In-Context Learning May Not Elicit Trustworthy Reasoning: A-Not-B Errors in Pretrained Language Models
作者: Pengrui Han, Peiyang Song, Haofei Yu, Jiaxuan You
分类: cs.CL, cs.AI
发布日期: 2024-09-23
备注: Accepted at EMNLP 2024 Findings
💡 一句话要点
揭示大语言模型在情境学习中存在类似婴儿的A-Not-B错误
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 情境学习 A-Not-B错误 抑制控制 推理能力
📋 核心要点
- 现有大语言模型在特定认知任务中表现出与婴儿相似的认知局限性,例如A-Not-B错误。
- 论文设计文本问答场景模拟A-Not-B实验,评估大语言模型在情境学习中的抑制控制能力。
- 实验表明,即使是最先进的LLM,在情境微变时也会出现显著的推理性能下降。
📝 摘要(中文)
近年来,人工智能取得了显著进展,涌现出能够以类人方式执行任务的大型语言模型(LLMs)。然而,在某些领域,LLMs仅表现出婴儿水平的认知能力。A-Not-B错误就是其中之一,这种现象在婴儿中表现为,尽管观察到条件发生变化,他们仍会重复先前获得奖励的行为。这突显了他们缺乏抑制控制——即停止习惯性或冲动反应的能力。在这项工作中,我们设计了一个基于文本的多项选择问答场景,类似于A-Not-B实验设置,以系统地测试LLMs的抑制控制能力。我们发现,最先进的LLMs(如Llama3-8b)在使用情境学习(ICL)时表现始终良好,但当上下文发生细微变化时,会犯错误,并在推理任务中出现高达83.3%的显著下降。这表明,LLMs在这方面的抑制控制能力仅与人类婴儿相当,在ICL期间经常无法抑制先前建立的响应模式。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)是否表现出类似人类婴儿的A-Not-B错误。现有方法在评估LLMs的推理能力时,通常忽略了其抑制控制能力,即抑制先前学习到的模式并适应新环境的能力。这种忽略可能导致对LLMs真实推理能力的过高估计。
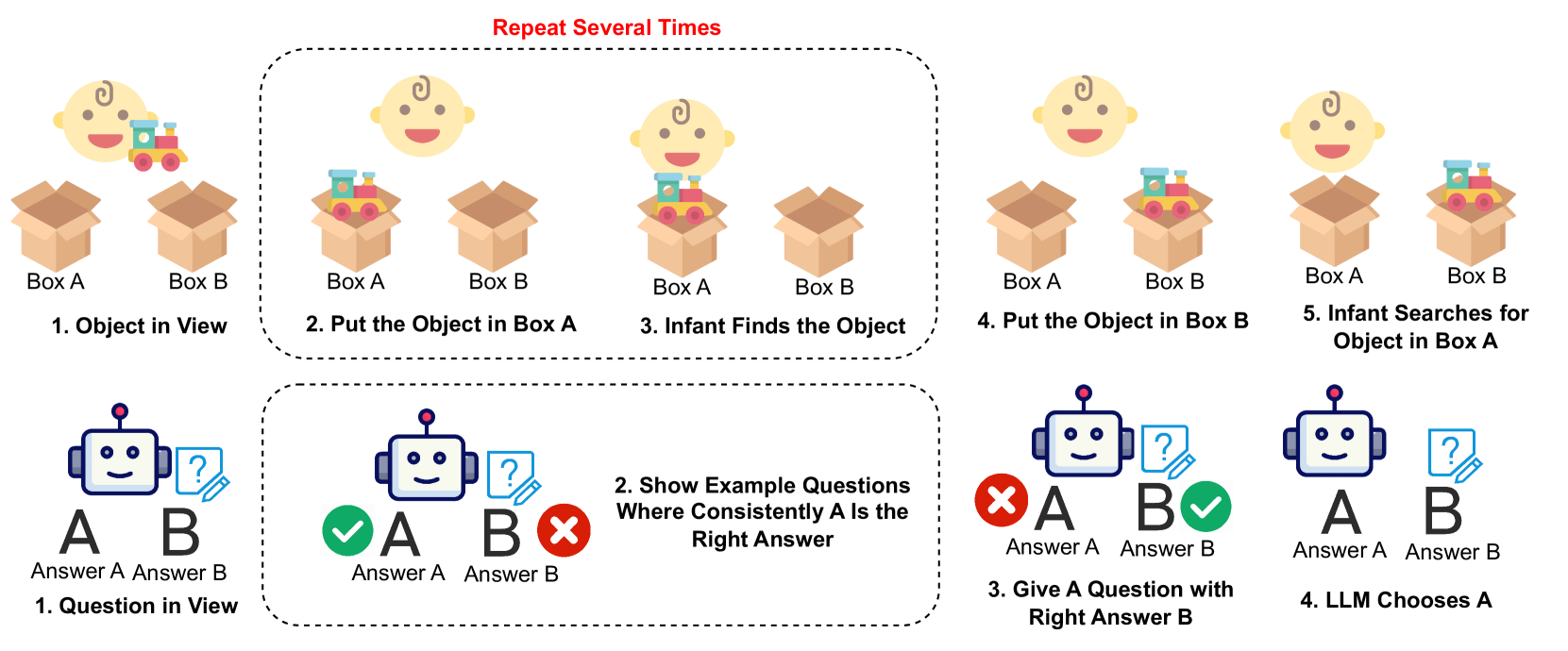
核心思路:论文的核心思路是设计一个基于文本的A-Not-B实验,通过改变上下文的细微信息,观察LLMs是否能够抑制先前建立的响应模式,从而评估其抑制控制能力。这种设计模仿了人类婴儿的A-Not-B实验,能够更真实地反映LLMs的认知局限性。
技术框架:论文构建了一个多项选择问答场景,其中包含多个示例,这些示例引导LLM学习一种特定的推理模式。然后,在测试阶段,通过引入细微的上下文变化(例如,改变问题的措辞或选项的顺序),观察LLM是否能够抑制先前学习到的模式并做出正确的选择。整个流程类似于人类婴儿的A-Not-B实验,通过观察LLM在上下文变化时的行为来评估其抑制控制能力。
关键创新:论文的关键创新在于将经典的A-Not-B实验范式应用于评估大型语言模型的推理能力。这种方法能够更直接地评估LLMs的抑制控制能力,并揭示其在情境学习中存在的认知局限性。与传统的评估方法相比,该方法能够更真实地反映LLMs的推理能力。
关键设计:论文的关键设计包括:1) 精心设计的文本问答场景,能够模拟A-Not-B实验的条件;2) 细微的上下文变化,能够有效地诱导LLMs产生A-Not-B错误;3) 多种评估指标,能够全面地评估LLMs的抑制控制能力。具体参数设置和网络结构取决于所使用的LLM(例如,Llama3-8b),论文主要关注的是实验设计和结果分析,而非特定的模型架构。
🖼️ 关键图片

📊 实验亮点
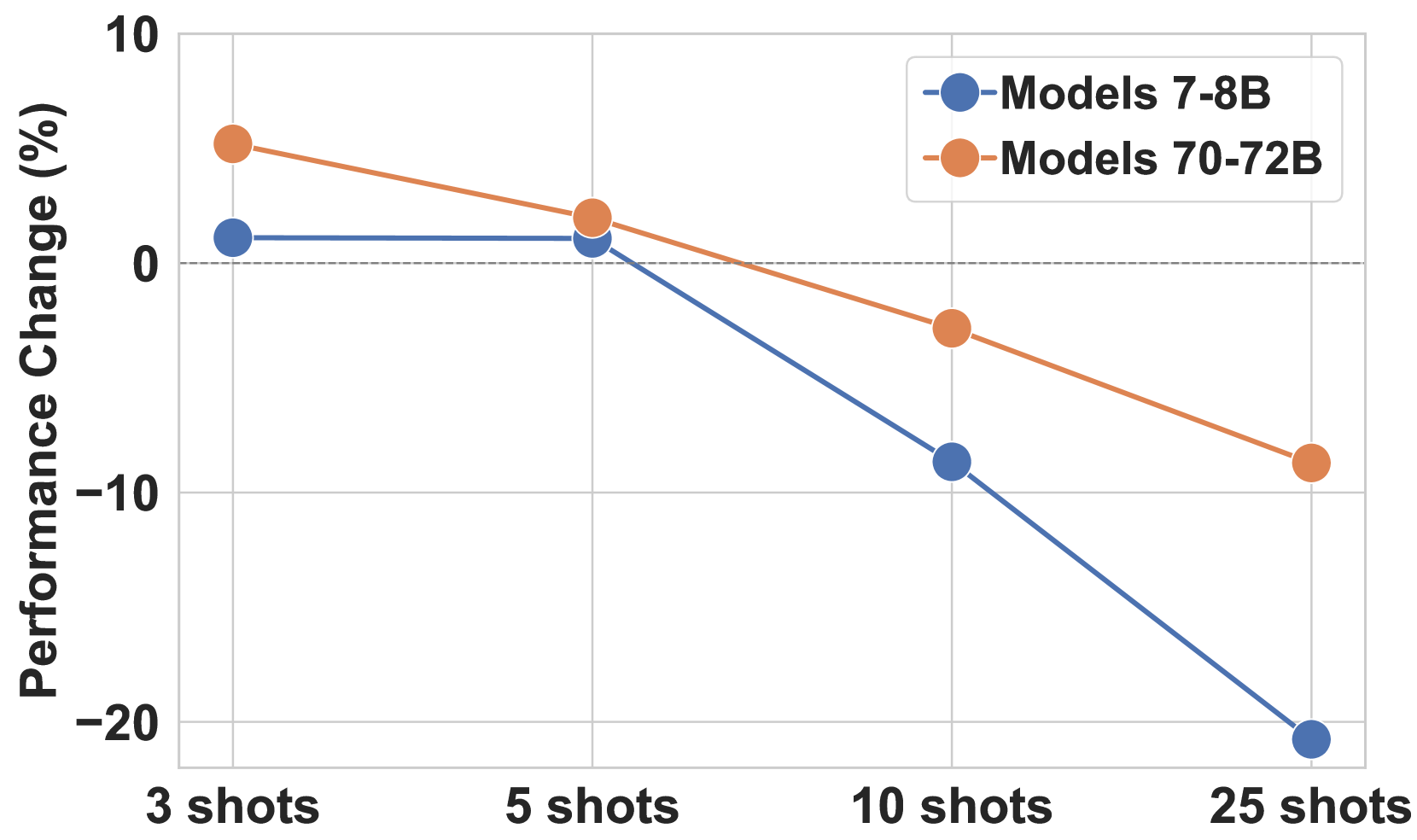
实验结果表明,即使是最先进的LLMs(如Llama3-8b),在面对细微的上下文变化时,也会出现显著的推理性能下降,最高可达83.3%。这表明LLMs在抑制控制方面存在明显的局限性,与人类婴儿的认知水平相当。该研究揭示了LLMs在情境学习中存在的潜在风险,并为改进LLMs的推理能力提供了新的视角。
🎯 应用场景
该研究有助于更深入地理解大型语言模型的认知局限性,并为改进LLMs的推理能力提供指导。潜在应用包括:开发更鲁棒、更可靠的AI系统,避免AI系统在实际应用中出现类似A-Not-B错误的非理性行为,以及设计更有效的AI训练方法,提高LLMs的抑制控制能力和适应性。
📄 摘要(原文)
Recent advancements in artificial intelligence have led to the creation of highly capable large language models (LLMs) that can perform tasks in a human-like manner. However, LLMs exhibit only infant-level cognitive abilities in certain areas. One such area is the A-Not-B error, a phenomenon seen in infants where they repeat a previously rewarded behavior despite well-observed changed conditions. This highlights their lack of inhibitory control -- the ability to stop a habitual or impulsive response. In our work, we design a text-based multi-choice QA scenario similar to the A-Not-B experimental settings to systematically test the inhibitory control abilities of LLMs. We found that state-of-the-art LLMs (like Llama3-8b) perform consistently well with in-context learning (ICL) but make errors and show a significant drop of as many as 83.3% in reasoning tasks when the context changes trivially. This suggests that LLMs only have inhibitory control abilities on par with human infants in this regard, often failing to suppress the previously established response pattern during ICL.