Do Large Language Models have Problem-Solving Capability under Incomplete Information Scenarios?
作者: Yuyan Chen, Tianhao Yu, Yueze Li, Songzhou Yan, Sijia Liu, Jiaqing Liang, Yanghua Xiao
分类: cs.CL, cs.AI
发布日期: 2024-09-23
备注: Accepted to ACL 2024 (Findings)
💡 一句话要点
提出BrainKing游戏,评估LLM在不完备信息下的问题解决能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不完备信息 问题解决能力 推理能力 决策能力
📋 核心要点
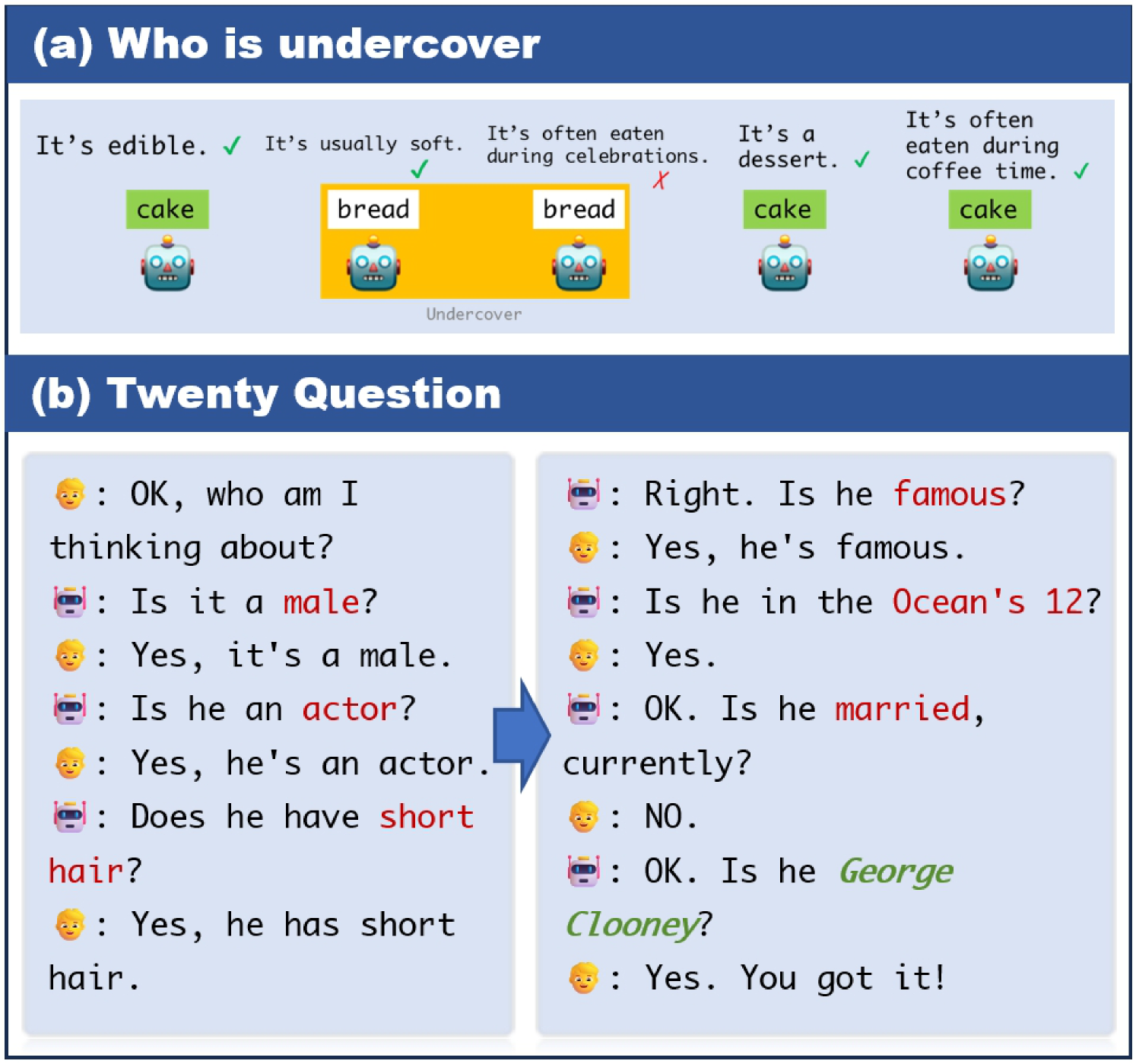
- 现有评估LLM问题解决能力的方法,如“二十问”和“谁是卧底”,存在无法识别误导信息和主观性强的问题。
- 论文提出BrainKing游戏,模拟不完备信息场景,要求LLM通过提问识别目标,并考虑误导性信息。
- 通过设置不同难度,全面评估LLM在BrainKing游戏中的表现,揭示其能力和局限性。
📝 摘要(中文)
本文旨在评估大型语言模型(LLM)在不完备信息场景下的问题解决能力,包括提问、知识搜索、错误检测和路径规划等。现有研究主要集中于LLM的“二十问”等问题解决能力,但这些游戏通常不要求识别误导性线索,而这在不完备信息场景中至关重要。此外,现有的“谁是卧底”等游戏具有高度主观性,难以评估。因此,本文基于“谁是卧底”和“二十问”游戏,提出了一种名为BrainKing的新游戏,用于评估LLM在不完备信息场景下的能力。该游戏要求LLM通过有限的是非问题和潜在的误导性答案来识别目标实体。通过设置简单、中等和困难三种难度模式,全面评估LLM在各个方面的表现。实验结果揭示了LLM在BrainKing中的能力和局限性,为理解LLM的问题解决水平提供了重要见解。
🔬 方法详解
问题定义:论文旨在解决如何有效评估大型语言模型(LLM)在不完备信息场景下的问题解决能力。现有方法,如“二十问”和“谁是卧底”,要么无法模拟真实场景中存在的误导性信息,要么评估过程过于主观,难以进行客观比较和分析。因此,需要一种新的评估方法,能够更全面、客观地衡量LLM在不完备信息下的推理和决策能力。
核心思路:论文的核心思路是设计一个名为BrainKing的游戏,该游戏结合了“谁是卧底”和“二十问”的特点,要求LLM通过有限的提问来识别目标实体,同时需要识别和排除潜在的误导性信息。这种设计模拟了真实世界中信息不完整、存在噪声的场景,能够更有效地评估LLM的推理和决策能力。
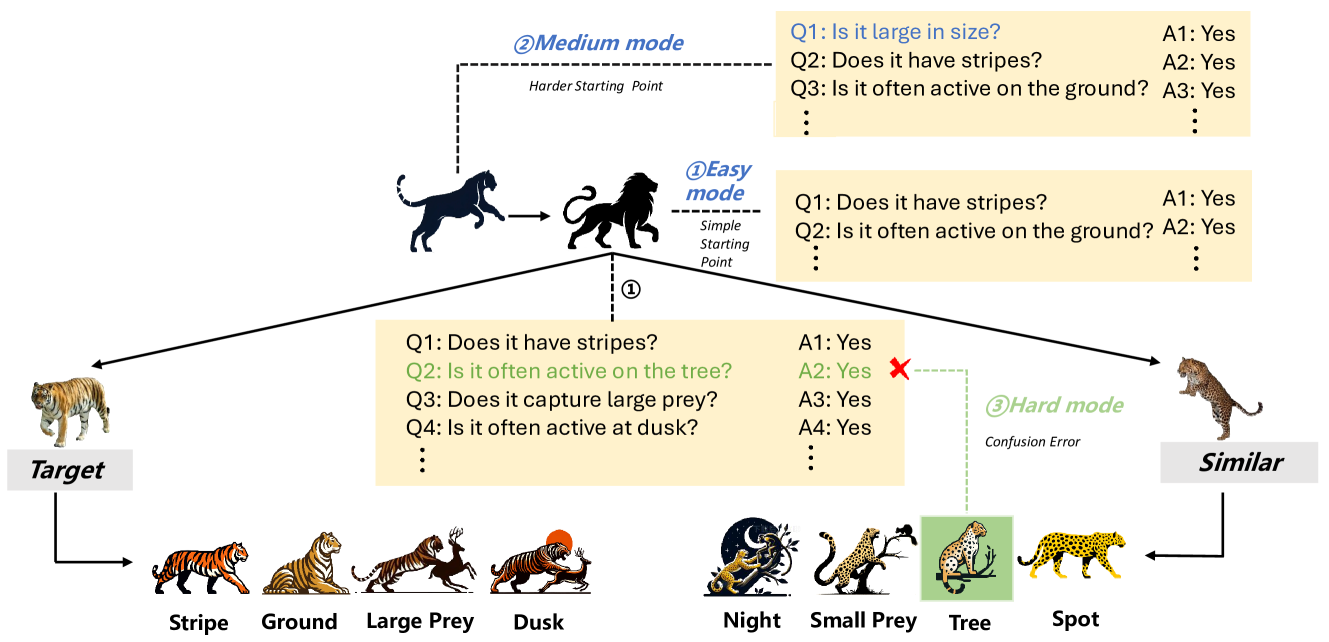
技术框架:BrainKing游戏包含以下几个主要阶段:1) 游戏初始化:确定目标实体和误导性信息;2) LLM提问:LLM根据当前信息提出问题;3) 环境反馈:环境根据目标实体和误导性信息给出回答;4) LLM推理:LLM根据问题和回答更新信念,并决定下一步行动(提问或猜测);5) 游戏结束:LLM成功识别目标实体或提问次数超过限制。整个过程循环进行,直到游戏结束。
关键创新:BrainKing游戏的关键创新在于其能够模拟不完备信息场景,并要求LLM识别和排除误导性信息。与传统的“二十问”游戏相比,BrainKing更贴近真实世界的问题解决场景。此外,BrainKing通过设置不同难度级别,可以更全面地评估LLM在不同复杂程度下的表现。
关键设计:BrainKing的关键设计包括:1) 目标实体和误导性信息的选择:选择具有一定关联性但又存在差异的实体,增加LLM识别的难度;2) 问题类型的限制:限制LLM只能提出是非问题,模拟真实场景中信息获取的限制;3) 难度级别的设置:通过调整目标实体和误导性信息的数量和复杂程度,设置不同的难度级别,以评估LLM在不同复杂程度下的表现。
🖼️ 关键图片
📊 实验亮点
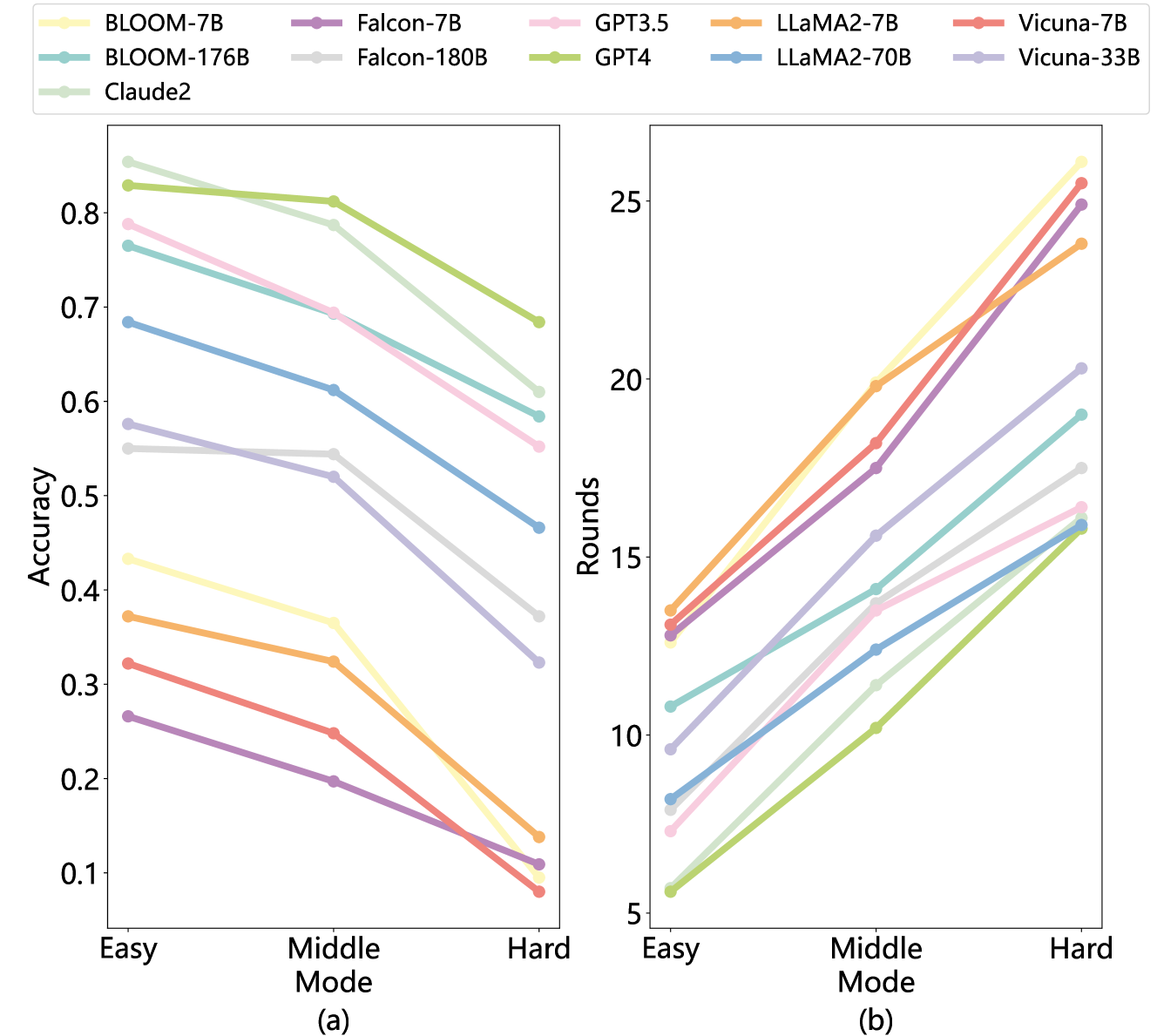
实验结果表明,LLM在BrainKing游戏中表现出一定的推理和决策能力,但在处理复杂和误导性信息时仍存在局限性。通过对比不同难度级别下的表现,可以发现LLM在简单场景下表现良好,但随着难度增加,性能显著下降。这些结果为LLM的改进提供了重要的参考依据。
🎯 应用场景
该研究成果可应用于评估和提升LLM在信息检索、智能问答、决策支持等领域的应用能力。通过BrainKing游戏,可以更全面地了解LLM在处理不完备信息时的优势和不足,从而指导LLM的改进和优化,使其在实际应用中能够更好地应对复杂和不确定的环境。
📄 摘要(原文)
The evaluation of the problem-solving capability under incomplete information scenarios of Large Language Models (LLMs) is increasingly important, encompassing capabilities such as questioning, knowledge search, error detection, and path planning. Current research mainly focus on LLMs' problem-solving capability such as
Twenty Questions''. However, these kinds of games do not require recognizing misleading cues which are necessary in the incomplete information scenario. Moreover, the existing game such asWho is undercover'' are highly subjective, making it challenging for evaluation. Therefore, in this paper, we introduce a novel game named BrainKing based on theWho is undercover'' andTwenty Questions'' for evaluating LLM capabilities under incomplete information scenarios. It requires LLMs to identify target entities with limited yes-or-no questions and potential misleading answers. By setting up easy, medium, and hard difficulty modes, we comprehensively assess the performance of LLMs across various aspects. Our results reveal the capabilities and limitations of LLMs in BrainKing, providing significant insights of LLM problem-solving levels.