Small Language Models: Survey, Measurements, and Insights
作者: Zhenyan Lu, Xiang Li, Dongqi Cai, Rongjie Yi, Fangming Liu, Xiwen Zhang, Nicholas D. Lane, Mengwei Xu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-09-24 (更新: 2025-02-26)
💡 一句话要点
全面评测与分析小型语言模型,洞察设备端智能的未来
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小型语言模型 设备端智能 基准测试 模型评估 Transformer 自然语言处理 模型优化
📋 核心要点
- 大型语言模型研究火热,但小型语言模型在智能设备上的应用潜力被忽视,需要更多关注。
- 论文系统性地调研、评估和分析了现有小型语言模型,旨在促进设备端智能的发展。
- 通过基准测试,论文深入分析了小型语言模型的性能和资源消耗,为未来研究提供指导。
📝 摘要(中文)
本文针对参数量在100M到5B之间的、基于Transformer解码器结构的开源小型语言模型(SLM)进行了全面的调研、评估和分析。与主要部署在数据中心和云环境中的大型语言模型(LLM)不同,SLM旨在使机器智能更易于访问、负担得起且高效,从而更好地服务于日常任务。论文调研了70个最先进的开源SLM,并从架构、训练数据集和训练算法三个维度分析了它们的技术创新。此外,还评估了它们在常识推理、数学、上下文学习和长文本处理等多个领域的能力。为了深入了解SLM在设备上的运行时成本,论文还对其推理延迟和内存占用进行了基准测试。通过对基准测试数据的深入分析,为该领域的研究提供了有价值的见解。
🔬 方法详解
问题定义:现有研究主要集中在大型语言模型上,而忽略了小型语言模型在智能设备上的广泛应用。小型语言模型在资源受限的设备上部署面临推理延迟高、内存占用大等挑战,需要对其性能和效率进行深入评估和优化。
核心思路:通过系统性的调研、基准测试和分析,全面了解现有小型语言模型的优缺点,并为未来的研究提供指导。核心在于从架构、训练数据、训练算法三个维度分析模型,并结合实际应用场景评估性能。
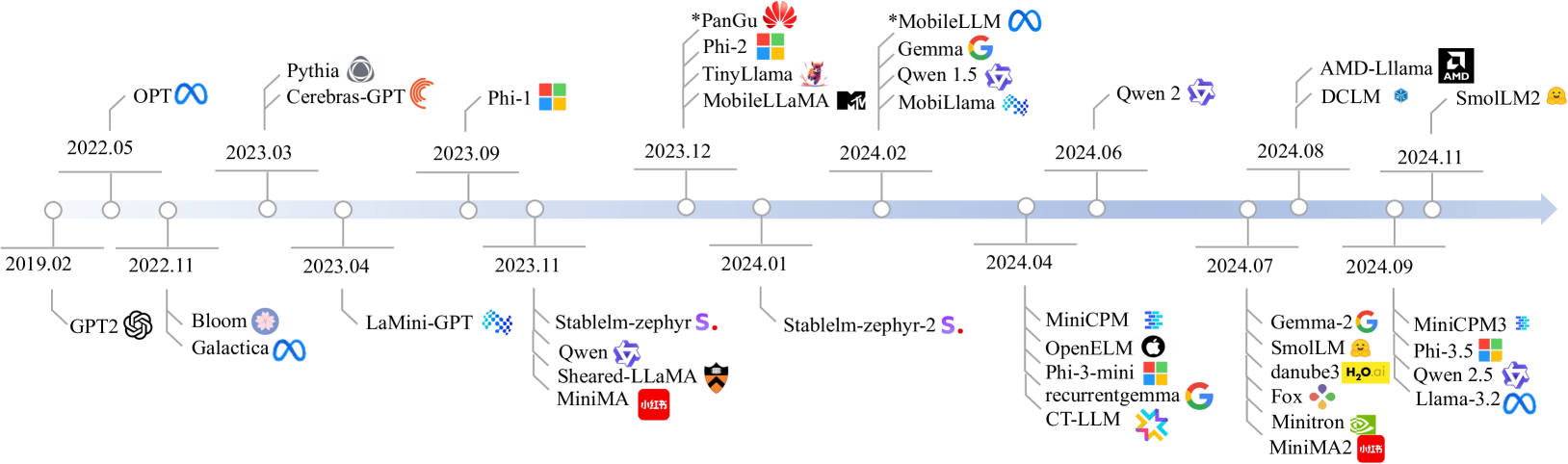
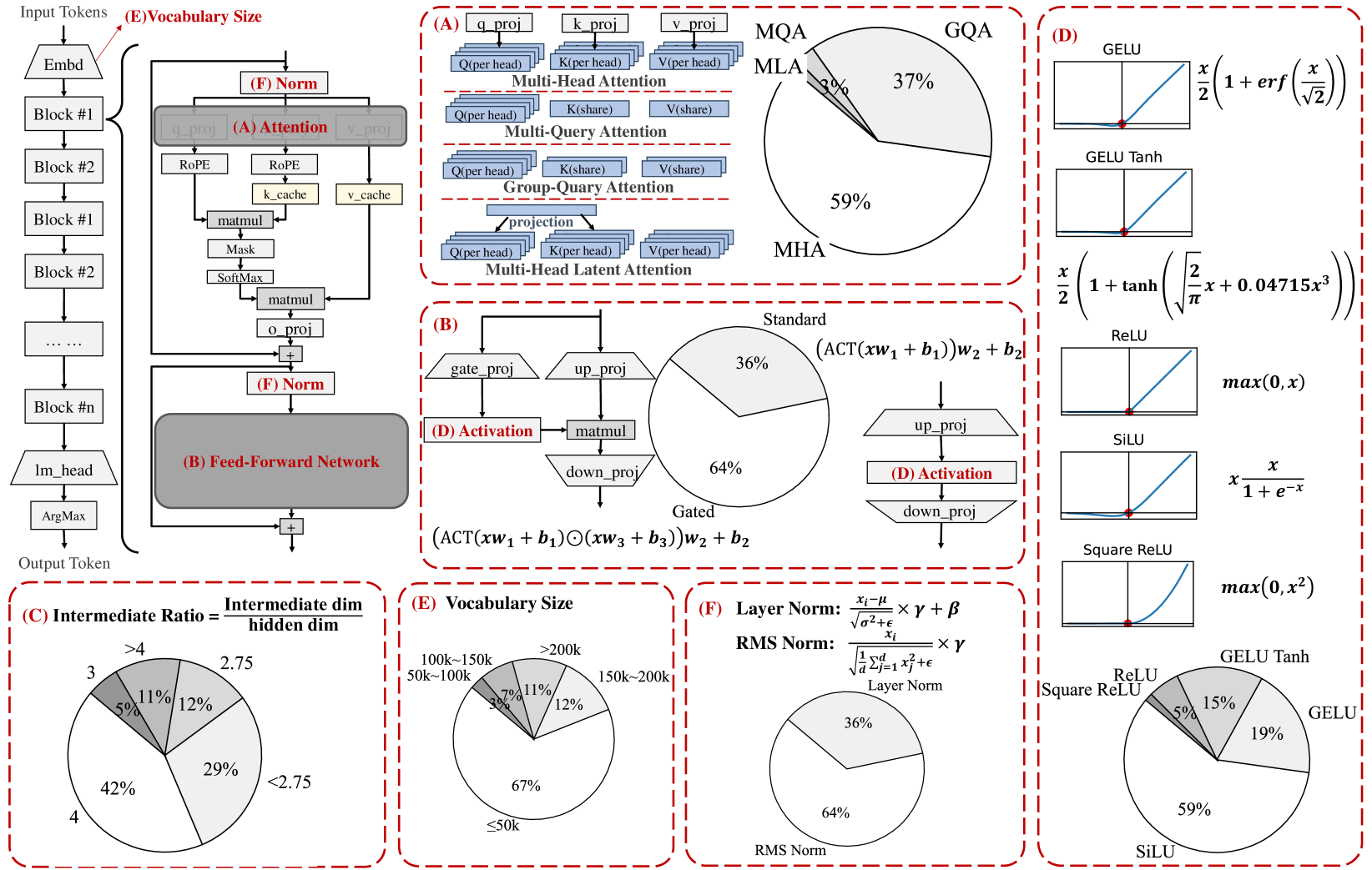
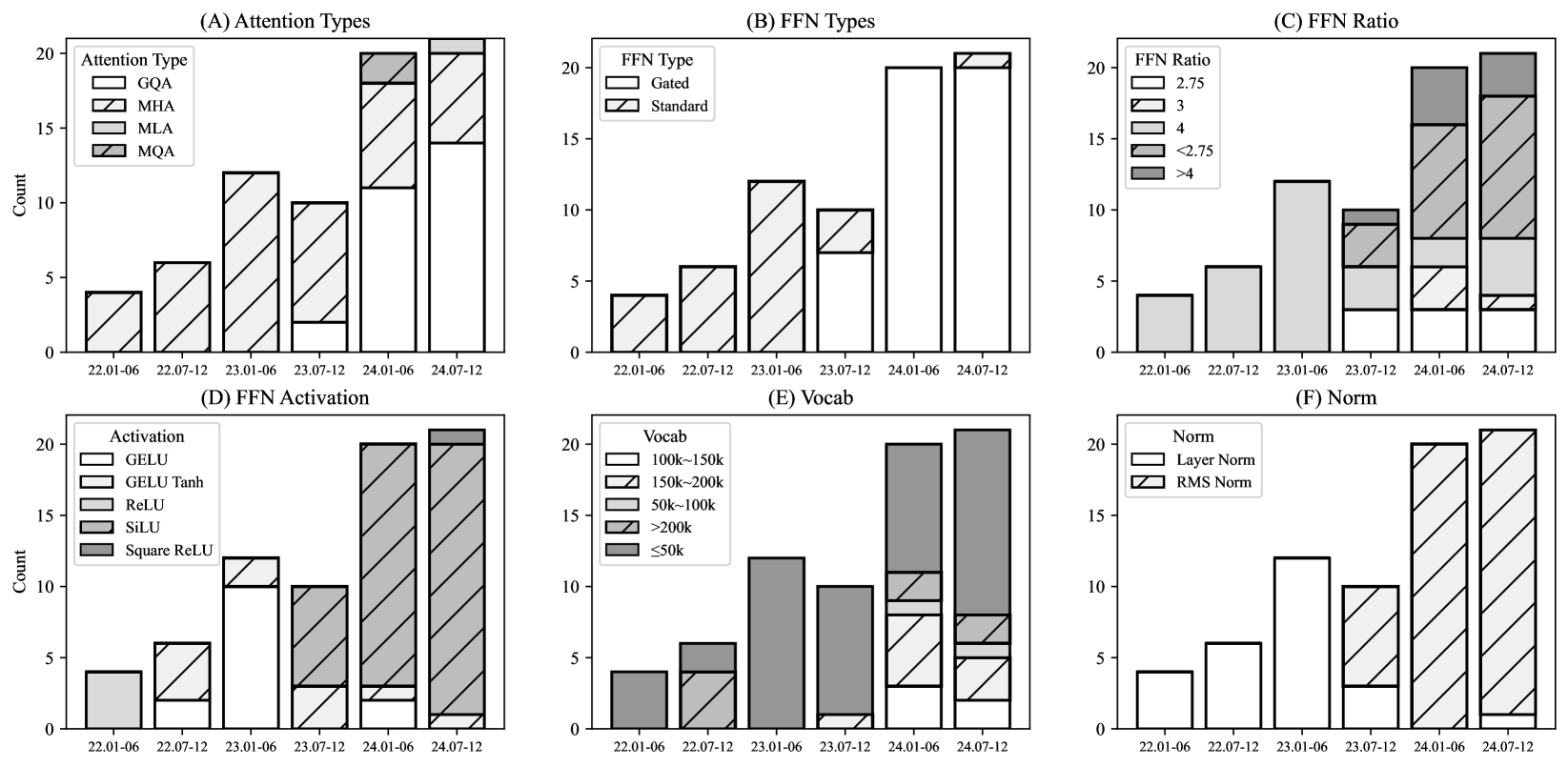
技术框架:论文首先调研了70个开源的、基于Transformer解码器结构的小型语言模型。然后,从架构、训练数据集和训练算法三个维度对这些模型进行分类和分析。接着,在常识推理、数学、上下文学习和长文本处理等多个领域评估这些模型的性能。最后,通过基准测试测量这些模型的推理延迟和内存占用。
关键创新:该研究的创新之处在于对小型语言模型进行了全面的、系统性的分析和评估,并提供了详细的基准测试数据。这为研究人员了解小型语言模型的现状和未来的发展方向提供了有价值的参考。此外,论文还从架构、训练数据和训练算法三个维度分析了模型的创新点,有助于研究人员更好地理解模型的内部机制。
关键设计:论文关注参数量在100M到5B之间的模型,并选择了基于Transformer解码器结构的语言模型。在评估模型性能时,选择了常识推理、数学、上下文学习和长文本处理等多个领域,以全面评估模型的性能。在基准测试中,测量了模型的推理延迟和内存占用,以评估模型的效率。
🖼️ 关键图片
📊 实验亮点
论文对70个开源小型语言模型进行了基准测试,并提供了详细的性能数据,包括推理延迟和内存占用。通过对比不同模型的性能,揭示了不同架构、训练数据和训练算法对模型性能的影响。例如,某些模型在常识推理任务上表现出色,而另一些模型在数学任务上表现更好。这些数据为研究人员选择合适的模型和优化模型性能提供了有价值的参考。
🎯 应用场景
该研究成果可应用于智能手机、智能家居设备、可穿戴设备等资源受限的设备上,使这些设备能够运行更强大的AI模型,从而提供更智能、更个性化的服务。例如,可以用于设备端的自然语言处理、语音识别、图像识别等任务,提高设备的智能化水平和用户体验。未来的研究可以进一步优化小型语言模型的性能和效率,使其能够在更多设备上部署。
📄 摘要(原文)
Small language models (SLMs), despite their widespread adoption in modern smart devices, have received significantly less academic attention compared to their large language model (LLM) counterparts, which are predominantly deployed in data centers and cloud environments. While researchers continue to improve the capabilities of LLMs in the pursuit of artificial general intelligence, SLM research aims to make machine intelligence more accessible, affordable, and efficient for everyday tasks. Focusing on transformer-based, decoder-only language models with 100M-5B parameters, we survey 70 state-of-the-art open-source SLMs, analyzing their technical innovations across three axes: architectures, training datasets, and training algorithms. In addition, we evaluate their capabilities in various domains, including commonsense reasoning, mathematics, in-context learning, and long context. To gain further insight into their on-device runtime costs, we benchmark their inference latency and memory footprints. Through in-depth analysis of our benchmarking data, we offer valuable insights to advance research in this field.