Generative LLM Powered Conversational AI Application for Personalized Risk Assessment: A Case Study in COVID-19
作者: Mohammad Amin Roshani, Xiangyu Zhou, Yao Qiang, Srinivasan Suresh, Steve Hicks, Usha Sethuraman, Dongxiao Zhu
分类: cs.CL, cs.AI
发布日期: 2024-09-23
💡 一句话要点
提出基于生成式LLM的会话式AI应用,用于COVID-19个性化风险评估,无需编程。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成式LLM 会话式AI 风险评估 COVID-19 个性化医疗 无代码 注意力机制
📋 核心要点
- 传统机器学习方法在疾病风险评估中需要大量编程,限制了其易用性和可扩展性。
- 利用生成式LLM的强大能力,通过人机对话进行实时风险评估,无需编写代码,提升交互性和个性化。
- 实验表明,微调后的LLM在少量数据下,AUC指标优于传统分类器,展现了其在实际应用中的潜力。
📝 摘要(中文)
本文提出了一种基于LLM的新型疾病风险评估方法,通过流式人机对话实现,无需传统机器学习方法所需的编程。以COVID-19严重程度风险评估为例,我们使用少量自然语言示例对预训练的生成式LLM(如Llama2-7b和Flan-t5-xl)进行微调,并将其性能与使用表格数据从头训练的传统分类器(即Logistic Regression、XGBoost、Random Forest)在各种实验设置下进行比较。我们开发了一个移动应用程序,该程序使用这些微调的LLM作为其生成式AI核心,以促进临床医生和患者之间的实时交互,通过会话界面提供无代码风险评估。这种集成不仅允许使用流式问答作为输入,还提供从LLM的注意力层导出的个性化特征重要性分析,从而增强了风险评估的可解释性。通过使用有限数量的微调样本实现高AUC分数,我们的结果证明了生成式LLM在低数据情况下优于判别式分类方法的潜力,突出了它们的实际适应性和有效性。这项工作旨在填补利用生成式LLM进行交互式无代码风险评估方面的现有空白,并鼓励对这一新兴领域的进一步研究。
🔬 方法详解
问题定义:论文旨在解决疾病风险评估中传统机器学习方法需要大量编程的问题,这些方法通常难以适应实时交互和个性化需求。现有方法的痛点在于开发周期长、可解释性差,且难以处理流式对话数据。
核心思路:论文的核心思路是利用生成式LLM的强大自然语言处理能力,构建一个基于会话的风险评估系统。通过少量样本的微调,使LLM能够理解并响应用户的问题,从而实现实时的风险评估。这种方法无需编写复杂的代码,降低了开发门槛,并提高了系统的可交互性和可解释性。
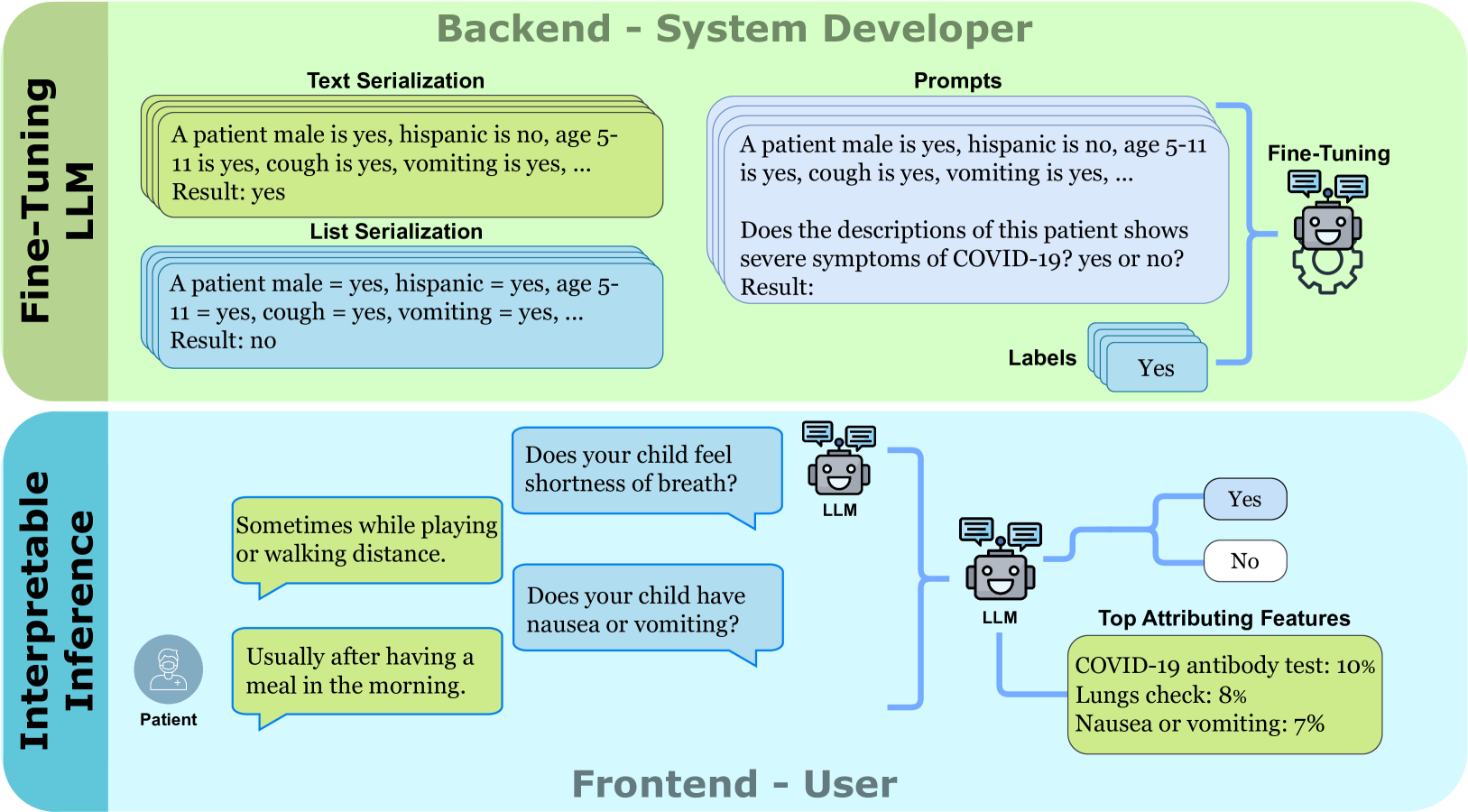
技术框架:该技术框架主要包含以下几个模块:1) 预训练的生成式LLM(如Llama2-7b和Flan-t5-xl);2) 用于微调LLM的少量自然语言示例数据集;3) 一个移动应用程序,作为用户与LLM交互的界面;4) 用于提取特征重要性的LLM注意力层分析模块。整体流程是:用户通过移动应用与LLM进行对话,LLM根据对话内容进行风险评估,并利用注意力层分析提供个性化的特征重要性解释。
关键创新:最重要的技术创新点在于将生成式LLM应用于交互式的无代码风险评估。与传统的判别式分类方法相比,该方法能够直接处理自然语言输入,无需进行特征工程,并且能够提供更具解释性的结果。此外,通过利用LLM的注意力机制,可以分析不同特征对风险评估的影响,从而实现个性化的风险评估。
关键设计:论文的关键设计包括:1) 选择合适的预训练LLM,如Llama2-7b和Flan-t5-xl,这些模型具有强大的生成能力和泛化能力;2) 设计有效的自然语言示例,用于微调LLM,使其能够理解风险评估的相关知识;3) 开发用户友好的移动应用程序界面,方便用户进行交互;4) 利用LLM的注意力层,提取特征重要性,并将其可视化,以便用户理解风险评估的原因。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用少量样本微调后的生成式LLM在COVID-19风险评估中取得了较高的AUC分数,优于传统的Logistic Regression、XGBoost和Random Forest等分类器。这表明生成式LLM在低数据情况下具有更强的泛化能力和适应性,能够有效地应用于实际的风险评估场景。
🎯 应用场景
该研究成果可应用于各种疾病的风险评估,例如心血管疾病、糖尿病等。通过会话式AI,患者可以方便地了解自身风险,医生可以获得更全面的信息,从而制定更个性化的治疗方案。该技术还可用于公共卫生领域,例如疫情预警和防控,具有重要的社会价值和应用前景。
📄 摘要(原文)
Large language models (LLMs) have shown remarkable capabilities in various natural language tasks and are increasingly being applied in healthcare domains. This work demonstrates a new LLM-powered disease risk assessment approach via streaming human-AI conversation, eliminating the need for programming required by traditional machine learning approaches. In a COVID-19 severity risk assessment case study, we fine-tune pre-trained generative LLMs (e.g., Llama2-7b and Flan-t5-xl) using a few shots of natural language examples, comparing their performance with traditional classifiers (i.e., Logistic Regression, XGBoost, Random Forest) that are trained de novo using tabular data across various experimental settings. We develop a mobile application that uses these fine-tuned LLMs as its generative AI (GenAI) core to facilitate real-time interaction between clinicians and patients, providing no-code risk assessment through conversational interfaces. This integration not only allows for the use of streaming Questions and Answers (QA) as inputs but also offers personalized feature importance analysis derived from the LLM's attention layers, enhancing the interpretability of risk assessments. By achieving high Area Under the Curve (AUC) scores with a limited number of fine-tuning samples, our results demonstrate the potential of generative LLMs to outperform discriminative classification methods in low-data regimes, highlighting their real-world adaptability and effectiveness. This work aims to fill the existing gap in leveraging generative LLMs for interactive no-code risk assessment and to encourage further research in this emerging field.