ToolPlanner: A Tool Augmented LLM for Multi Granularity Instructions with Path Planning and Feedback
作者: Qinzhuo Wu, Wei Liu, Jian Luan, Bin Wang
分类: cs.CL, cs.AI
发布日期: 2024-09-23 (更新: 2024-11-04)
💡 一句话要点
ToolPlanner:通过工具增强的LLM,利用多粒度指令、路径规划和反馈机制
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 工具增强LLM 多粒度指令 路径规划 强化学习 人机协作
📋 核心要点
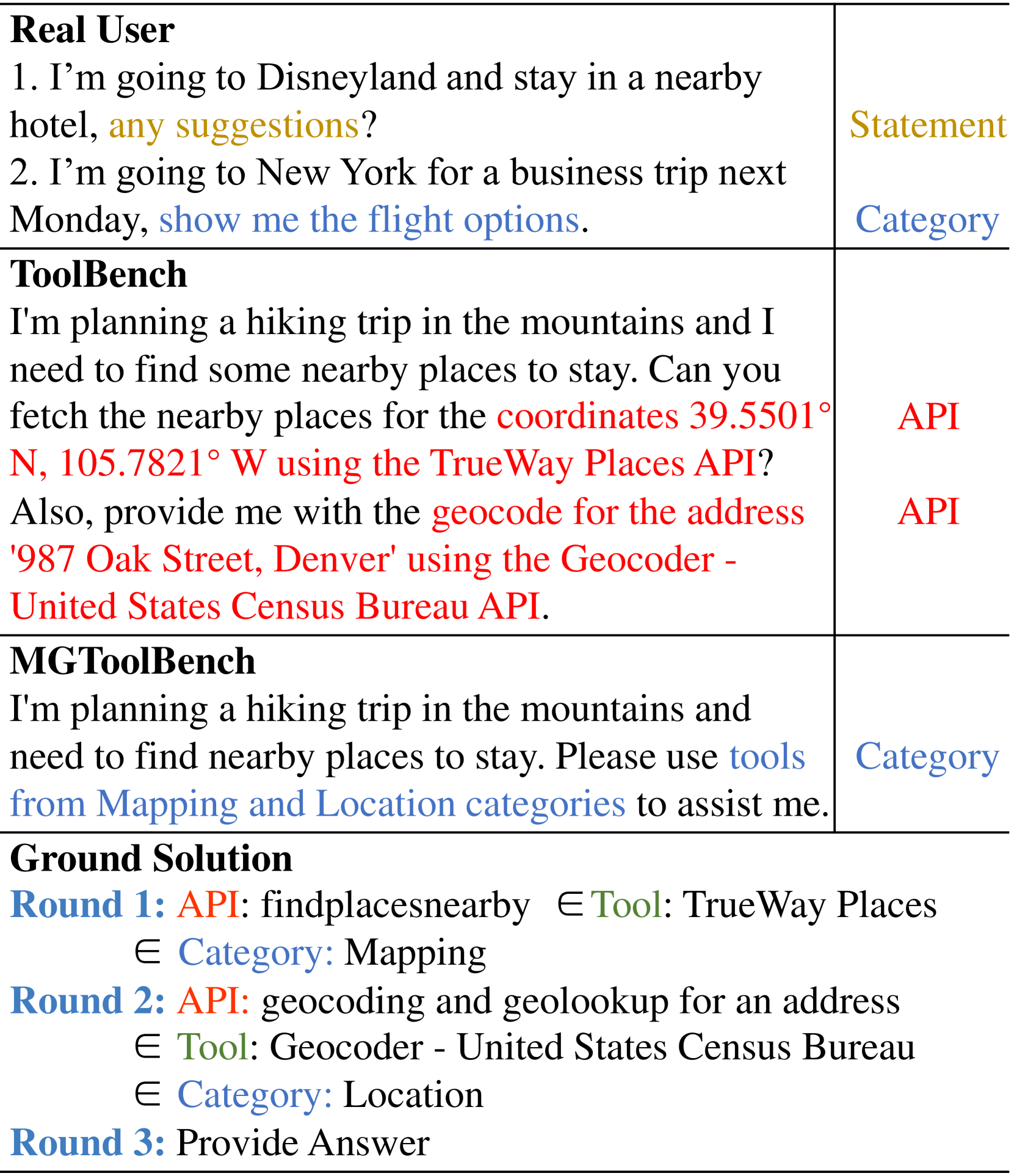
- 现有工具增强的LLM在处理真实用户指令时存在差距,因为它们通常在包含API细节的指令上训练。
- ToolPlanner通过构建包含语句和类别级别指令的MGToolBench数据集,并采用两阶段强化学习框架来解决上述问题。
- 实验结果表明,ToolPlanner在匹配率、通过率和胜率方面显著优于SOTA模型,并且更符合用户习惯。
📝 摘要(中文)
本文提出了一种工具增强的LLM框架,旨在解决现有模型在处理真实用户指令时存在的差距。现有模型通常在过于详细的指令(包含API名称或参数)上训练,而真实用户通常不会明确提及这些API细节。为了解决这个问题,作者构建了一个名为MGToolBench的训练数据集,该数据集包含语句和类别级别的指令,以更好地反映真实场景。此外,作者提出了ToolPlanner,一个两阶段强化学习框架,利用路径规划和两种反馈机制来增强LLM的任务完成和指令遵循能力。实验结果表明,与SOTA模型相比,ToolPlanner在匹配率、通过率和胜率方面分别显著提高了26.8%、20.2%和5.6%。人工评估验证了多粒度指令可以更好地与用户的使用习惯对齐。数据和代码将在接受后发布。
🔬 方法详解
问题定义:现有工具增强的LLM通常在包含API名称和参数等过于详细的指令上进行训练,这与真实用户的使用习惯不符,导致模型在实际应用中表现不佳。此外,现有方法通常忽略交互过程是否遵循指令,导致模型难以完成复杂任务。
核心思路:ToolPlanner的核心思路是构建一个更贴近真实用户指令的数据集(MGToolBench),并利用强化学习框架来训练LLM,使其能够更好地理解和执行多粒度指令。通过路径规划和反馈机制,引导LLM选择合适的工具和参数,最终完成任务。
技术框架:ToolPlanner是一个两阶段的强化学习框架。第一阶段是路径规划阶段,LLM根据指令生成一个工具调用序列(路径)。第二阶段是执行阶段,LLM按照规划的路径与外部工具进行交互,并根据反馈调整其行为。框架包含两个关键的反馈机制:一个是任务完成反馈,用于奖励成功完成任务的LLM;另一个是指令遵循反馈,用于惩罚偏离指令的LLM。
关键创新:ToolPlanner的关键创新在于:1) 提出了多粒度指令的概念,并构建了相应的MGToolBench数据集,更贴近真实用户的使用习惯。2) 引入了路径规划机制,使LLM能够更好地规划工具调用序列。3) 设计了两种反馈机制,分别用于奖励任务完成和惩罚指令偏离,从而提高了LLM的任务完成和指令遵循能力。
关键设计:MGToolBench数据集包含语句级别和类别级别的指令,允许模型学习不同粒度的指令。路径规划阶段使用Transformer模型来预测工具调用序列。强化学习采用策略梯度方法,任务完成反馈基于任务是否成功完成,指令遵循反馈基于LLM的行动是否符合指令的要求。具体损失函数的设计未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ToolPlanner在三个关键指标上显著优于SOTA模型:匹配率提高了26.8%,通过率提高了20.2%,胜率提高了5.6%。这些数据表明,ToolPlanner在任务完成和指令遵循方面都取得了显著的提升。人工评估也验证了多粒度指令可以更好地与用户的使用习惯对齐。
🎯 应用场景
ToolPlanner具有广泛的应用前景,可以应用于智能助手、自动化流程、机器人控制等领域。通过增强LLM的工具使用能力,可以实现更智能、更高效的任务自动化,例如自动预订机票、自动生成报告、自动控制机器人完成复杂任务等。该研究有助于推动人机协作的发展,提高生产效率。
📄 摘要(原文)
Recently, tool-augmented LLMs have gained increasing attention. Given an instruction, tool-augmented LLMs can interact with various external tools in multiple rounds and provide a final answer. However, previous LLMs were trained on overly detailed instructions, which included API names or parameters, while real users would not explicitly mention these API details. This leads to a gap between trained LLMs and real-world scenarios. In addition, most works ignore whether the interaction process follows the instruction. To address these issues, we constructed a training dataset called MGToolBench, which contains statement and category-level instructions to better reflect real-world scenarios. In addition, we propose ToolPlanner, a two-stage reinforcement learning framework that utilizes path planning and two feedback mechanisms to enhance the LLM's task completion and instruction-following capabilities. Experimental results show that ToolPlanner significantly improves the Match Rate, Pass Rate and Win Rate by 26.8%, 20.2%, and 5.6% compared to the SOTA model. Human evaluation verifies that the multi-granularity instructions can better align with users' usage habits. Our data and code will be released upon acceptance.