A Preliminary Study of o1 in Medicine: Are We Closer to an AI Doctor?
作者: Yunfei Xie, Juncheng Wu, Haoqin Tu, Siwei Yang, Bingchen Zhao, Yongshuo Zong, Qiao Jin, Cihang Xie, Yuyin Zhou
分类: cs.CL, cs.AI
发布日期: 2024-09-23
备注: The first four authors contributed equally, project page available at https://ucsc-vlaa.github.io/o1_medicine/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
初步研究o1在医学领域的应用,探索AI医生可能性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 医学问答 临床应用 AI医生 自然语言处理
📋 核心要点
- 现有医学问答数据集临床相关性不足,难以有效评估LLM在真实临床场景中的应用潜力。
- 通过构建基于NEJM和The Lancet专业医学测验的更具挑战性的问答任务,评估o1在医学领域的理解和推理能力。
- 实验结果表明,o1在医学问答任务中超越GPT-4,但仍存在幻觉和多语言能力不一致等问题。
📝 摘要(中文)
大型语言模型(LLMs)在各个领域和任务中展现出卓越的能力,不断拓展我们在学习和认知方面的知识边界。OpenAI最新的模型o1是首个采用强化学习策略,具有内在思维链技术的LLM。尽管它在各种通用语言任务上表现出惊人的强大能力,但其在医学等专业领域的表现仍然未知。为此,本报告全面探索了o1在不同医学场景中的应用,考察了理解、推理和多语言能力这三个关键方面。具体而言,我们的评估涵盖了使用来自37个医学数据集的6项任务,包括两个基于《新英格兰医学杂志》(NEJM)和《柳叶刀》的专业医学测验而新建的更具挑战性的问答(QA)任务。与MedQA等标准医学QA基准相比,这些数据集提供了更大的临床相关性,能更有效地转化为实际的临床应用。我们对o1的分析表明,LLM增强的推理能力可能(显著)有利于其理解各种医学指令和推理复杂临床场景的能力。值得注意的是,在19个数据集和两个新创建的复杂QA场景中,o1的准确率平均超过之前的GPT-4 6.2%和6.6%。但与此同时,我们发现模型能力和现有评估协议中的一些弱点,包括幻觉、不一致的多语言能力以及评估指标的差异。我们将原始数据和模型输出发布在https://ucsc-vlaa.github.io/o1_medicine/,供未来研究使用。
🔬 方法详解
问题定义:现有医学问答数据集(如MedQA)与实际临床应用存在差距,难以准确评估大型语言模型(LLMs)在真实医疗场景中的能力。现有方法缺乏对LLM在复杂临床推理和多语言医学信息处理方面的深入评估。
核心思路:通过构建更具临床相关性的医学问答数据集,并设计多方面的评估指标,全面考察LLM在医学领域的理解、推理和多语言能力。重点关注模型在复杂临床场景下的表现,以及潜在的弱点,如幻觉和多语言能力不一致。
技术框架:该研究主要采用实证评估的方法,没有提出新的模型架构。研究者收集并整理了37个医学数据集,并在此基础上构建了两个新的、更具挑战性的问答数据集,这些数据集来源于《新英格兰医学杂志》(NEJM)和《柳叶刀》的专业医学测验。然后,使用这些数据集对OpenAI的o1模型进行评估,并与GPT-4进行比较。评估指标包括准确率等。
关键创新:该研究的关键创新在于构建了更具临床相关性的医学问答数据集,这些数据集能够更有效地反映LLM在真实临床场景中的应用潜力。此外,该研究还对LLM在医学领域的弱点进行了深入分析,例如幻觉和多语言能力不一致。
关键设计:研究中关键的设计包括:1) 新数据集的构建,确保其来源于权威医学资源,并具有较高的临床难度;2) 评估指标的选择,除了准确率之外,还关注了模型的幻觉和多语言能力;3) 对比实验的设计,将o1与GPT-4进行比较,以评估其性能提升。
🖼️ 关键图片
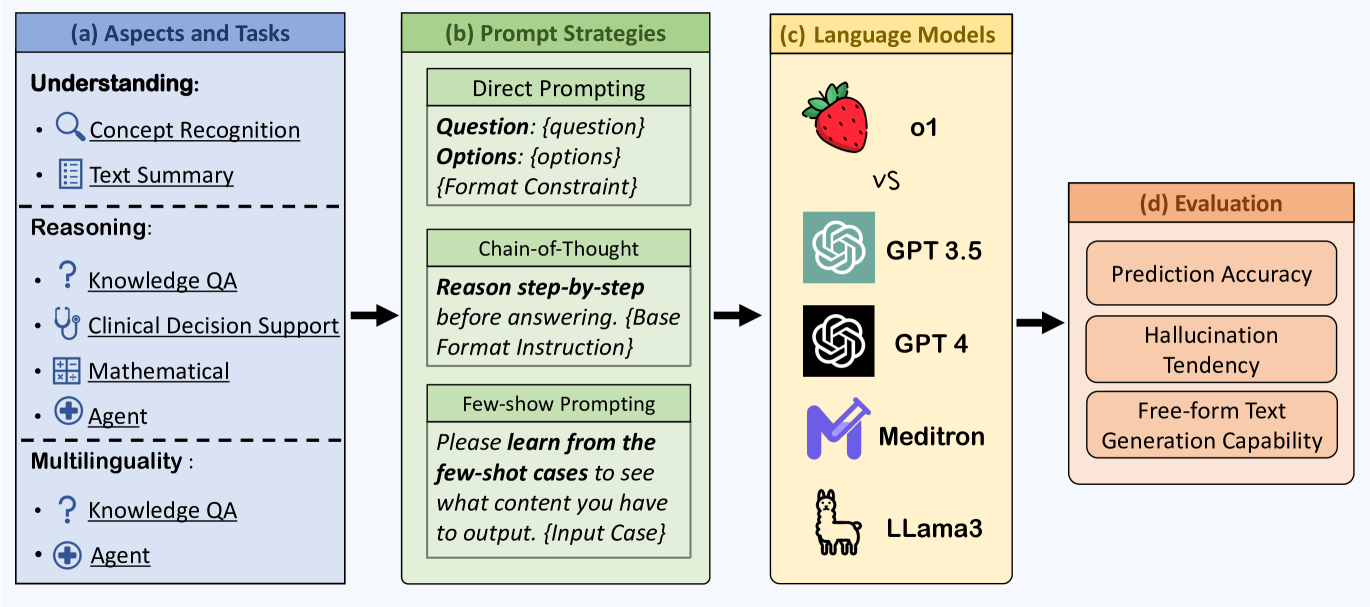


📊 实验亮点
实验结果表明,o1在19个医学数据集和两个新建的复杂QA场景中,准确率平均超过GPT-4 6.2%和6.6%。这表明o1在医学领域的理解和推理能力方面有所提升。然而,研究也发现o1存在幻觉和多语言能力不一致等问题,需要在未来的研究中加以解决。
🎯 应用场景
该研究为AI在医疗领域的应用提供了有价值的参考。通过评估LLM在医学问答任务中的表现,可以推动AI辅助诊断、医学知识检索、个性化医疗等领域的发展。未来的研究可以进一步探索如何克服LLM的弱点,提高其在医疗领域的可靠性和实用性。
📄 摘要(原文)
Large language models (LLMs) have exhibited remarkable capabilities across various domains and tasks, pushing the boundaries of our knowledge in learning and cognition. The latest model, OpenAI's o1, stands out as the first LLM with an internalized chain-of-thought technique using reinforcement learning strategies. While it has demonstrated surprisingly strong capabilities on various general language tasks, its performance in specialized fields such as medicine remains unknown. To this end, this report provides a comprehensive exploration of o1 on different medical scenarios, examining 3 key aspects: understanding, reasoning, and multilinguality. Specifically, our evaluation encompasses 6 tasks using data from 37 medical datasets, including two newly constructed and more challenging question-answering (QA) tasks based on professional medical quizzes from the New England Journal of Medicine (NEJM) and The Lancet. These datasets offer greater clinical relevance compared to standard medical QA benchmarks such as MedQA, translating more effectively into real-world clinical utility. Our analysis of o1 suggests that the enhanced reasoning ability of LLMs may (significantly) benefit their capability to understand various medical instructions and reason through complex clinical scenarios. Notably, o1 surpasses the previous GPT-4 in accuracy by an average of 6.2% and 6.6% across 19 datasets and two newly created complex QA scenarios. But meanwhile, we identify several weaknesses in both the model capability and the existing evaluation protocols, including hallucination, inconsistent multilingual ability, and discrepant metrics for evaluation. We release our raw data and model outputs at https://ucsc-vlaa.github.io/o1_medicine/ for future research.