OmniBench: Towards The Future of Universal Omni-Language Models
作者: Yizhi Li, Yinghao Ma, Ge Zhang, Ruibin Yuan, Kang Zhu, Hangyu Guo, Yiming Liang, Jiaheng Liu, Zekun Wang, Jian Yang, Siwei Wu, Xingwei Qu, Jinjie Shi, Xinyue Zhang, Zhenzhu Yang, Yidan Wen, Yanghai Wang, Shihao Li, Zhaoxiang Zhang, Zachary Liu, Emmanouil Benetos, Wenhao Huang, Chenghua Lin
分类: cs.CL, cs.AI, cs.CV
发布日期: 2024-09-23 (更新: 2025-12-29)
备注: Accepted by The Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS2025)
💡 一句话要点
OmniBench:面向通用全语言模型的综合性多模态评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 全语言模型 评测基准 三模态融合 指令调优
📋 核心要点
- 现有MLLM缺乏对多种模态信息同时处理和推理能力的全面评估,阻碍了全语言模型的发展。
- OmniBench基准通过高质量人工标注,评估模型在视觉、听觉和文本三种模态下的理解和推理能力。
- 实验表明现有开源OLM在三模态推理上存在不足,为此作者构建了OmniInstruct数据集进行指令调优。
📝 摘要(中文)
多模态大型语言模型(MLLMs)的最新进展旨在整合和解释跨多种模态的数据。然而,由于缺乏全面的模态基准,这些模型同时处理和推理多种模态的能力仍未得到充分探索。我们推出了OmniBench,这是一个新颖的基准,旨在严格评估模型同时识别、解释和推理视觉、听觉和文本输入的能力。我们将能够进行这种三模态处理的语言模型定义为全语言模型(OLMs)。OmniBench的特点是高质量的人工标注,确保准确的响应需要跨所有三种模态的综合理解和推理。我们的主要发现表明:i) 开源OLMs在三模态环境中的指令遵循和推理能力方面存在严重局限性;ii) 即使提供了图像或/和音频的替代文本表示,大多数基线模型的性能也很差(低于50%的准确率)。这些结果表明,在现有的MLLM训练范式中,从文本、图像和音频构建一致上下文的能力常常被忽视。为了解决这一差距,我们整理了一个包含84.5K训练样本的指令调优数据集OmniInstruct,用于训练OLMs以适应三模态环境。我们提倡未来的研究应侧重于开发更强大的三模态集成技术和训练策略,以增强OLMs。代码、数据和实时排行榜可在https://m-a-p.ai/OmniBench找到。
🔬 方法详解
问题定义:现有的大型多模态语言模型(MLLMs)在处理单一模态数据上取得了显著进展,但缺乏在多种模态(如视觉、听觉和文本)同时存在的情况下进行理解和推理的能力。现有的评测基准通常侧重于单一或少数模态,无法全面评估模型在复杂多模态场景下的表现。因此,如何构建一个能够有效评估模型在多模态融合理解和推理能力的基准是一个关键问题。
核心思路:OmniBench的核心思路是构建一个包含视觉、听觉和文本三种模态信息的综合性评测基准,通过高质量的人工标注,确保模型需要整合多种模态的信息才能给出正确的答案。通过设计复杂的推理任务,考察模型在多模态场景下的理解和推理能力,从而推动全语言模型(OLMs)的发展。
技术框架:OmniBench基准包含多个任务,每个任务都包含视觉、听觉和文本三种模态的输入。模型需要同时处理这三种模态的信息,并根据指令进行推理和回答。为了训练模型适应这种三模态环境,作者还构建了一个名为OmniInstruct的指令调优数据集,包含84.5K个训练样本。该数据集用于对模型进行微调,使其能够更好地理解和处理三模态信息。
关键创新:OmniBench的关键创新在于其对三模态信息的综合评估能力。与以往的基准相比,OmniBench更加注重考察模型在多种模态信息融合下的理解和推理能力。此外,OmniInstruct数据集的构建也为训练全语言模型提供了有价值的资源。
关键设计:OmniBench的数据标注采用了高质量的人工标注,确保标注的准确性和一致性。任务设计涵盖了多种推理类型,包括常识推理、因果推理等,以全面评估模型的推理能力。OmniInstruct数据集的构建采用了指令调优的方法,通过提供明确的指令,引导模型学习如何处理三模态信息。
🖼️ 关键图片

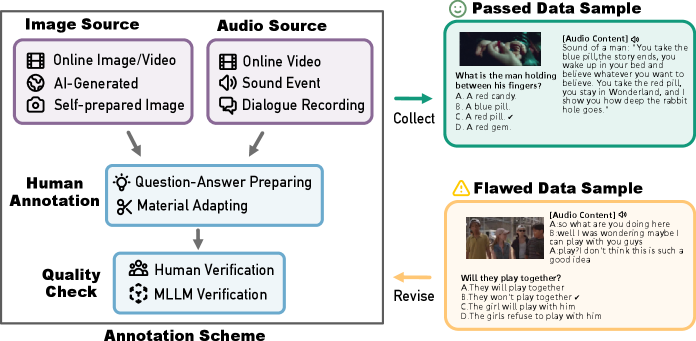
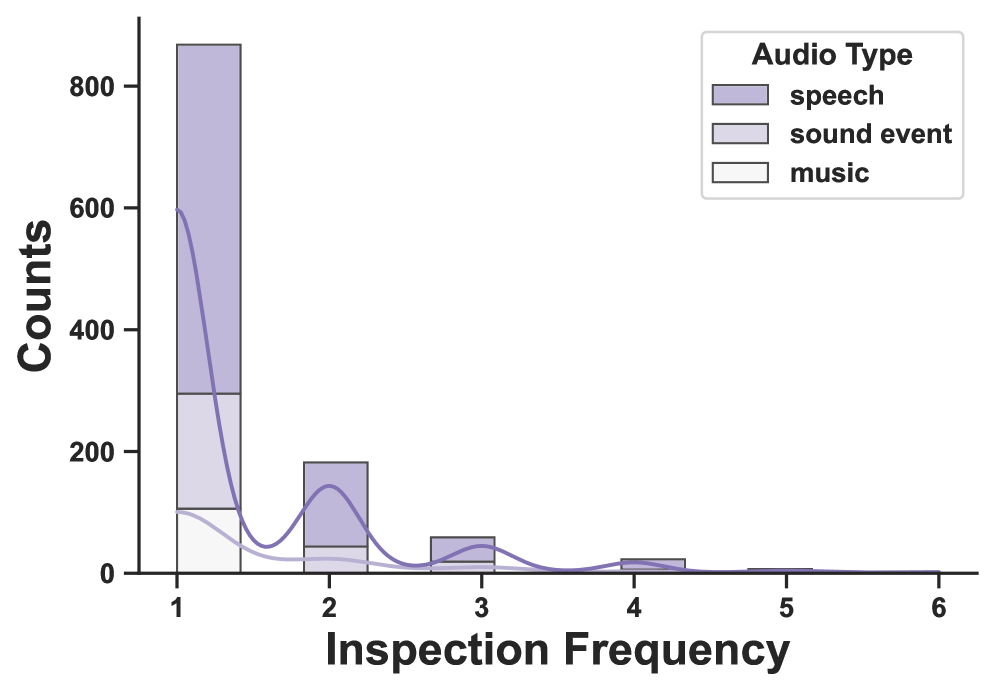
📊 实验亮点
实验结果表明,现有的开源全语言模型(OLMs)在OmniBench基准上的表现不佳,即使提供了图像或音频的替代文本表示,准确率也低于50%。这表明现有模型在三模态信息融合和推理方面存在显著不足。通过使用OmniInstruct数据集进行指令调优,可以显著提升模型在OmniBench上的性能,但仍有很大的提升空间。
🎯 应用场景
OmniBench的潜在应用领域包括智能助手、多媒体内容理解、跨模态信息检索等。通过提升模型在多模态场景下的理解和推理能力,可以实现更智能、更自然的人机交互。例如,智能助手可以根据用户的语音指令、视觉输入和文本描述,更好地理解用户的意图并提供相应的服务。未来,OmniBench的研究成果有望推动多模态人工智能技术的进一步发展。
📄 摘要(原文)
Recent advancements in multimodal large language models (MLLMs) have aimed to integrate and interpret data across diverse modalities. However, the capacity of these models to concurrently process and reason about multiple modalities remains underexplored, partly due to the lack of comprehensive modality-wise benchmarks. We introduce OmniBench, a novel benchmark designed to rigorously evaluate models' ability to recognize, interpret, and reason across visual, acoustic, and textual inputs simultaneously. We define language models capable of such tri-modal processing as the omni-language models (OLMs). OmniBench is distinguished by high-quality human annotations, ensuring that accurate responses require integrated understanding and reasoning across all three modalities. Our main findings reveal that: i) open-source OLMs exhibit critical limitations in instruction-following and reasoning capabilities within tri-modal contexts; and ii) most baselines models perform poorly (below 50% accuracy) even when provided with alternative textual representations of images or/and audio. These results suggest that the ability to construct a consistent context from text, image, and audio is often overlooked in existing MLLM training paradigms. To address this gap, we curate an instruction tuning dataset of 84.5K training samples, OmniInstruct, for training OLMs to adapt to tri-modal contexts. We advocate for future research to focus on developing more robust tri-modal integration techniques and training strategies to enhance OLMs. Codes, data and live leaderboard could be found at https://m-a-p.ai/OmniBench.