AutoLLM-CARD: Towards a Description and Landscape of Large Language Models
作者: Shengwei Tian, Lifeng Han, Goran Nenadic
分类: cs.CL, cs.DL
发布日期: 2024-09-25 (更新: 2024-11-24)
备注: ongoing work, technical report
🔗 代码/项目: GITHUB
💡 一句话要点
提出AutoLLM-CARD以解决LLM信息过载问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 信息提取 命名实体识别 关系提取 模型卡 自然语言处理 自动化工具
📋 核心要点
- 现有文献中LLM信息繁多,研究人员面临信息过载,难以高效获取所需信息。
- 本文提出了一种自动生成LLM模型卡的方法,通过NER和RE技术提取关键信息。
- 处理106篇论文,提取11,051句,最终构建了129句与模型名称和许可证相关的数据集。
📝 摘要(中文)
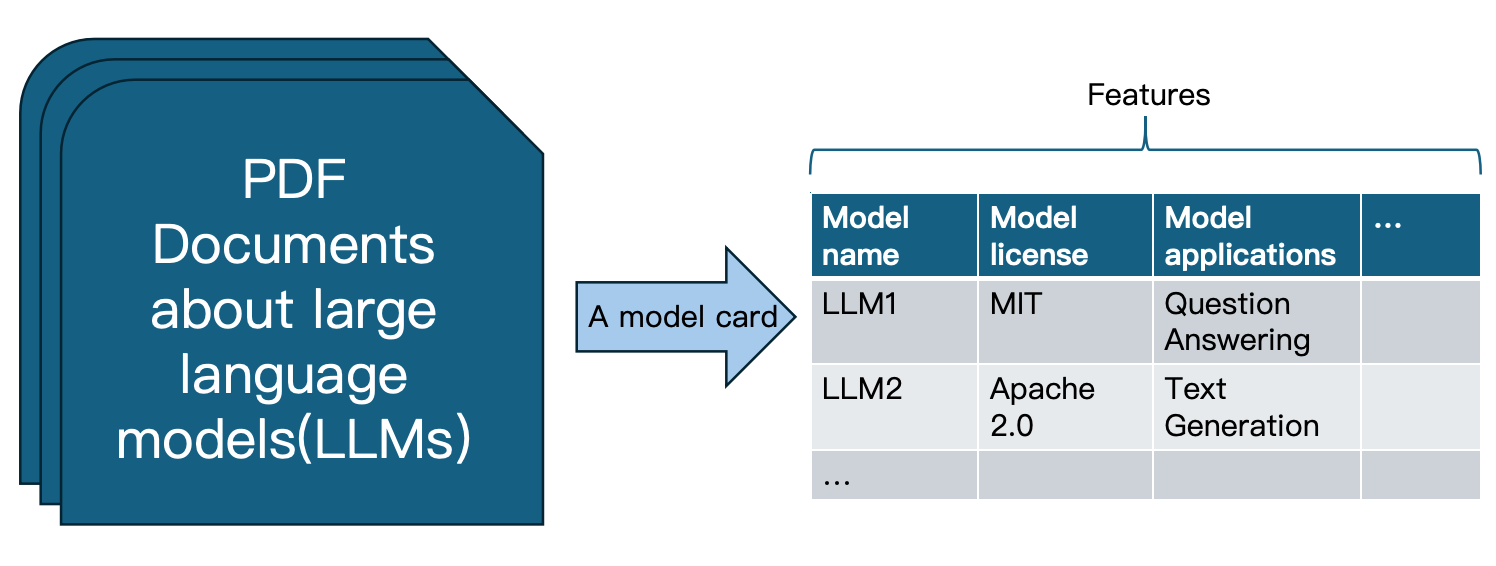
随着自然语言处理领域的快速发展,各种大型语言模型(LLMs)不断涌现,研究人员面临信息过载的挑战。因此,开发一个能够自动提取和组织LLM关键信息的系统显得尤为重要。本文提出了一种从学术论文中自动生成LLM模型卡的方法,利用命名实体识别(NER)和关系提取(RE)技术,帮助研究人员高效获取LLM信息。我们处理了106篇学术论文,通过定义三个字典(LLM名称、许可证和应用),提取了11,051个句子,并经过人工审核构建了数据集。最终的资源为LLM卡的插图提供了相关性,并将代码和发现共享在GitHub上。
🔬 方法详解
问题定义:本文旨在解决研究人员在面对大量LLM相关文献时的信息过载问题。现有方法缺乏有效的自动化工具来提取和组织关键信息,导致研究效率低下。
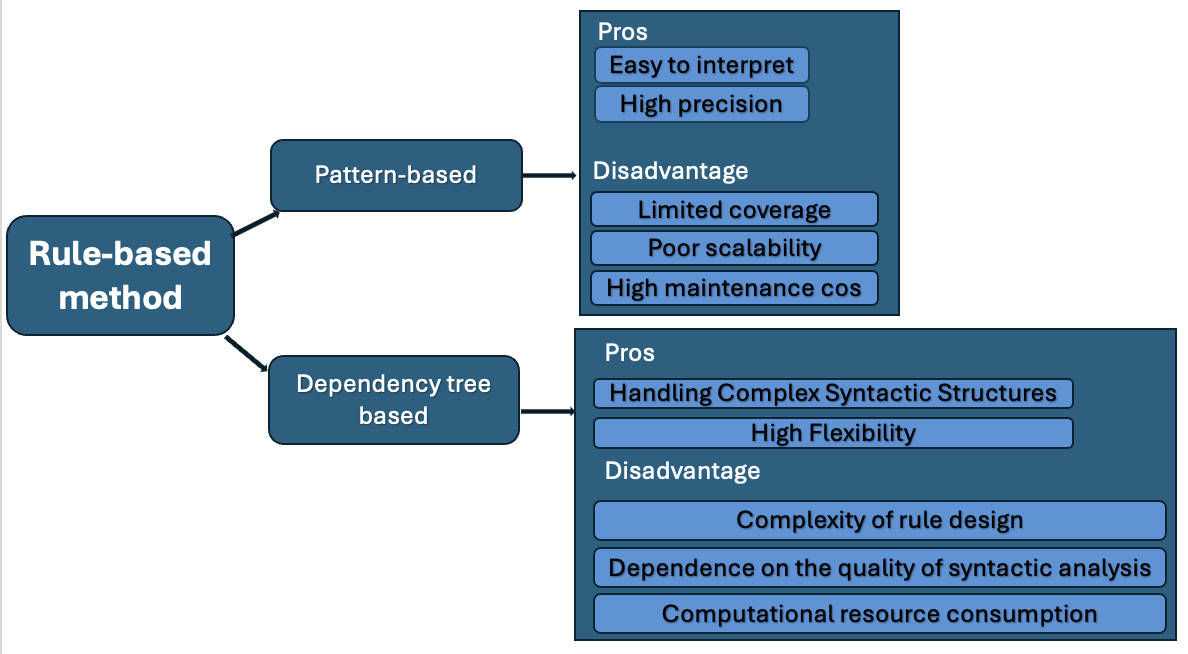
核心思路:论文提出通过命名实体识别(NER)和关系提取(RE)技术,自动从学术论文中提取LLM的名称、许可证和应用等信息,从而生成标准化的LLM模型卡。
技术框架:整体流程包括三个主要模块:首先,定义LLM名称、许可证和应用的字典;其次,通过字典查找提取相关句子;最后,经过人工审核,构建最终的数据集。
关键创新:最重要的创新点在于提出了一种系统化的自动化方法来生成LLM模型卡,显著提高了信息提取的效率和准确性,与传统手动整理方法形成鲜明对比。
关键设计:在技术细节上,定义了三个字典以支持NER和RE的有效实施,确保提取的句子与模型名称、许可证和应用之间具有明确的关联性。
🖼️ 关键图片

📊 实验亮点
实验结果显示,通过自动化提取,成功处理了106篇论文,提取了11,051个句子,最终构建了129个与模型名称和许可证相关的句子。这一方法显著提高了信息提取的效率,减少了人工审核的工作量。
🎯 应用场景
该研究的潜在应用领域包括学术研究、工业界的模型开发和评估等。通过自动生成LLM模型卡,研究人员和开发者能够更快速地获取和比较不同模型的关键信息,从而加速NLP领域的创新和发展。未来,该方法有望扩展到其他类型的模型和领域,进一步提升信息获取的效率。
📄 摘要(原文)
With the rapid growth of the Natural Language Processing (NLP) field, a vast variety of Large Language Models (LLMs) continue to emerge for diverse NLP tasks. As more papers are published, researchers and developers face the challenge of information overload. Thus, developing a system that can automatically extract and organise key information about LLMs from academic papers is particularly important. The standard format for documenting information about LLMs is the LLM model card (\textbf{LLM-Card}). We propose a method for automatically generating LLM model cards from scientific publications. We use Named Entity Recognition (\textbf{NER}) and Relation Extraction (\textbf{RE}) methods that automatically extract key information about LLMs from the papers, helping researchers to access information about LLMs efficiently. These features include model \textit{licence}, model \textit{name}, and model \textit{application}. With these features, we can form a model card for each paper. We processed 106 academic papers by defining three dictionaries -- LLM's name, licence, and application. 11,051 sentences were extracted through dictionary lookup, and the dataset was constructed through manual review of the final selection of 129 sentences with a link between the name and the \textit{licence}, and 106 sentences with a link between the model name and the \textit{application}. The resulting resource is relevant for LLM card illustrations using relational knowledge graphs. Our code and findings can contribute to automatic LLM card generation. Data and code in \textsc{autoLLM-Card} will be shared and freely available at \url{https://github.com/shengwei-tian/dependency-parser-visualization}