Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely
作者: Siyun Zhao, Yuqing Yang, Zilong Wang, Zhiyuan He, Luna K. Qiu, Lili Qiu
分类: cs.CL, cs.AI
发布日期: 2024-09-23
💡 一句话要点
提出RAG任务分类法,综述增强LLM利用外部数据的技术,助力LLM在专业领域更有效应用。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 RAG 大语言模型 外部数据 任务分类 知识库 数据增强
📋 核心要点
- 现有数据增强LLM方法在专业领域应用受限,无法有效处理复杂任务,缺乏针对不同任务的数据需求分析。
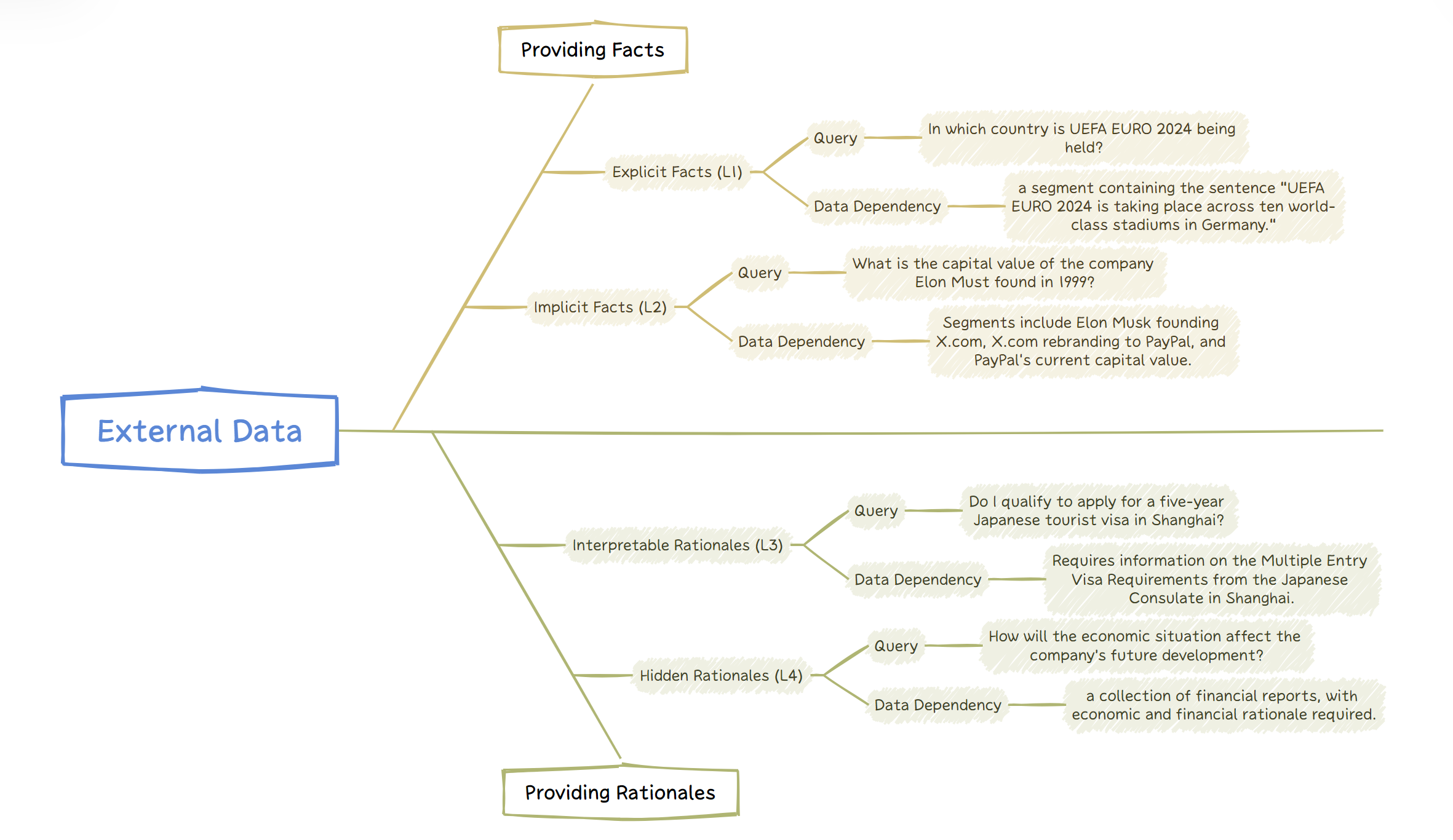
- 论文提出RAG任务分类方法,将查询分为四个级别,并针对每个级别总结了关键挑战和有效技术。
- 论文讨论了上下文、小模型和微调三种数据集成方式,分析了它们的优缺点和适用场景,为LLM应用开发提供指导。
📝 摘要(中文)
本文全面调研了利用外部数据增强的大语言模型(LLM)在完成实际任务中的卓越能力。检索增强生成(RAG)和微调等技术正受到越来越多的关注和广泛应用。然而,在各个专业领域有效部署数据增强的LLM仍然面临巨大挑战,包括检索相关数据、准确理解用户意图以及充分利用LLM的推理能力来完成复杂任务。本文提出了一种RAG任务分类方法,根据所需外部数据的类型和任务的主要关注点,将用户查询分为四个级别:显式事实查询、隐式事实查询、可解释的理由查询和隐藏的理由查询。定义了这些查询级别,提供了相关数据集,并总结了应对这些挑战的关键技术。最后,讨论了将外部数据集成到LLM的三种主要形式:上下文、小模型和微调,突出了它们各自的优势、局限性以及适合解决的问题类型。旨在帮助读者彻底理解和分解构建LLM应用程序中的数据需求和关键瓶颈,为不同的挑战提供解决方案,并作为系统开发此类应用程序的指南。
🔬 方法详解
问题定义:现有的大语言模型在特定领域的应用中,常常需要借助外部数据来增强其知识和能力。然而,如何有效地利用这些外部数据仍然是一个挑战。现有的方法往往无法根据任务的特点选择合适的数据增强策略,导致性能不佳。例如,对于需要复杂推理的任务,简单的事实检索可能无法满足需求。
核心思路:本文的核心思路是根据任务对外部数据的需求进行分类,并针对不同类型的任务推荐合适的解决方案。通过对任务进行细粒度的划分,可以更好地理解任务的本质,从而选择最有效的数据增强方法。这种分类方法有助于解决现有方法在处理复杂任务时遇到的问题。
技术框架:本文提出了一个RAG任务分类框架,将用户查询分为四个级别:显式事实查询、隐式事实查询、可解释的理由查询和隐藏的理由查询。针对每个级别的查询,论文分析了其特点和挑战,并总结了相应的解决方案。此外,论文还讨论了三种主要的数据集成方式:上下文、小模型和微调,并分析了它们的优缺点和适用场景。
关键创新:本文最重要的创新在于提出了RAG任务分类方法。这种分类方法能够帮助研究人员和开发人员更好地理解任务的本质,并选择最有效的数据增强策略。与现有方法相比,本文的方法更加细粒度和具有针对性,能够更好地解决实际应用中遇到的问题。
关键设计:论文的关键设计在于对查询的四个级别的定义,以及对三种数据集成方式的分析。查询级别的定义基于任务对外部数据的需求,而数据集成方式的分析则基于它们的优缺点和适用场景。这些设计为研究人员和开发人员提供了有价值的指导,帮助他们更好地构建数据增强的LLM应用。
🖼️ 关键图片


📊 实验亮点
论文提出了RAG任务分类方法,并针对不同类型的查询总结了关键技术。此外,论文还对三种数据集成方式进行了详细的分析和比较,为研究人员和开发人员提供了有价值的参考。该研究为构建更有效的数据增强LLM应用奠定了基础。
🎯 应用场景
该研究成果可广泛应用于问答系统、知识图谱构建、智能客服等领域。通过对用户查询进行分类,并选择合适的数据增强策略,可以显著提高LLM在特定领域的性能。此外,该研究还可以为LLM的持续学习和知识更新提供指导。
📄 摘要(原文)
Large language models (LLMs) augmented with external data have demonstrated remarkable capabilities in completing real-world tasks. Techniques for integrating external data into LLMs, such as Retrieval-Augmented Generation (RAG) and fine-tuning, are gaining increasing attention and widespread application. Nonetheless, the effective deployment of data-augmented LLMs across various specialized fields presents substantial challenges. These challenges encompass a wide range of issues, from retrieving relevant data and accurately interpreting user intent to fully harnessing the reasoning capabilities of LLMs for complex tasks. We believe that there is no one-size-fits-all solution for data-augmented LLM applications. In practice, underperformance often arises from a failure to correctly identify the core focus of a task or because the task inherently requires a blend of multiple capabilities that must be disentangled for better resolution. In this survey, we propose a RAG task categorization method, classifying user queries into four levels based on the type of external data required and primary focus of the task: explicit fact queries, implicit fact queries, interpretable rationale queries, and hidden rationale queries. We define these levels of queries, provide relevant datasets, and summarize the key challenges and most effective techniques for addressing these challenges. Finally, we discuss three main forms of integrating external data into LLMs: context, small model, and fine-tuning, highlighting their respective strengths, limitations, and the types of problems they are suited to solve. This work aims to help readers thoroughly understand and decompose the data requirements and key bottlenecks in building LLM applications, offering solutions to the different challenges and serving as a guide to systematically developing such applications.