Parse Trees Guided LLM Prompt Compression
作者: Wenhao Mao, Chengbin Hou, Tianyu Zhang, Xinyu Lin, Ke Tang, Hairong Lv
分类: cs.CL, cs.AI
发布日期: 2024-09-23 (更新: 2025-09-28)
备注: Accepted by IEEE TPAMI
💡 一句话要点
提出PartPrompt,一种基于句法树引导的大语言模型提示压缩方法,提升效率并保持性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 提示压缩 大语言模型 句法分析 信息熵 树剪枝
📋 核心要点
- 现有提示压缩方法,如生成式方法易产生幻觉,选择性方法忽略了语言结构,限制了压缩性能。
- PartPrompt利用句法树分析提示的结构,通过信息熵和传播算法,选择性地保留重要信息,实现有效压缩。
- 实验表明,PartPrompt在多种数据集和模型上取得了领先的压缩性能,并保持了压缩后提示的连贯性。
📝 摘要(中文)
为了提升大语言模型在各种任务中的性能,通常需要提供丰富的上下文信息,但这会导致更长的提示,增加计算成本,并可能超出大语言模型的输入限制。现有的提示压缩方法,如生成式压缩,存在幻觉问题;选择性压缩则忽略了语言规则和提示的全局结构。为此,本文提出了一种新的选择性压缩方法PartPrompt。该方法首先基于语言规则获得每个句子的句法树,并计算每个节点的局部信息熵。然后,根据句子、段落和章节的层次结构,将这些局部句法树组织成全局树。之后,提出自底向上和自顶向下的传播方法来调整全局树上的节点值。最后,开发了一种递归算法,根据调整后的节点值修剪全局树。实验表明,PartPrompt在各种数据集、指标、压缩率和目标大语言模型上都取得了最先进的性能。深入的消融研究证实了PartPrompt设计的有效性,其他额外的实验也证明了其在压缩提示的一致性和极端长提示场景中的优越性。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)应用中,长提示(long prompt)带来的计算成本高、超出输入限制等问题。现有提示压缩方法存在不足:生成式压缩易产生幻觉,内容失真;选择性压缩忽略了语言学规则和全局结构,压缩效果有限。
核心思路:论文的核心思路是利用句法分析(parse tree)来理解提示的结构,并基于此进行选择性的信息保留。通过分析句子的句法结构,识别关键成分,并在压缩过程中优先保留这些成分,从而在减少提示长度的同时,尽可能地保持其语义完整性。
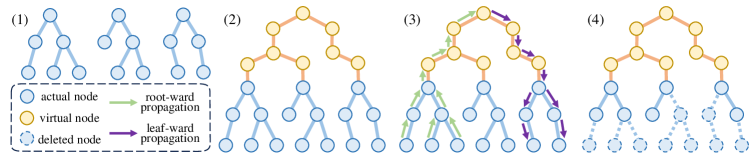
技术框架:PartPrompt的技术框架主要包含以下几个阶段: 1. 句法树构建:对提示中的每个句子构建句法树。 2. 局部信息熵计算:计算每个句法树节点的局部信息熵,衡量其重要性。 3. 全局树构建:根据句子、段落、章节等层次结构,将局部句法树组织成全局树。 4. 节点值传播:进行自底向上(root-ward)和自顶向下(leaf-ward)的节点值传播,调整节点的重要性评估。 5. 树剪枝:基于调整后的节点值,使用递归算法对全局树进行剪枝,得到压缩后的提示。
关键创新:PartPrompt的关键创新在于: 1. 句法树引导的压缩:将句法分析引入提示压缩,充分利用了语言学知识。 2. 全局树结构:构建全局树,考虑了句子、段落、章节之间的层次关系,避免了局部最优。 3. 节点值传播机制:通过自底向上和自顶向下的传播,更准确地评估节点的重要性。
关键设计: 1. 局部信息熵:使用局部信息熵来衡量每个节点的重要性,熵越高表示节点包含的信息越多,越重要。 2. 传播算法:自底向上传播将叶子节点的重要性传递到根节点,自顶向下传播则将根节点的重要性传递到叶子节点,从而实现全局信息的整合。 3. 递归剪枝算法:基于调整后的节点值,递归地剪掉不重要的节点,直到满足目标压缩率。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PartPrompt在各种数据集、指标和压缩率下均取得了最先进的性能。消融实验验证了各个模块设计的有效性。此外,PartPrompt在保持压缩提示的连贯性以及处理极端长提示方面也表现出优越性。具体性能数据未知。
🎯 应用场景
PartPrompt可应用于各种需要处理长文本提示的大语言模型应用场景,例如:问答系统、文本摘要、代码生成等。通过降低计算成本和减少输入长度限制,PartPrompt能够提升LLM在资源受限环境下的应用能力,并加速LLM的推理速度。
📄 摘要(原文)
Offering rich contexts to Large Language Models (LLMs) has shown to boost the performance in various tasks, but the resulting longer prompt would increase the computational cost and might exceed the input limit of LLMs. Recently, some prompt compression methods have been suggested to shorten the length of prompts by using language models to generate shorter prompts or by developing computational models to select important parts of original prompt. The generative compression methods would suffer from issues like hallucination, while the selective compression methods have not involved linguistic rules and overlook the global structure of prompt. To this end, we propose a novel selective compression method called PartPrompt. It first obtains a parse tree for each sentence based on linguistic rules, and calculates local information entropy for each node in a parse tree. These local parse trees are then organized into a global tree according to the hierarchical structure such as the dependency of sentences, paragraphs, and sections. After that, the root-ward propagation and leaf-ward propagation are proposed to adjust node values over the global tree. Finally, a recursive algorithm is developed to prune the global tree based on the adjusted node values. The experiments show that PartPrompt receives the state-of-the-art performance across various datasets, metrics, compression ratios, and target LLMs for inference. The in-depth ablation studies confirm the effectiveness of designs in PartPrompt, and other additional experiments also demonstrate its superiority in terms of the coherence of compressed prompts and in the extreme long prompt scenario.