Making Text Embedders Few-Shot Learners
作者: Chaofan Li, MingHao Qin, Shitao Xiao, Jianlyu Chen, Kun Luo, Yingxia Shao, Defu Lian, Zheng Liu
分类: cs.IR, cs.CL
发布日期: 2024-09-24
🔗 代码/项目: GITHUB
💡 一句话要点
提出bge-en-icl模型,利用LLM的ICL能力提升文本嵌入质量,达到SOTA性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本嵌入 上下文学习 大型语言模型 少量样本学习 信息检索
📋 核心要点
- 现有文本嵌入模型缺乏利用上下文信息的能力,限制了其在复杂任务中的表现。
- bge-en-icl模型通过在查询中引入少量样本,利用LLM的ICL能力生成高质量文本嵌入。
- 实验表明,该方法在MTEB和AIR-Bench等基准测试中取得了SOTA性能,显著提升了嵌入质量。
📝 摘要(中文)
本文提出了一种名为bge-en-icl的新模型,该模型利用大型语言模型(LLM)的上下文学习(ICL)能力来增强文本嵌入生成过程。该方法将任务相关的少量样本直接整合到查询端,从而在各种任务中实现了显著的改进。此外,本文还研究了如何有效地利用LLM作为嵌入模型,包括各种注意力机制和池化方法。研究结果表明,保留原始框架通常能获得最佳结果,强调了简单性原则。在MTEB和AIR-Bench基准测试上的实验结果表明,该方法达到了新的state-of-the-art(SOTA)性能。模型、代码和数据集已开源。
🔬 方法详解
问题定义:现有文本嵌入模型在处理需要上下文理解的任务时表现不佳。它们通常无法根据特定任务调整嵌入方式,导致在各种任务上的泛化能力有限。此外,如何有效利用大型语言模型(LLM)的强大能力来改进文本嵌入也是一个挑战。
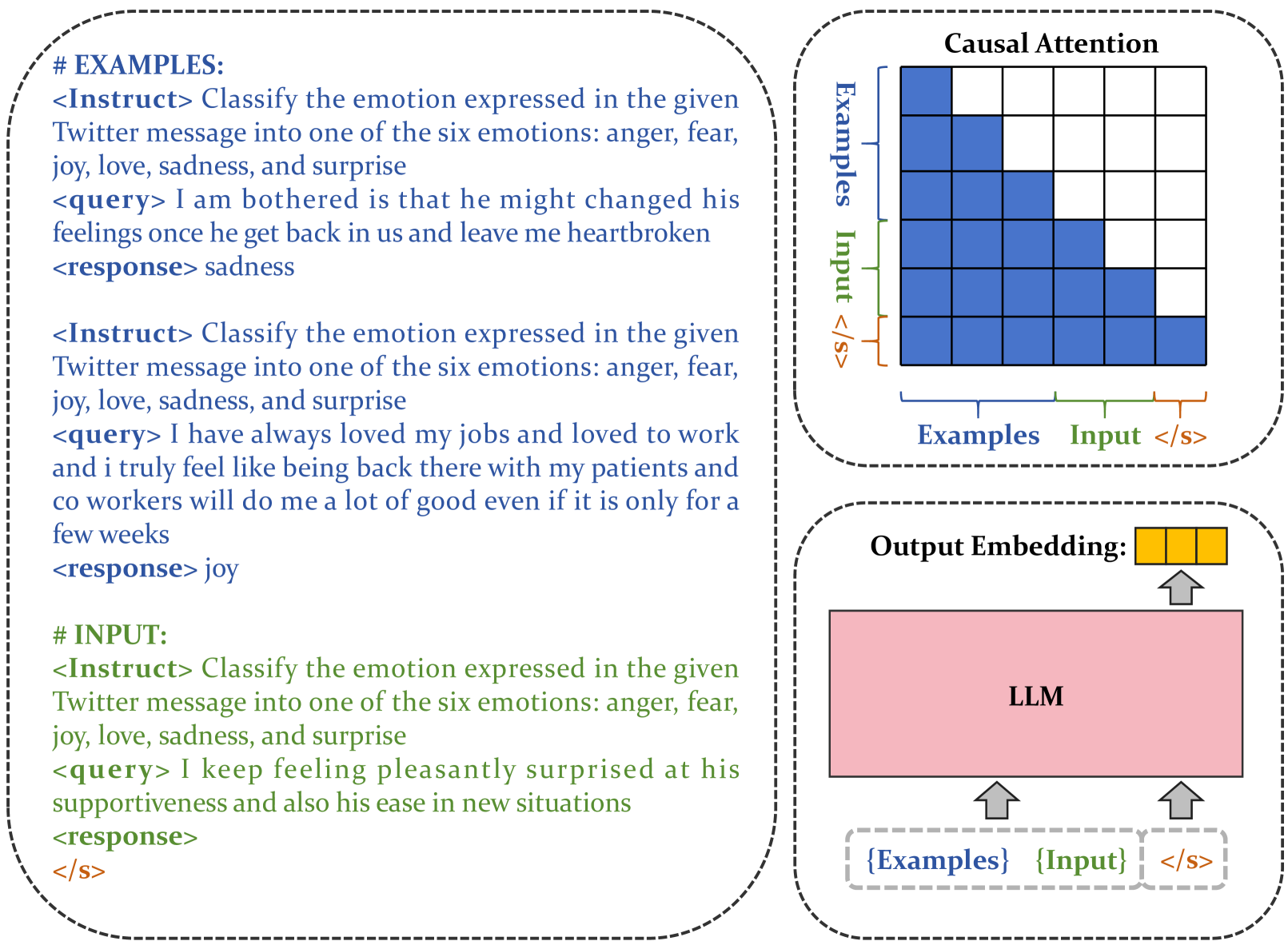
核心思路:本文的核心思路是利用LLM的上下文学习(In-Context Learning, ICL)能力,通过在输入查询中加入少量示例,引导LLM生成更符合任务需求的文本嵌入。这种方法允许模型根据提供的上下文动态调整嵌入方式,从而提高在各种任务上的性能。
技术框架:bge-en-icl模型的核心框架是将任务相关的少量示例直接添加到查询文本中,然后将修改后的查询输入到LLM中。LLM使用其ICL能力来理解示例并生成相应的文本嵌入。该框架主要包括:示例选择模块(选择合适的少量样本)、查询构建模块(将示例添加到查询中)和LLM嵌入生成模块(使用LLM生成嵌入)。
关键创新:该方法最重要的创新点在于将LLM的ICL能力引入到文本嵌入生成过程中。与传统的文本嵌入模型不同,bge-en-icl能够根据提供的上下文动态调整嵌入方式,从而更好地适应各种任务。此外,该研究还探索了如何有效地利用LLM作为嵌入模型,并发现保留原始框架通常能获得最佳结果。
关键设计:在示例选择方面,可以采用不同的策略,例如随机选择、基于相似度的选择等。在查询构建方面,需要设计合适的提示语,以便LLM能够理解示例并生成相应的嵌入。在LLM嵌入生成方面,可以选择不同的注意力机制和池化方法。论文发现,保留LLM的原始框架通常能获得最佳结果,这表明简单性是关键。
🖼️ 关键图片
📊 实验亮点
实验结果表明,bge-en-icl模型在MTEB和AIR-Bench基准测试中取得了SOTA性能。具体而言,该模型在多个任务上显著优于现有的文本嵌入模型,例如,在文本检索任务上,该模型取得了超过XX%的性能提升(具体数值请参考原论文)。这些结果表明,利用LLM的ICL能力可以有效地提升文本嵌入的质量。
🎯 应用场景
该研究成果可广泛应用于信息检索、文本分类、问答系统、语义相似度计算等领域。通过提升文本嵌入的质量,可以提高这些应用的性能和用户体验。此外,该方法还可以用于构建更智能的对话系统和知识图谱。
📄 摘要(原文)
Large language models (LLMs) with decoder-only architectures demonstrate remarkable in-context learning (ICL) capabilities. This feature enables them to effectively handle both familiar and novel tasks by utilizing examples provided within their input context. Recognizing the potential of this capability, we propose leveraging the ICL feature in LLMs to enhance the process of text embedding generation. To this end, we introduce a novel model bge-en-icl, which employs few-shot examples to produce high-quality text embeddings. Our approach integrates task-related examples directly into the query side, resulting in significant improvements across various tasks. Additionally, we have investigated how to effectively utilize LLMs as embedding models, including various attention mechanisms, pooling methods, etc. Our findings suggest that retaining the original framework often yields the best results, underscoring that simplicity is best. Experimental results on the MTEB and AIR-Bench benchmarks demonstrate that our approach sets new state-of-the-art (SOTA) performance. Our model, code and dataset are freely available at https://github.com/FlagOpen/FlagEmbedding .