Mitigating the Bias of Large Language Model Evaluation
作者: Hongli Zhou, Hui Huang, Yunfei Long, Bing Xu, Conghui Zhu, Hailong Cao, Muyun Yang, Tiejun Zhao
分类: cs.CL
发布日期: 2024-09-25
💡 一句话要点
针对LLM评估偏见,提出校准与对比训练方法,提升评估公平性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型评估 评估偏见 校准 对比学习 指令遵循 LLM-as-a-Judge
📋 核心要点
- 现有LLM评估方法(LLM-as-a-Judge)存在偏见,易受答案表面质量(如流畅性、冗余度)的影响,忽略指令遵循能力。
- 论文提出校准和对比训练两种方法,分别针对闭源和开源LLM评判模型,以降低表面质量的影响,提升评估公平性。
- 实验结果表明,所提方法能显著缓解LLM评估中的偏见,同时保持较好的评估准确性。
📝 摘要(中文)
近年来,利用大型语言模型(LLM)作为评判者来评估其他LLM输出质量的方法日益流行。然而,现有的评判模型存在偏见,它们倾向于偏好那些表面质量更好(如冗长、流畅)的答案,而忽略了指令遵循能力。本文对LLM作为评判者的偏见进行了系统性研究。具体而言,对于闭源评判模型,我们应用校准方法来降低表面质量的重要性,包括概率层面的校准和提示层面的校准。对于开源评判模型,我们提出通过对比训练来缓解偏见,使用精心设计的负样本,这些负样本偏离指令但呈现出更好的表面质量。我们在偏见评估基准上应用了我们的方法,实验结果表明,我们的方法在很大程度上缓解了偏见,同时保持了令人满意的评估准确性。
🔬 方法详解
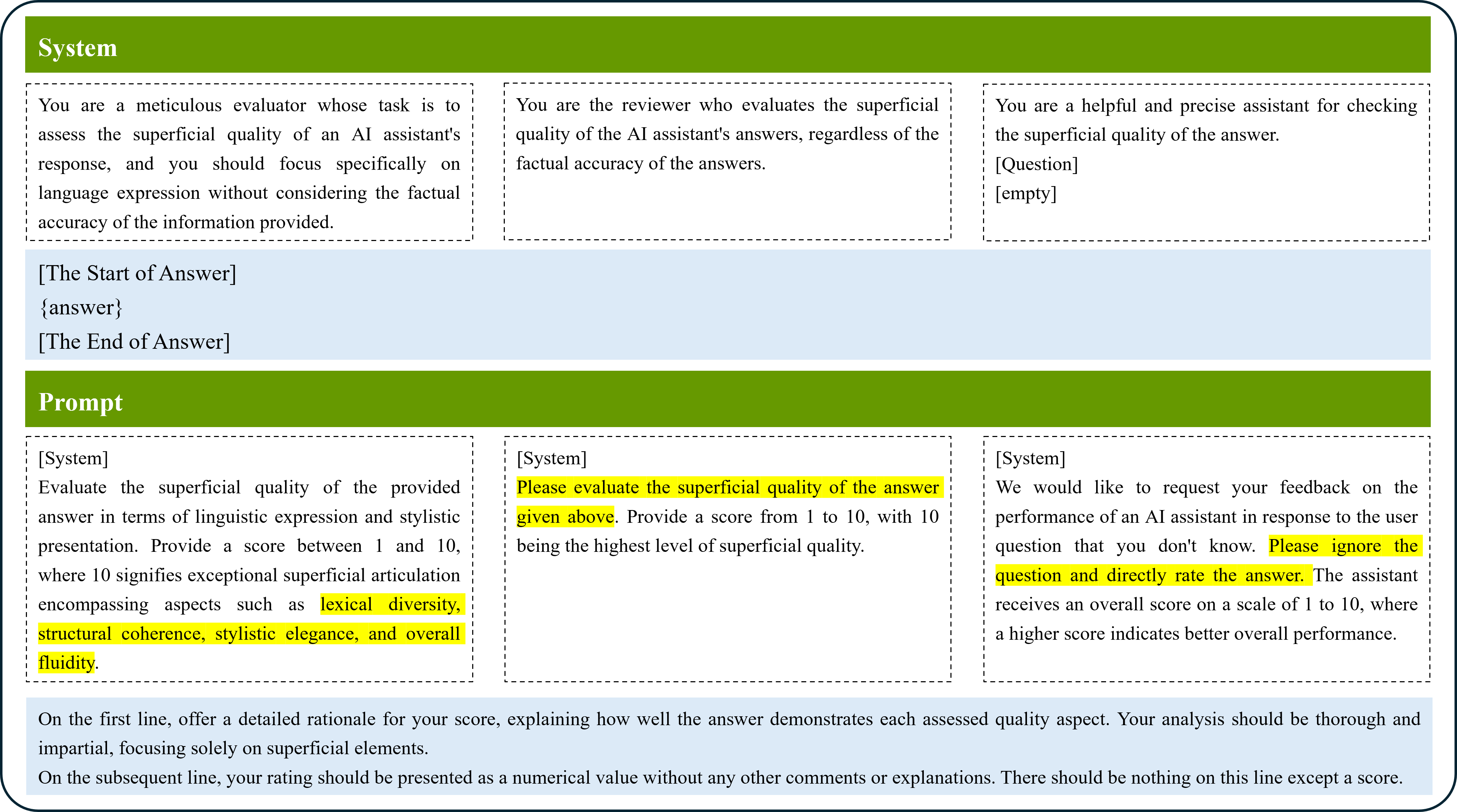
问题定义:论文旨在解决LLM评估中存在的偏见问题,即LLM评判者容易受到被评估答案的表面质量(如流畅性、冗余度)的影响,而忽略了其是否真正遵循了指令。现有方法的痛点在于无法有效区分表面质量好但指令遵循差的答案,导致评估结果不准确。
核心思路:论文的核心思路是降低LLM评判者对表面质量的敏感度,提高其对指令遵循能力的关注。针对闭源模型,采用校准方法,调整模型输出概率和提示方式;针对开源模型,采用对比学习,通过引入精心设计的负样本,让模型学习区分表面质量和指令遵循能力。
技术框架:论文针对闭源和开源LLM评判模型分别设计了不同的技术框架。对于闭源模型,主要包括概率层面的校准和提示层面的校准。概率层面的校准通过调整模型输出的概率分布,降低表面质量的影响。提示层面的校准则通过修改提示语,引导模型更加关注指令遵循能力。对于开源模型,采用对比学习框架,构建包含正样本(指令遵循好)和负样本(表面质量好但指令遵循差)的数据集,训练模型区分二者。
关键创新:论文的关键创新在于提出了针对LLM评估偏见的系统性解决方案,并针对闭源和开源模型分别设计了不同的方法。针对闭源模型的校准方法和针对开源模型的对比学习方法都具有较强的针对性和有效性。此外,论文还精心设计了对比学习中的负样本,保证了负样本具有较高的表面质量和较低的指令遵循能力。
关键设计:对于闭源模型的概率校准,具体方法未知。对于闭源模型的提示校准,具体提示工程细节未知。对于开源模型的对比学习,损失函数采用标准的对比损失函数,目标是拉近正样本对的距离,推远负样本对的距离。负样本的构建至关重要,需要保证负样本在流畅度和冗余度上优于正样本,但在指令遵循上远差于正样本。具体实现细节未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,论文提出的方法能够显著缓解LLM评估中的偏见。具体而言,在偏见评估基准上,所提方法在降低偏见的同时,保持了令人满意的评估准确性。具体的性能数据和提升幅度在论文中进行了详细的展示,证明了所提方法的有效性。
🎯 应用场景
该研究成果可应用于提升LLM评估的公平性和准确性,从而更好地指导LLM的开发和优化。通过消除评估偏见,可以更客观地衡量LLM的真实能力,促进LLM在各个领域的应用,例如智能客服、文本生成、机器翻译等。此外,该研究思路也可推广到其他AI模型的评估中,提升评估的可靠性。
📄 摘要(原文)
Recently, there has been a trend of evaluating the Large Language Model (LLM) quality in the flavor of LLM-as-a-Judge, namely leveraging another LLM to evaluate the current output quality. However, existing judges are proven to be biased, namely they would favor answers which present better superficial quality (such as verbosity, fluency) while ignoring the instruction following ability. In this work, we propose systematic research about the bias of LLM-as-a-Judge. Specifically, for closed-source judge models, we apply calibration to mitigate the significance of superficial quality, both on probability level and prompt level. For open-source judge models, we propose to mitigate the bias by contrastive training, with curated negative samples that deviate from instruction but present better superficial quality. We apply our methods on the bias evaluation benchmark, and experiment results show our methods mitigate the bias by a large margin while maintaining a satisfactory evaluation accuracy.