Internalizing ASR with Implicit Chain of Thought for Efficient Speech-to-Speech Conversational LLM
作者: Robin Shing-Hei Yuen, Timothy Tin-Long Tse, Jian Zhu
分类: cs.CL
发布日期: 2024-09-25 (更新: 2024-11-04)
备注: Updated for reviewer comments
💡 一句话要点
提出隐式思维链的语音LLM,提升端到端语音对话效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音大语言模型 端到端学习 隐式ASR 语音对话系统 思维链 语音理解 合成数据集
📋 核心要点
- 现有语音LLM依赖ASR-TTS流水线,导致延迟高且损失音频特征,限制了实时语音交互。
- 论文提出隐式地将ASR思维链融入语音LLM,提升模型原生语音理解能力,减少延迟。
- 论文发布大规模合成对话数据集,促进相关研究,并验证了所提方法的有效性。
📝 摘要(中文)
当前基于语音的大语言模型主要依赖于大量的语音识别(ASR)和语音合成(TTS)数据集进行训练,在相关任务中表现出色。然而,它们处理直接语音到语音对话的能力仍然受到限制。这些模型通常依赖于ASR到TTS的思维链流程,将语音转换为文本进行处理,然后再生成音频响应,这引入了延迟并丢失了音频特征。我们提出了一种方法,将ASR思维链隐式地融入到语音LLM中,从而增强其原生的语音理解能力。我们的方法减少了延迟,并提高了模型对语音的自然理解,为更高效、更自然的实时音频交互铺平了道路。我们还发布了一个大规模的合成对话数据集,以促进进一步的研究。
🔬 方法详解
问题定义:现有语音对话系统通常采用 ASR (语音识别) + LLM (大语言模型) + TTS (语音合成) 的流水线模式。这种模式的痛点在于,首先 ASR 模块会引入识别错误,影响后续 LLM 的理解;其次,整个流水线过程增加了延迟,不利于实时交互;最后,语音中的韵律、情感等信息在 ASR 转换成文本的过程中丢失,影响对话的自然度。
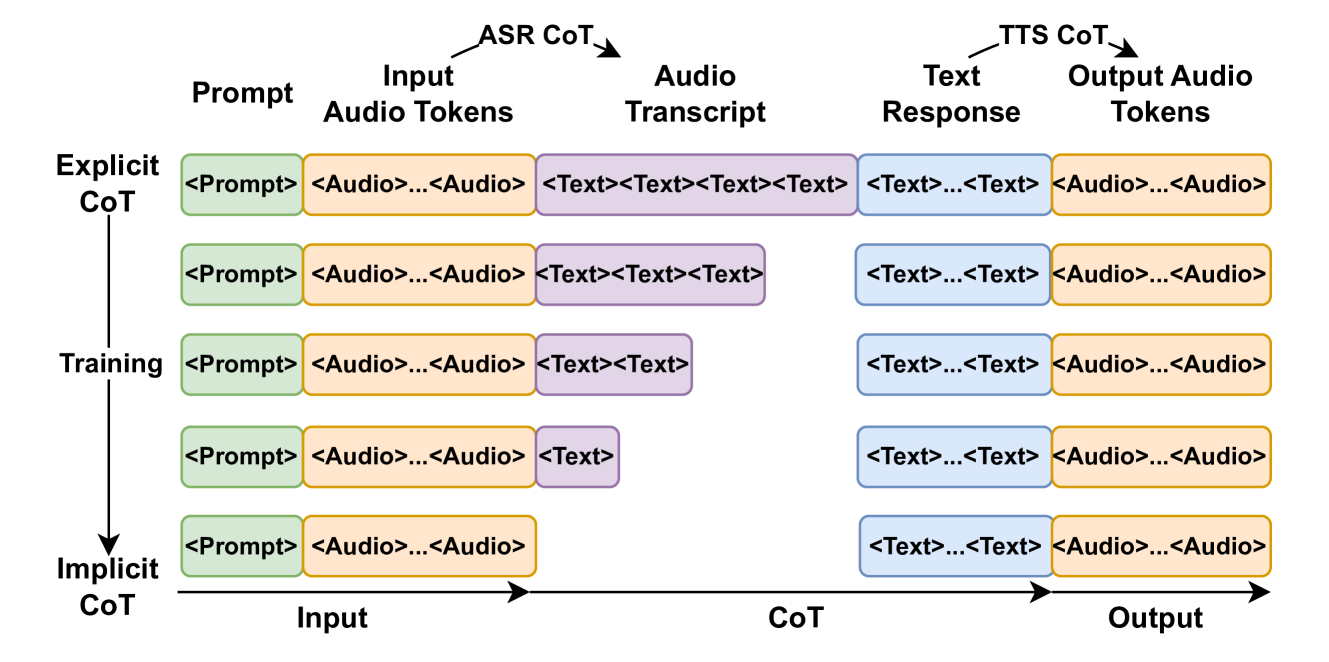
核心思路:论文的核心思路是让语音 LLM 隐式地学习 ASR 的能力,即模型在没有显式 ASR 模块的情况下,直接从语音信号中提取语义信息,并生成语音回复。通过这种方式,可以避免 ASR 模块引入的错误和延迟,并保留语音中的情感信息。
技术框架:整体框架可以描述为:输入语音信号直接进入一个端到端的语音 LLM,该模型内部隐式地学习了 ASR 的功能,可以直接将语音信号映射到语义表示,然后基于该语义表示生成回复的语音信号。该模型可以看作是一个黑盒,输入是语音,输出也是语音,中间的 ASR 过程被隐式地包含在模型内部。
关键创新:最重要的创新点在于“隐式 ASR 思维链”。传统方法依赖显式的 ASR 模块,而本文提出的方法通过训练让 LLM 直接从语音中学习,避免了显式 ASR 模块的引入。这种隐式学习的方式使得模型能够更好地保留语音中的信息,并减少延迟。与现有方法的本质区别在于,它不是一个流水线式的系统,而是一个端到端的系统。
关键设计:论文中提到发布了一个大规模的合成对话数据集,用于训练该语音 LLM。具体模型结构、损失函数等细节未知,但可以推测可能使用了 Transformer 架构,并采用了对比学习或生成对抗网络等方法来提升模型的性能。损失函数的设计可能包括语音重建损失、语义一致性损失等,以保证模型能够准确地从语音中提取语义信息,并生成高质量的语音回复。
🖼️ 关键图片
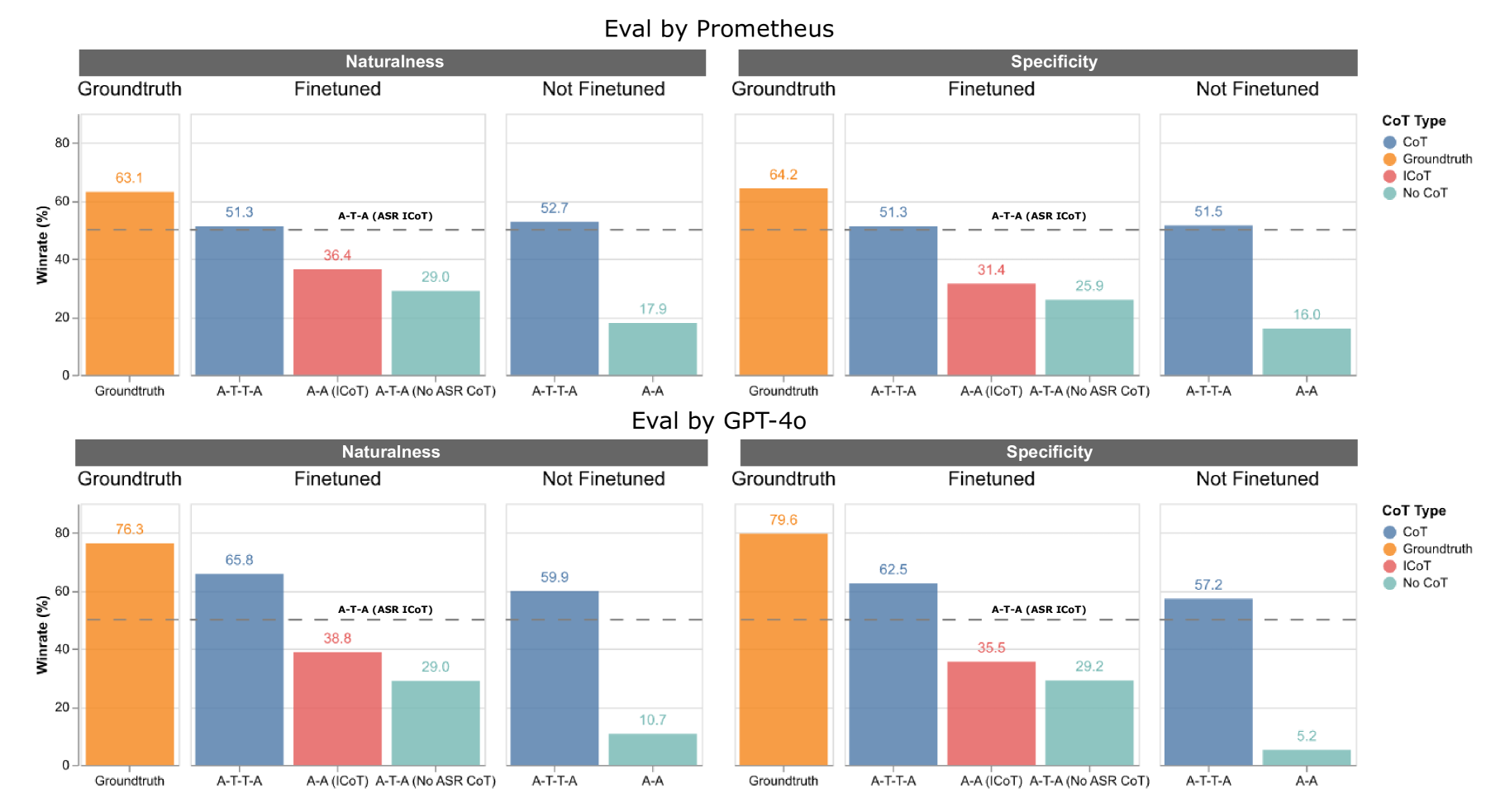
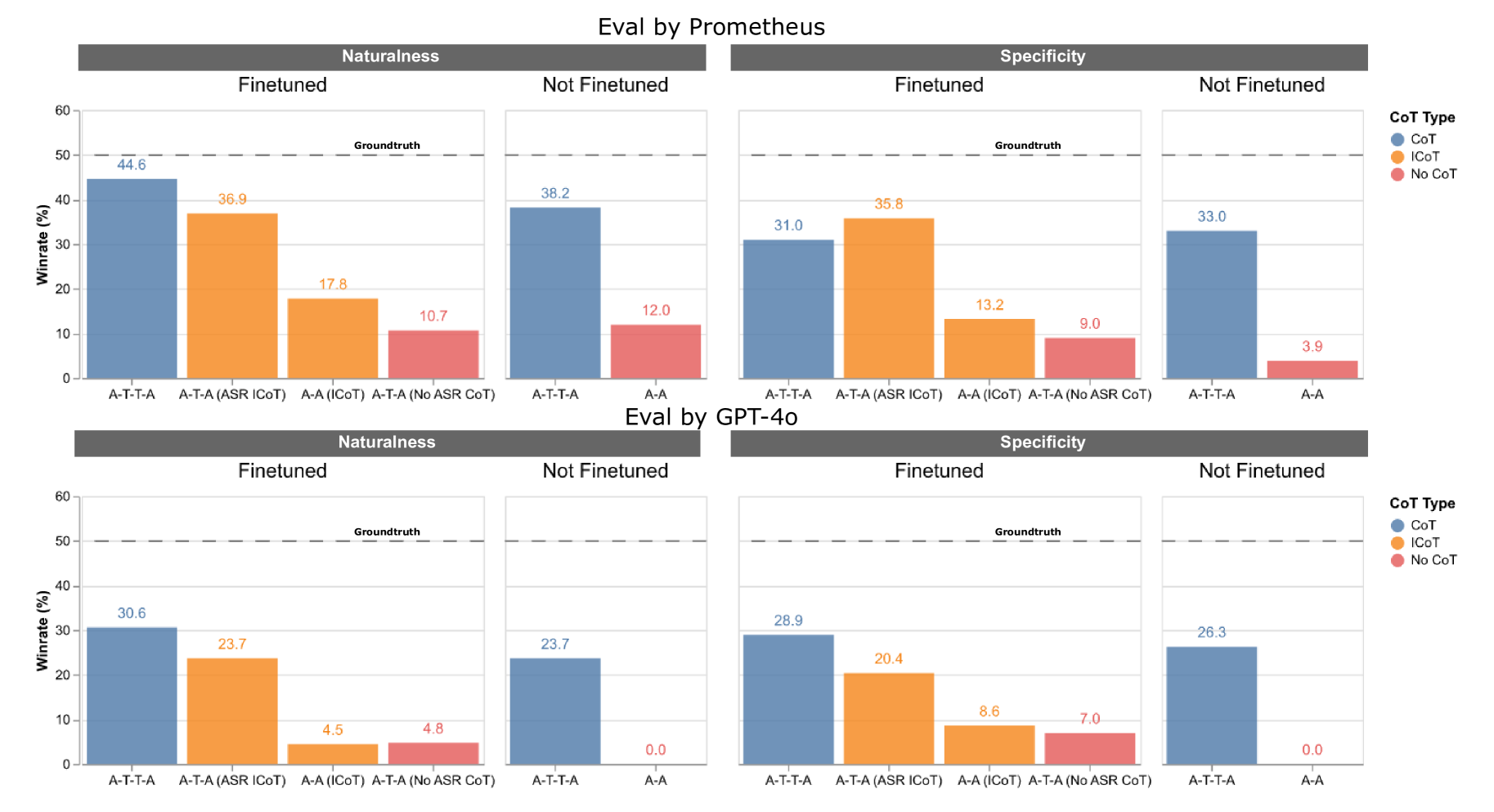
📊 实验亮点
论文的主要亮点在于提出了隐式 ASR 思维链的方法,并构建了一个大规模的合成对话数据集。虽然具体的实验数据未知,但可以推断,该方法在降低延迟、提升语音理解能力和生成语音质量方面都取得了显著的提升。与传统的 ASR-TTS 流水线相比,该方法有望在实时性和自然度方面取得更好的表现。
🎯 应用场景
该研究成果可应用于智能客服、语音助手、实时翻译等领域。通过提升语音对话系统的效率和自然度,可以改善用户体验,并为更自然的人机交互提供技术支持。未来,该技术有望应用于更广泛的场景,例如智能家居、车载系统等,实现更便捷的语音控制和信息获取。
📄 摘要(原文)
Current speech-based LLMs are predominantly trained on extensive ASR and TTS datasets, excelling in tasks related to these domains. However, their ability to handle direct speech-to-speech conversations remains notably constrained. These models often rely on an ASR-to-TTS chain-of-thought pipeline, converting speech into text for processing before generating audio responses, which introduces latency and loses audio features. We propose a method that implicitly internalizes ASR chain of thought into a speech LLM, enhancing its native speech understanding capabilities. Our approach reduces latency and improves the model's native understanding of speech, paving the way for more efficient and natural real-time audio interactions. We also release a large-scale synthetic conversational dataset to facilitate further research.