SLIMER-IT: Zero-Shot NER on Italian Language
作者: Andrew Zamai, Leonardo Rigutini, Marco Maggini, Andrea Zugarini
分类: cs.CL, cs.IR
发布日期: 2024-09-24 (更新: 2024-11-14)
💡 一句话要点
提出SLIMER-IT,一种面向意大利语的零样本命名实体识别方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 命名实体识别 意大利语 指令调优 提示工程 大型语言模型 自然语言处理
📋 核心要点
- 传统NER方法依赖大量标注数据,泛化能力弱,难以适应新领域和实体类型。
- SLIMER-IT利用指令调优和提示工程,提升LLM在意大利语零样本NER任务上的性能。
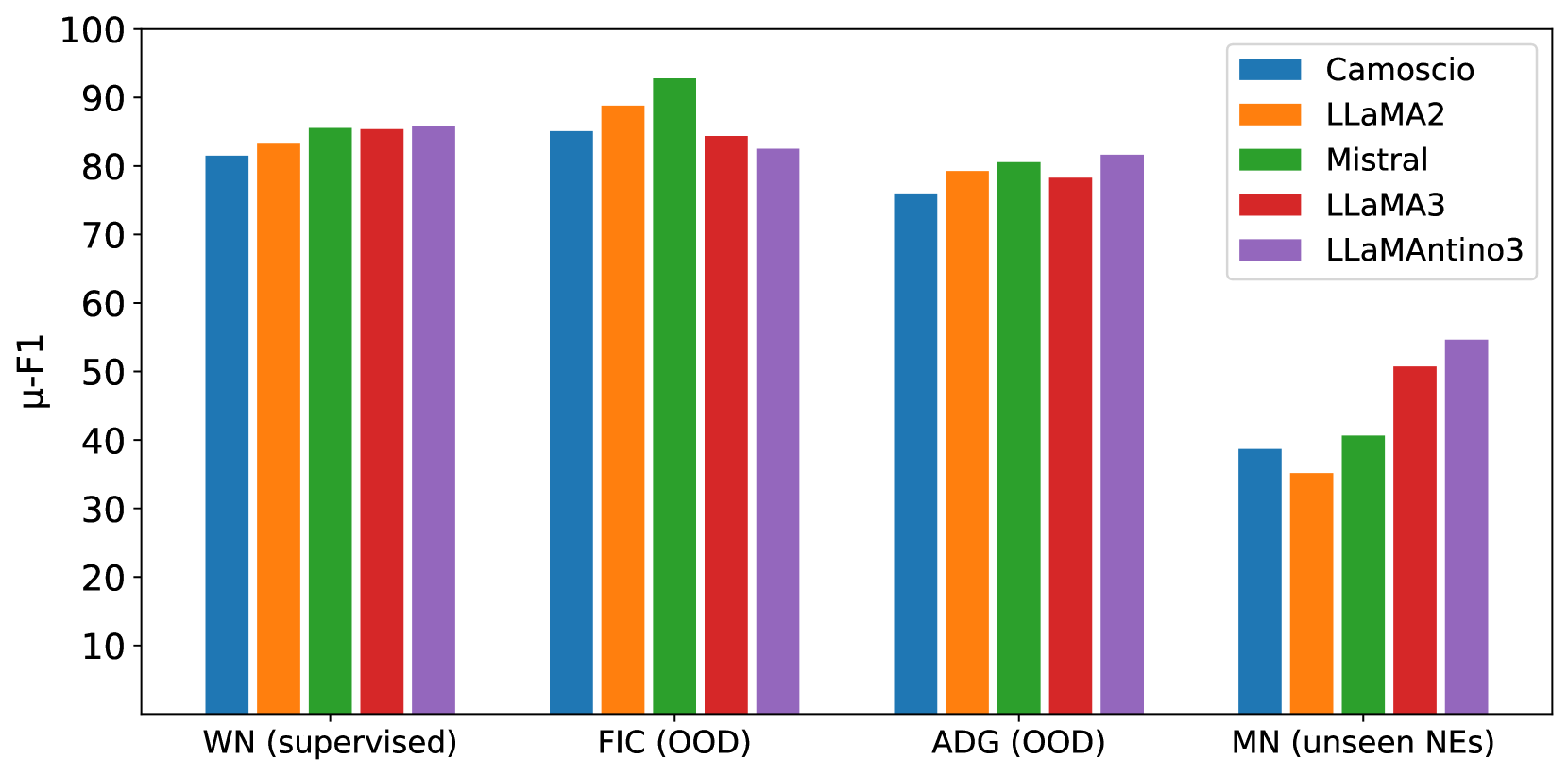
- 实验表明,SLIMER-IT在未见过的实体标签上优于其他先进模型,验证了其有效性。
📝 摘要(中文)
传统的命名实体识别(NER)方法通常将任务定义为BIO序列标注问题。尽管这些系统在特定任务上表现出色,但它们需要大量的标注数据,并且难以泛化到分布外的输入领域和未见过的实体类型。相反,大型语言模型(LLMs)已经展示出强大的零样本能力。虽然一些工作已经解决了英语中的零样本NER问题,但在其他语言方面的工作还很少。在本文中,我们定义了一个零样本NER的评估框架,并将其应用于意大利语。此外,我们介绍了SLIMER-IT,它是SLIMER的意大利语版本,SLIMER是一种利用定义和指南丰富提示的指令调优方法,用于零样本NER。与其他最先进模型的比较表明,SLIMER-IT在从未见过的实体标签上具有优越性。
🔬 方法详解
问题定义:论文旨在解决意大利语零样本命名实体识别(NER)问题。现有方法,如基于BIO序列标注的模型,需要大量标注数据,且难以泛化到未见过的实体类型和领域。这限制了它们在实际应用中的灵活性和适应性。
核心思路:论文的核心思路是利用大型语言模型(LLMs)的零样本学习能力,通过指令调优(Instruction Tuning)和提示工程(Prompt Engineering)来引导模型识别意大利语中的命名实体,而无需针对特定实体类型进行训练。
技术框架:SLIMER-IT是基于SLIMER框架的意大利语版本。其主要流程包括:1) 构建包含实体定义和识别指南的提示(Prompt);2) 使用这些提示对LLM进行指令调优,使其能够理解并执行NER任务;3) 在测试阶段,将包含待识别文本的提示输入到调优后的LLM中,模型直接输出识别结果。
关键创新:该方法最重要的创新点在于利用指令调优和提示工程,使得LLM能够在零样本场景下有效地执行意大利语NER任务。与传统的监督学习方法相比,SLIMER-IT无需标注数据,具有更强的泛化能力和适应性。
关键设计:SLIMER-IT的关键设计包括:1) 精心设计的提示模板,包含实体类型的定义和识别规则;2) 使用意大利语数据进行指令调优,以提升模型对意大利语的理解能力;3) 采用合适的LLM作为基础模型,例如基于Transformer的模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SLIMER-IT在意大利语零样本NER任务上取得了显著的性能提升,尤其是在识别未见过的实体标签时。与其他最先进的模型相比,SLIMER-IT展现出更强的泛化能力和鲁棒性,验证了指令调优和提示工程在零样本NER中的有效性。
🎯 应用场景
SLIMER-IT可应用于多种场景,如信息抽取、知识图谱构建、舆情分析等。在医疗、金融、法律等领域,该方法能够快速识别和提取关键信息,无需大量人工标注,降低了开发成本,加速了应用落地。未来,该方法可扩展到更多语言和领域,促进跨语言信息处理的发展。
📄 摘要(原文)
Traditional approaches to Named Entity Recognition (NER) frame the task into a BIO sequence labeling problem. Although these systems often excel in the downstream task at hand, they require extensive annotated data and struggle to generalize to out-of-distribution input domains and unseen entity types. On the contrary, Large Language Models (LLMs) have demonstrated strong zero-shot capabilities. While several works address Zero-Shot NER in English, little has been done in other languages. In this paper, we define an evaluation framework for Zero-Shot NER, applying it to the Italian language. Furthermore, we introduce SLIMER-IT, the Italian version of SLIMER, an instruction-tuning approach for zero-shot NER leveraging prompts enriched with definition and guidelines. Comparisons with other state-of-the-art models, demonstrate the superiority of SLIMER-IT on never-seen-before entity tags.