FMDLlama: Financial Misinformation Detection based on Large Language Models
作者: Zhiwei Liu, Xin Zhang, Kailai Yang, Qianqian Xie, Jimin Huang, Sophia Ananiadou
分类: cs.CL
发布日期: 2024-09-24 (更新: 2025-02-02)
备注: Accepted by The Web Conference (WWW) 2025 Short Paper Track
🔗 代码/项目: GITHUB
💡 一句话要点
FMDLlama:基于Llama3.1微调的金融虚假信息检测大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 金融虚假信息检测 大型语言模型 指令微调 Llama3.1 多任务学习
📋 核心要点
- 金融虚假信息检测至关重要,但现有方法效果有限,且缺乏针对LLM的指令调优数据集和评估基准。
- FMDLlama通过微调Llama3.1,构建多任务指令数据集FMDID和评估基准FMD-B,实现更有效的金融虚假信息检测。
- 实验表明,FMDLlama在FMD-B上优于其他开源LLM和OpenAI产品,验证了其在金融虚假信息检测方面的优越性。
📝 摘要(中文)
社交媒体的兴起使得虚假信息的传播变得更加容易。在金融领域,信息的准确性对于金融市场的各个方面至关重要,这使得金融虚假信息检测(FMD)成为一个亟待解决的问题。大型语言模型(LLM)在各个领域都表现出了出色的性能。然而,目前的研究主要依赖于传统方法,尚未探索LLM在FMD领域的应用。主要原因是缺乏FMD指令调优数据集和评估基准。在本文中,我们提出了FMDLlama,这是第一个基于微调Llama3.1的开源指令跟随LLM,用于FMD任务。同时,我们构建了第一个多任务FMD指令数据集(FMDID)以支持LLM指令调优,以及一个全面的FMD评估基准(FMD-B),包含分类和解释生成任务,以测试LLM的FMD能力。我们将我们的模型与FMD-B上的各种LLM进行了比较,结果表明我们的模型优于其他开源LLM以及OpenAI的产品。该项目可在https://github.com/lzw108/FMD获得。
🔬 方法详解
问题定义:论文旨在解决金融领域虚假信息检测的问题。现有方法主要依赖传统技术,未能充分利用大型语言模型(LLM)的潜力。缺乏专门的FMD指令调优数据集和评估基准是现有方法的关键痛点,阻碍了LLM在该领域的应用。
核心思路:论文的核心思路是利用指令微调(Instruction Tuning)技术,使LLM能够更好地理解和执行FMD任务。通过构建专门的指令数据集和评估基准,引导LLM学习如何识别和解释金融虚假信息。选择Llama3.1作为基础模型,是因为其强大的语言能力和开源特性。
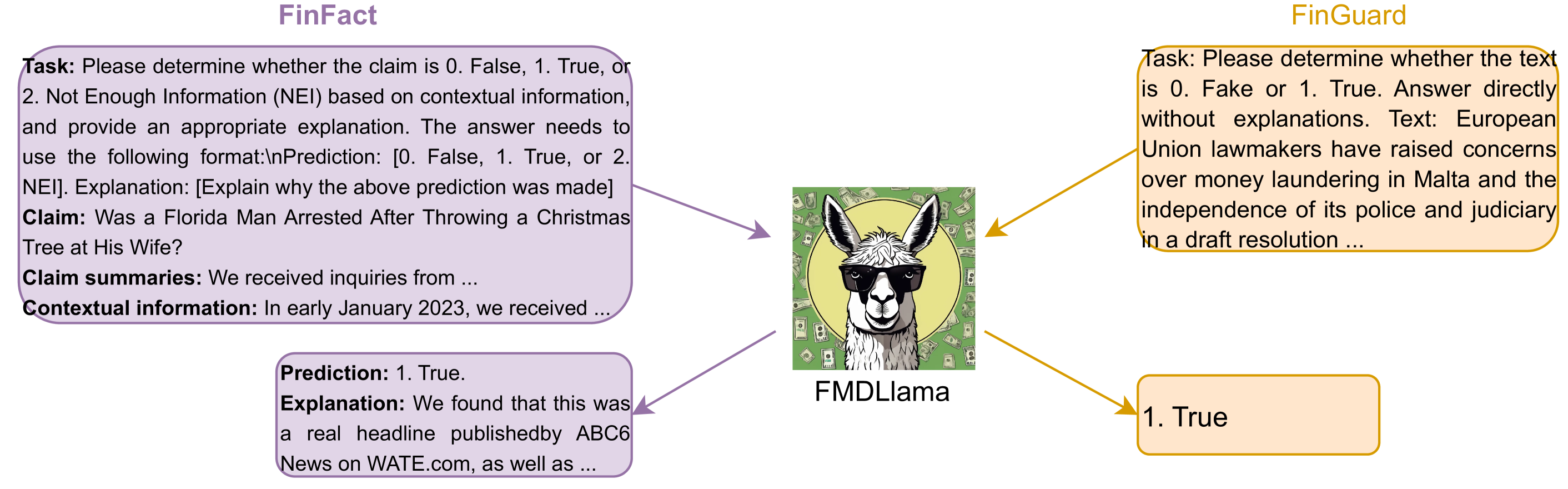
技术框架:FMDLlama的整体框架包括三个主要组成部分:1) 基于Llama3.1的微调模型;2) 多任务FMD指令数据集(FMDID),用于指令调优;3) FMD评估基准(FMD-B),包含分类和解释生成任务。首先,使用FMDID对Llama3.1进行指令微调,使其适应FMD任务。然后,使用FMD-B评估微调后的模型在分类和解释生成方面的性能。
关键创新:论文的关键创新在于:1) 提出了FMDLlama,这是第一个开源的、针对FMD任务进行指令微调的LLM;2) 构建了多任务FMD指令数据集(FMDID),为LLM的指令调优提供了数据支持;3) 设计了全面的FMD评估基准(FMD-B),用于评估LLM在FMD任务中的能力。与现有方法相比,FMDLlama能够更好地利用LLM的语言能力,实现更准确、更可解释的FMD。
关键设计:FMDID包含多种类型的FMD任务,例如新闻分类、声明验证等,并为每个任务设计了相应的指令。FMD-B包含分类和解释生成两种类型的任务,用于全面评估LLM的FMD能力。微调过程中,采用了标准的指令微调技术,并根据FMD任务的特点进行了优化。具体的参数设置和损失函数等技术细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
FMDLlama在FMD-B评估基准上取得了显著的性能提升,优于其他开源LLM以及OpenAI的产品。具体而言,FMDLlama在分类任务和解释生成任务上均取得了最高的准确率和流畅度评分(具体数值未知)。这些结果表明,通过指令微调,LLM能够有效地应用于金融虚假信息检测任务,并取得优异的性能。
🎯 应用场景
该研究成果可应用于金融风险管理、投资者保护、舆情监控等领域。通过自动检测和识别金融虚假信息,可以帮助监管机构及时发现和处理违规行为,保护投资者免受欺诈和误导,维护金融市场的稳定和健康发展。未来,该技术还可以扩展到其他领域,例如医疗、政治等,以应对各种类型的虚假信息挑战。
📄 摘要(原文)
The emergence of social media has made the spread of misinformation easier. In the financial domain, the accuracy of information is crucial for various aspects of financial market, which has made financial misinformation detection (FMD) an urgent problem that needs to be addressed. Large language models (LLMs) have demonstrated outstanding performance in various fields. However, current studies mostly rely on traditional methods and have not explored the application of LLMs in the field of FMD. The main reason is the lack of FMD instruction tuning datasets and evaluation benchmarks. In this paper, we propose FMDLlama, the first open-sourced instruction-following LLMs for FMD task based on fine-tuning Llama3.1 with instruction data, the first multi-task FMD instruction dataset (FMDID) to support LLM instruction tuning, and a comprehensive FMD evaluation benchmark (FMD-B) with classification and explanation generation tasks to test the FMD ability of LLMs. We compare our models with a variety of LLMs on FMD-B, where our model outperforms other open-sourced LLMs as well as OpenAI's products. This project is available at https://github.com/lzw108/FMD.