能够模拟不同的角色和场景,从而生成多样化的对话数据。
关键设计:论文使用了不同的LLM(例如3B和8B模型)进行实验,并使用了来自DialogSum和SAMSum的少量样本作为few-shot示例。在微调过程中,使用了标准的语言模型训练目标。具体的损失函数和网络结构细节可能取决于所使用的LLM。论文还探索了不同的CoT提示策略,以提高生成对话的质量。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在合成数据上微调的预训练语言模型在对话摘要任务上比基础模型提高了16.47%。与在领域内数据上微调的模型相比,在合成数据上微调的模型能够达到领域内数据90.48%的性能。此外,随着LLM规模的增加(从3B到8B),生成的数据质量也随之提高,验证了DiaSynth的有效性。
🎯 应用场景
DiaSynth可应用于各种低资源对话场景,例如特定行业的客服机器人、教育领域的对话系统、以及面向小语种的对话系统。通过合成数据,可以降低对话系统开发的成本和门槛,加速对话技术在各个领域的普及。未来,该方法有望扩展到更复杂的对话场景,例如多轮对话、任务型对话等。
📄 摘要(原文)
The scarcity of domain-specific dialogue datasets limits the development of dialogue systems across applications. Existing research is constrained by general or niche datasets that lack sufficient scale for training dialogue systems. To address this gap, we introduce DiaSynth - a synthetic dialogue generation framework capable of generating high-quality, contextually rich dialogues across a wide range of domains. Unlike existing frameworks, DiaSynth uses Large Language Models (LLMs) and Chain of Thought (CoT) reasoning to generate dynamic, domain-specific dialogues with simulated personas and diverse conversational features. We perform our experiments by generating synthetic data using different LLMs and few-shot examples from DialogSum and SAMSum. The pretrained language models fine-tuned on the synthetic data outperform the base models by 16.47% on dialogue summarization, while the comparison between models fine-tuned on in-domain data and synthetic data shows that the synthetic data is able to capture 90.48% of the performance distribution of the in-domain data on dialogue summarization. The quality of the data generated also increases as we increase the size of LLM from 3B to 8B. These results validate DiaSynth's potential as a robust alternative to traditional data collection methods. We open source the code and data generated for future research.