Enhancing Text-to-SQL Capabilities of Large Language Models via Domain Database Knowledge Injection
作者: Xingyu Ma, Xin Tian, Lingxiang Wu, Xuepeng Wang, Xueming Tang, Jinqiao Wang
分类: cs.CL, cs.AI
发布日期: 2024-09-24 (更新: 2025-02-25)
备注: This paper has been accepted by ECAI 2024
💡 一句话要点
提出领域数据库知识注入方法,提升大语言模型在Text-to-SQL任务中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Text-to-SQL 大语言模型 知识注入 领域知识 数据库 语义解析 预训练 微调
📋 核心要点
- 大语言模型在Text-to-SQL任务中面临幻觉问题和缺乏领域数据库知识的挑战,导致SQL生成错误。
- 论文提出知识注入方法,通过整合领域数据库知识来增强LLMs对数据库模式的理解,提升Text-to-SQL性能。
- 实验表明,在领域知识上预训练并在下游任务微调能显著提升EX和EM指标,并具有良好的泛化能力。
📝 摘要(中文)
本文提出了一种知识注入方法,旨在提升大语言模型(LLMs)在Text-to-SQL任务中的能力。由于LLMs存在幻觉问题,并且缺乏领域特定的数据库知识(如表模式和单元格值),导致其在生成表名、列名以及将值匹配到SQL语句中的正确列时容易出错。该方法通过整合先验知识来增强LLMs对模式内容的理解,从而提高其在Text-to-SQL任务中的性能。实验结果表明,在领域特定的数据库知识上预训练LLMs,并在下游Text-to-SQL任务上进行微调,可以显著提高各种模型的执行匹配(EX)和精确匹配(EM)指标,有效减少生成列名和将值匹配到列时的错误。此外,知识注入后的模型可以应用于多个下游Text-to-SQL任务,证明了该方法的通用性。
🔬 方法详解
问题定义:论文旨在解决大语言模型在Text-to-SQL任务中由于缺乏领域数据库知识而产生的错误,例如错误的表名、列名生成以及值与列的错误匹配。现有方法难以有效利用数据库模式信息,导致生成SQL语句的准确性不高。
核心思路:论文的核心思路是通过知识注入,将领域特定的数据库知识(如表模式和单元格值)融入到大语言模型的预训练过程中,从而增强模型对数据库结构的理解能力。这样,模型在生成SQL语句时就能更好地利用数据库信息,减少错误。
技术框架:该方法主要包含两个阶段:1) 领域知识预训练阶段:使用领域特定的数据库知识对LLM进行预训练,使其初步掌握数据库模式和数据分布。2) 下游任务微调阶段:在Text-to-SQL数据集上对预训练后的LLM进行微调,使其能够根据文本描述生成正确的SQL语句。
关键创新:该方法最重要的创新点在于将领域数据库知识融入到大语言模型的预训练过程中,而不是仅仅在微调阶段利用这些信息。这种预训练方式能够更有效地提升模型对数据库结构的理解能力,从而显著提高Text-to-SQL任务的性能。
关键设计:具体的知识注入方式未知,论文中可能涉及特定的数据格式、训练策略或损失函数设计,以便更好地将数据库知识融入到LLM中。这些细节对于复现和进一步改进该方法至关重要,但摘要中未明确说明。
🖼️ 关键图片
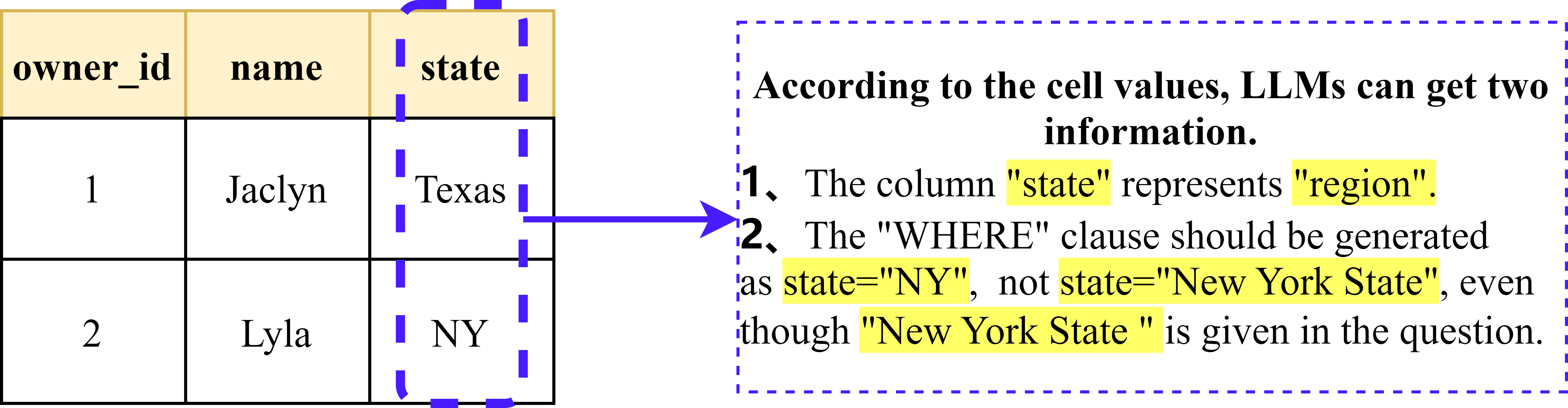


📊 实验亮点
实验结果表明,通过领域数据库知识注入,LLMs在Text-to-SQL任务中的执行匹配(EX)和精确匹配(EM)指标得到了显著提升。具体的性能数据和对比基线在摘要中未给出,但强调了该方法在减少列名生成错误和值匹配错误方面的有效性,并展示了其在多个下游任务中的泛化能力。
🎯 应用场景
该研究成果可广泛应用于智能问答系统、数据分析平台和数据库管理工具等领域。通过提升Text-to-SQL的准确性,用户可以使用自然语言更方便地查询和分析数据库,降低了使用数据库的技术门槛,提高了数据分析的效率。未来,该方法有望进一步扩展到更复杂的数据库查询和数据处理任务中。
📄 摘要(原文)
Text-to-SQL is a subtask in semantic parsing that has seen rapid progress with the evolution of Large Language Models (LLMs). However, LLMs face challenges due to hallucination issues and a lack of domain-specific database knowledge(such as table schema and cell values). As a result, they can make errors in generating table names, columns, and matching values to the correct columns in SQL statements. This paper introduces a method of knowledge injection to enhance LLMs' ability to understand schema contents by incorporating prior knowledge. This approach improves their performance in Text-to-SQL tasks. Experimental results show that pre-training LLMs on domain-specific database knowledge and fine-tuning them on downstream Text-to-SQL tasks significantly improves the Execution Match (EX) and Exact Match (EM) metrics across various models. This effectively reduces errors in generating column names and matching values to the columns. Furthermore, the knowledge-injected models can be applied to many downstream Text-to-SQL tasks, demonstrating the generalizability of the approach presented in this paper.