On Extending Direct Preference Optimization to Accommodate Ties
作者: Jinghong Chen, Guangyu Yang, Weizhe Lin, Jingbiao Mei, Bill Byrne
分类: cs.CL
发布日期: 2024-09-25 (更新: 2025-11-04)
备注: 24 pages, NeurIPS 2025
💡 一句话要点
扩展直接偏好优化(DPO)以处理并列偏好,提升翻译与推理任务性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 直接偏好优化 并列偏好 Rao-Kupper模型 Davidson模型 机器翻译 文本摘要 数学推理 正则化
📋 核心要点
- 传统DPO方法在处理偏好数据时,通常忽略或丢弃并列情况,导致信息损失和潜在的性能下降。
- 论文核心在于扩展DPO框架,通过引入Rao-Kupper和Davidson模型,显式建模并列偏好,更准确地反映数据。
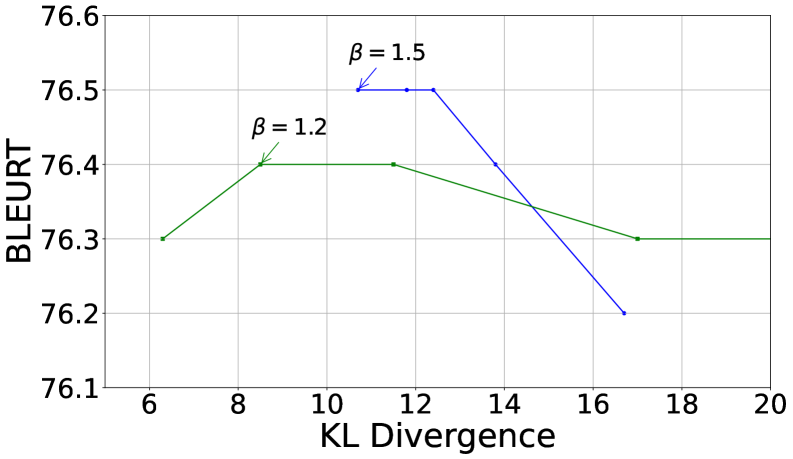
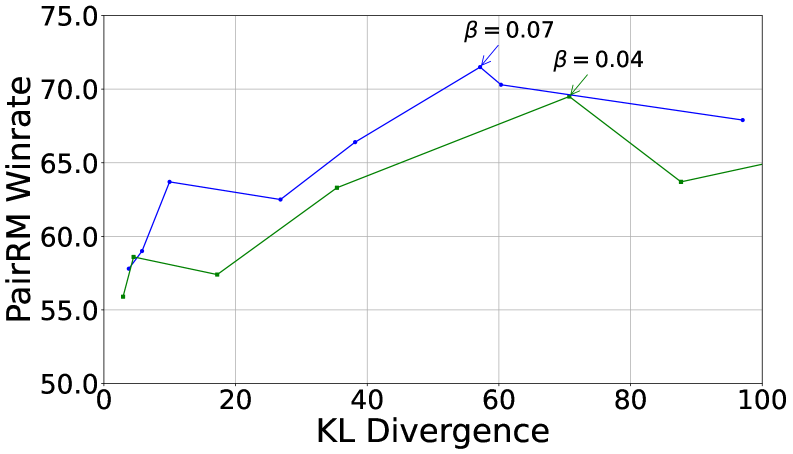
- 实验结果表明,新方法在机器翻译和数学推理任务上优于原始DPO,且包含并列数据能增强模型正则化效果。
📝 摘要(中文)
本文提出了两种DPO变体,它们显式地对成对比较中声明并列的可能性进行建模。我们用Rao和Kupper以及Davidson提出的两种著名的建模扩展取代了DPO中的Bradley-Terry模型,这些扩展为并列分配概率,作为明确偏好的替代方案。在神经机器翻译和摘要生成方面的实验表明,显式标记的并列可以添加到这些DPO变体的数据集中,而不会像将相同的并列对呈现给DPO时那样降低任务性能。我们凭经验发现,包含并列会导致更强的关于参考策略的正则化(通过KL散度衡量),甚至对于原始形式的DPO也是如此。我们使用理想DPO策略理论为这种正则化效应提供了理论解释。我们进一步展示了我们的DPO变体在翻译和数学推理方面优于DPO的性能改进。我们发现,在偏好优化中包含并列可能是有益的,而不是像通常的做法那样简单地丢弃它们。
🔬 方法详解
问题定义:现有的直接偏好优化(DPO)方法在处理pairwise偏好数据时,通常假设所有样本都存在明确的偏好关系(A优于B,或B优于A)。然而,在实际应用中,存在大量“并列”的情况,即模型或人类标注者认为两个样本质量相当,无法区分优劣。直接忽略这些并列样本会导致信息损失,并可能影响模型的训练效果。因此,如何有效地利用这些并列信息,提升DPO的性能,是本文要解决的核心问题。
核心思路:本文的核心思路是扩展DPO框架,使其能够显式地建模并列偏好。具体来说,作者将DPO中使用的Bradley-Terry模型替换为能够处理并列情况的Rao-Kupper模型和Davidson模型。这些模型能够为并列情况分配概率,从而更准确地反映pairwise比较的结果。通过在训练过程中考虑并列情况,模型可以更好地学习到数据的真实分布,从而提升性能。
技术框架:本文提出的方法主要包含以下几个步骤:1. 数据准备:构建包含明确偏好和并列偏好的pairwise比较数据集。2. 模型选择:选择DPO作为基础框架,并用Rao-Kupper或Davidson模型替换其原有的Bradley-Terry模型。3. 训练:使用包含并列信息的pairwise比较数据集训练模型。4. 评估:在机器翻译、摘要生成和数学推理等任务上评估模型的性能。
关键创新:本文最重要的技术创新点在于将能够处理并列情况的Rao-Kupper和Davidson模型引入到DPO框架中。这使得DPO能够显式地建模并列偏好,从而更准确地反映数据的真实分布。此外,作者还从理论上解释了包含并列信息能够增强模型正则化效果的原因。
关键设计:在具体实现上,作者需要修改DPO的损失函数,以适应Rao-Kupper和Davidson模型。具体来说,损失函数需要能够根据不同的模型,为明确偏好和并列情况分配不同的权重。此外,作者还需要调整训练策略,以确保模型能够有效地学习到并列信息。例如,可以增加并列样本在训练集中的比例,或者使用特定的采样策略来选择训练样本。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在神经机器翻译和摘要生成任务中,使用包含并列信息的DPO变体能够取得优于原始DPO的性能。此外,在数学推理任务中,该方法也取得了显著的性能提升。实验还发现,包含并列信息能够增强模型的正则化效果,降低模型对参考策略的过度依赖。
🎯 应用场景
该研究成果可广泛应用于需要处理偏好数据的自然语言处理任务中,例如机器翻译、文本摘要、对话生成、推荐系统等。通过更准确地建模偏好关系,可以提升模型的生成质量和用户体验。此外,该方法在需要人工标注偏好数据的场景下也具有重要价值,可以减少标注成本,提高数据利用率。
📄 摘要(原文)
We derive and investigate two DPO variants that explicitly model the possibility of declaring a tie in pair-wise comparisons. We replace the Bradley-Terry model in DPO with two well-known modeling extensions, by Rao and Kupper and by Davidson, that assign probability to ties as alternatives to clear preferences. Our experiments in neural machine translation and summarization show that explicitly labeled ties can be added to the datasets for these DPO variants without the degradation in task performance that is observed when the same tied pairs are presented to DPO. We find empirically that the inclusion of ties leads to stronger regularization with respect to the reference policy as measured by KL divergence, and we see this even for DPO in its original form. We provide a theoretical explanation for this regularization effect using ideal DPO policy theory. We further show performance improvements over DPO in translation and mathematical reasoning using our DPO variants. We find it can be beneficial to include ties in preference optimization rather than simply discard them, as is done in common practice.