A Zero-Shot Open-Vocabulary Pipeline for Dialogue Understanding
作者: Abdulfattah Safa, Gözde Gül Şahin
分类: cs.CL, cs.AI
发布日期: 2024-09-24 (更新: 2025-03-07)
备注: Accepted to NAACL 2025
💡 一句话要点
提出零样本开放词汇对话理解流水线,提升任务型对话系统性能。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话状态跟踪 零样本学习 开放词汇 任务型对话 大型语言模型
📋 核心要点
- 现有对话状态跟踪方法依赖预定义本体和标注数据,泛化能力受限,难以适应新槽值。
- 提出零样本开放词汇对话理解流水线,将DST重构为问答任务,并采用自精炼提示。
- 实验表明,该方法在Multi-WOZ 2.1数据集上JGA提升高达20%,并显著减少LLM API请求。
📝 摘要(中文)
本文提出了一种零样本、开放词汇的对话理解系统,该系统将领域分类和对话状态跟踪(DST)集成到一个流水线中。现有的DST方法大多在预定义的本体中工作,并且依赖于已标注的领域标签,难以适应新的槽值。虽然基于大型语言模型(LLM)的系统在零样本DST方面表现出潜力,但它们要么需要大量的计算资源,要么性能不如现有的完全训练系统,限制了它们的实用性。为了解决这些限制,本文将DST重新定义为问答任务,以适应能力较弱的模型,并采用自精炼提示来提高模型的适应性。该系统不依赖于本体中定义的固定槽值,从而允许系统动态适应。与现有SOTA方法相比,该方法在Multi-WOZ 2.1等数据集上提供了高达20%的联合目标准确率(JGA)提升,同时减少了高达90%的LLM API请求。
🔬 方法详解
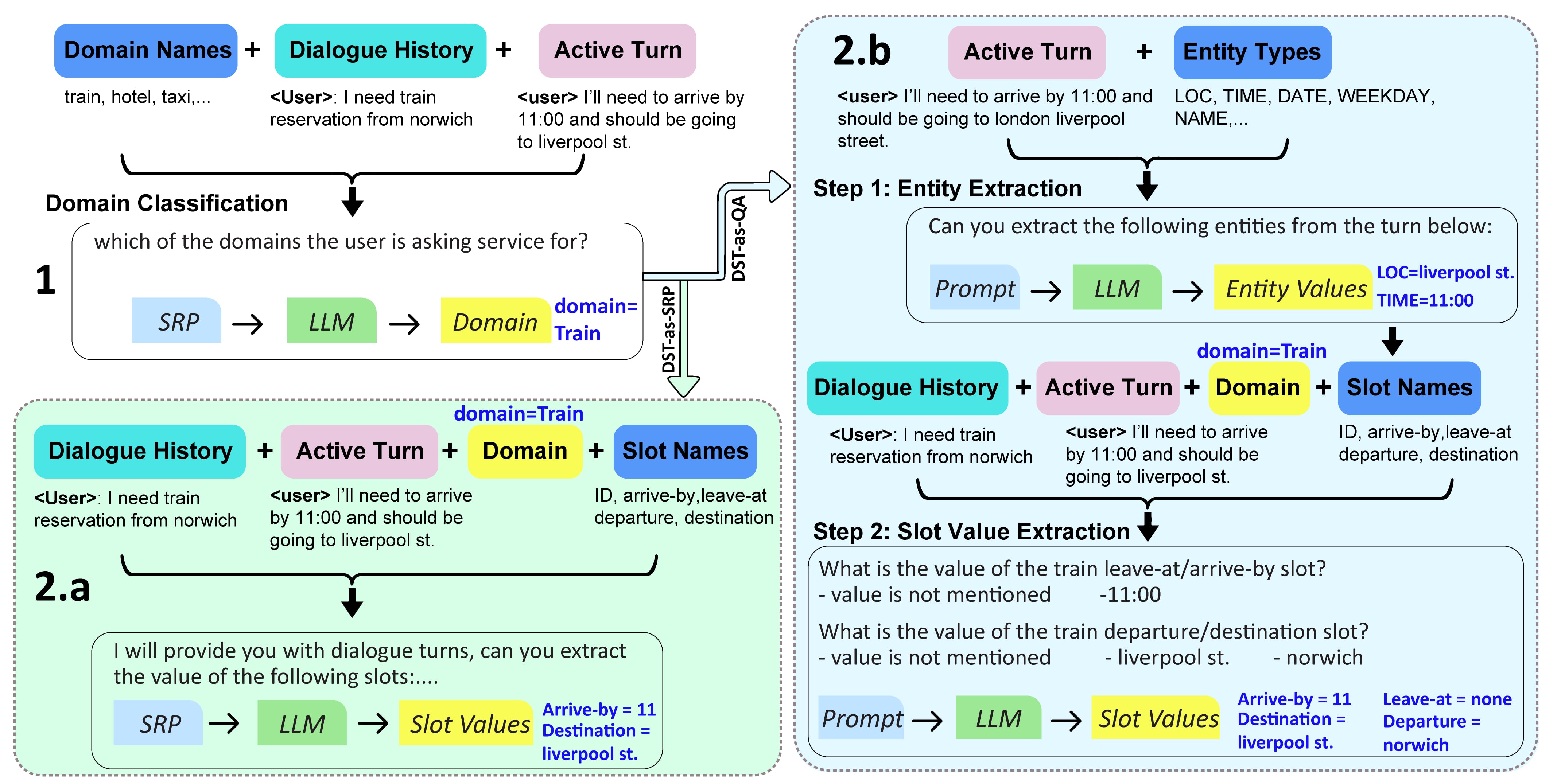
问题定义:现有对话状态跟踪(DST)方法主要依赖于预定义的本体和人工标注的领域标签,这限制了它们在新槽值和领域上的泛化能力。即使是基于大型语言模型(LLM)的零样本DST方法,也面临着计算资源需求高或性能不足的问题,难以实际应用。因此,需要一种能够动态适应新槽值,且计算效率高的零样本DST解决方案。
核心思路:本文的核心思路是将DST任务重新定义为一个问答(QA)任务,并利用自精炼提示来提高模型的适应性。通过将DST转化为QA,可以使用较小的模型,降低计算成本。自精炼提示则允许模型在没有显式监督的情况下,逐步改进其预测结果,从而更好地适应开放词汇场景。
技术框架:该系统包含领域分类和DST两个主要模块,集成在一个流水线中。首先,使用领域分类器确定当前对话属于哪个领域。然后,将DST任务转化为一系列问答题,例如“用户想要什么类型的餐厅?”。这些问题被输入到语言模型中,模型生成相应的答案,即槽值。对于更复杂的场景,采用自精炼提示,让模型迭代地改进其答案。
关键创新:该方法最重要的创新点在于其零样本和开放词汇特性。它不依赖于预定义的本体和人工标注,能够动态适应新的槽值和领域。此外,通过将DST转化为QA任务,并采用自精炼提示,该方法能够在计算资源有限的情况下,实现较高的性能。
关键设计:具体的技术细节包括:(1) 使用预训练语言模型作为QA系统的基础模型;(2) 设计合适的提示模板,将DST任务转化为QA问题;(3) 实现自精炼提示机制,例如,让模型根据其自身的预测结果生成新的提示,并再次进行预测;(4) 优化领域分类器的性能,确保准确的领域识别。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在Multi-WOZ 2.1数据集上,联合目标准确率(JGA)相比现有SOTA方法提升高达20%。同时,该方法显著降低了对LLM API的请求次数,减少了高达90%,表明其具有更高的计算效率和更低的成本。
🎯 应用场景
该研究成果可应用于各种任务型对话系统,例如智能客服、虚拟助手和自动订票系统。它能够提升这些系统在处理未知领域和槽值时的鲁棒性和灵活性,从而改善用户体验。此外,该方法在资源受限环境下的应用潜力,使其在移动设备和嵌入式系统中具有实际价值。
📄 摘要(原文)
Dialogue State Tracking (DST) is crucial for understanding user needs and executing appropriate system actions in task-oriented dialogues. Majority of existing DST methods are designed to work within predefined ontologies and assume the availability of gold domain labels, struggling with adapting to new slots values. While Large Language Models (LLMs)-based systems show promising zero-shot DST performance, they either require extensive computational resources or they underperform existing fully-trained systems, limiting their practicality. To address these limitations, we propose a zero-shot, open-vocabulary system that integrates domain classification and DST in a single pipeline. Our approach includes reformulating DST as a question-answering task for less capable models and employing self-refining prompts for more adaptable ones. Our system does not rely on fixed slot values defined in the ontology allowing the system to adapt dynamically. We compare our approach with existing SOTA, and show that it provides up to 20% better Joint Goal Accuracy (JGA) over previous methods on datasets like Multi-WOZ 2.1, with up to 90% fewer requests to the LLM API.