Repairs in a Block World: A New Benchmark for Handling User Corrections with Multi-Modal Language Models
作者: Javier Chiyah-Garcia, Alessandro Suglia, Arash Eshghi
分类: cs.CL, cs.HC
发布日期: 2024-09-21 (更新: 2024-10-04)
备注: Accepted to EMNLP'24 Main (Upcoming). Data and code at www.github.com/JChiyah/blockworld-repairs - for Bibtex see https://raw.githubusercontent.com/JChiyah/blockworld-repairs/refs/heads/main/citation.bib
💡 一句话要点
提出BlockWorld-Repairs数据集,评估多模态语言模型处理用户纠错能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态对话 用户纠错 视觉语言模型 数据集构建 指令跟随
📋 核心要点
- 现有对话AI系统在处理用户纠错(Third Position Repair, TPR)方面存在不足,尤其是在多模态环境中。
- 论文核心在于构建一个包含多模态TPR序列的数据集,并利用该数据集评估现有视觉语言模型(VLM)的纠错能力。
- 实验表明,现有VLM在处理TPR任务时性能远低于人类,但通过针对性损失函数微调可以提升性能和泛化能力。
📝 摘要(中文)
在对话中,听者可能会误解说话者,并做出错误的响应,通常导致说话者在下一轮对话中使用第三位置修复(TPR)来纠正这种误解。处理并适当响应此类修复序列的能力对于会话AI系统至关重要。本文首先收集、分析并公开发布了BlockWorld-Repairs:一个多模态TPR序列数据集,该数据集在一个指令跟随操作任务中,在设计上充满了指代歧义。我们使用该数据集来评估多个最先进的视觉和语言模型(VLM)在多个设置下的性能,重点关注它们处理和准确响应TPR并因此从沟通错误中恢复的能力。我们发现,与人类相比,所有模型在这项任务中的表现都明显不佳。然后,我们表明,VLM可以从微调期间针对相关token的专门损失中受益,从而获得更好的性能并更好地泛化到新的场景。我们的结果表明,这些模型尚未准备好部署在修复很常见的多模态协作环境中,并强调需要设计训练方案和目标,以促进从交互中学习。我们的代码和数据可在www.github.com/JChiyah/blockworld-repairs上找到。
🔬 方法详解
问题定义:论文旨在解决多模态对话中,视觉语言模型(VLM)难以有效处理用户纠错(TPR)的问题。现有VLM在处理包含指代歧义的指令跟随任务时,容易产生误解,并且缺乏从用户反馈中学习并纠正错误的能力。这限制了它们在真实多模态协作环境中的应用。
核心思路:论文的核心思路是构建一个专门用于评估和提升VLM处理TPR能力的数据集BlockWorld-Repairs。通过分析模型在处理该数据集时的表现,并设计针对性的训练方法,提高VLM从用户纠错中学习的能力,从而改善其在多模态对话中的表现。
技术框架:整体框架包括数据收集、模型评估和模型微调三个主要阶段。首先,收集包含多模态TPR序列的BlockWorld-Repairs数据集。然后,使用该数据集评估现有VLM在不同设置下的性能,重点关注其处理TPR的能力。最后,设计专门的损失函数,对VLM进行微调,以提高其纠错能力和泛化能力。
关键创新:论文的关键创新在于构建了BlockWorld-Repairs数据集,该数据集专门用于评估和提升VLM处理多模态TPR的能力。该数据集的设计考虑了指代歧义,使得模型更容易产生误解,从而更好地模拟了真实对话场景。此外,论文还提出了针对性的损失函数,用于微调VLM,以提高其纠错能力。
关键设计:论文的关键设计包括:1) BlockWorld-Repairs数据集的构建,该数据集包含多模态TPR序列,并具有较高的指代歧义;2) 针对性损失函数的设计,该损失函数旨在优化模型对TPR中关键token的识别和理解;3) 实验设置,包括不同的VLM模型和评估指标,用于全面评估模型的纠错能力。
🖼️ 关键图片

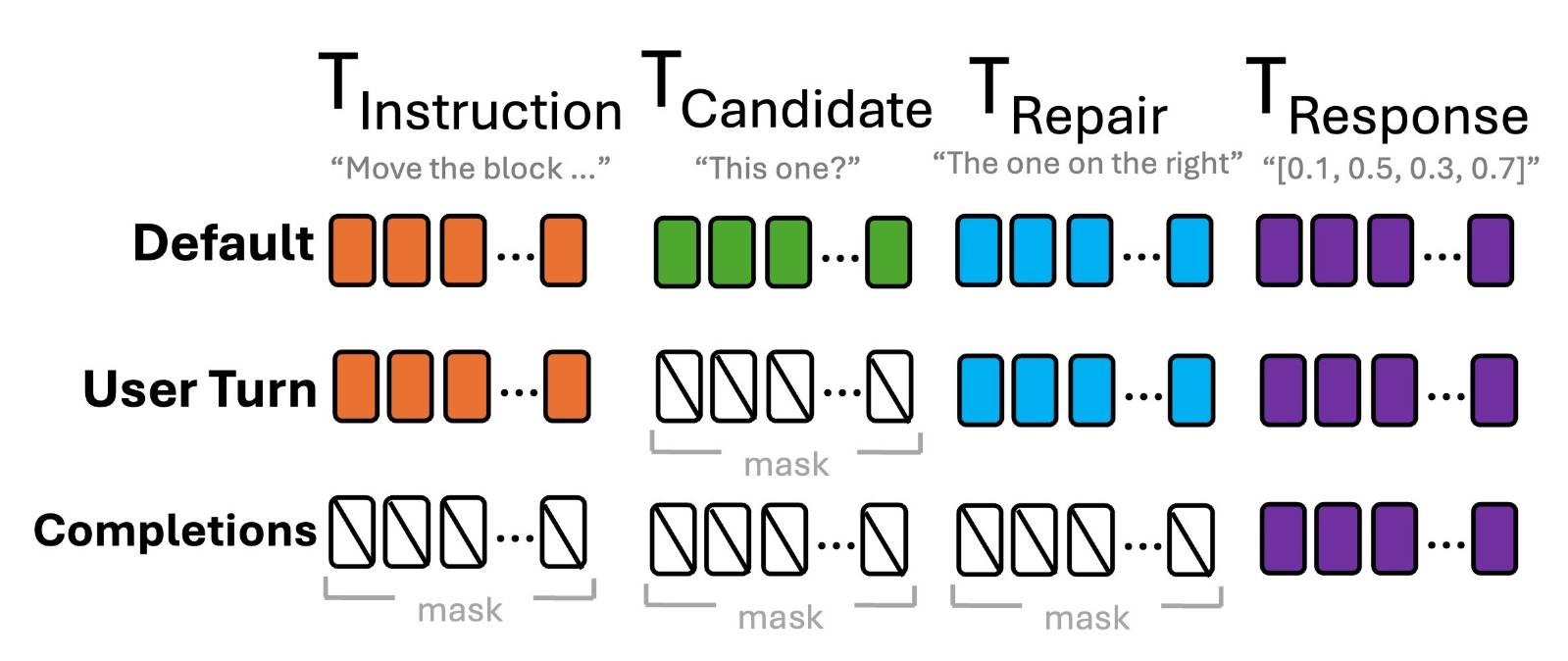

📊 实验亮点
实验结果表明,现有VLM在BlockWorld-Repairs数据集上的表现远低于人类水平,表明其在处理多模态TPR方面存在显著不足。然而,通过使用针对性损失函数进行微调,VLM的性能得到了显著提升,并且在新的场景中表现出更好的泛化能力。具体提升幅度未知,但结果表明微调策略有效。
🎯 应用场景
该研究成果可应用于人机协作机器人、智能家居助手、以及其他需要多模态交互的智能系统中。通过提升模型处理用户纠错的能力,可以提高人机交互的自然性和效率,减少用户操作的复杂性,从而提升用户体验。未来,该研究可以进一步扩展到更复杂的任务和场景中,例如自动驾驶、医疗诊断等。
📄 摘要(原文)
In dialogue, the addressee may initially misunderstand the speaker and respond erroneously, often prompting the speaker to correct the misunderstanding in the next turn with a Third Position Repair (TPR). The ability to process and respond appropriately to such repair sequences is thus crucial in conversational AI systems. In this paper, we first collect, analyse, and publicly release BlockWorld-Repairs: a dataset of multi-modal TPR sequences in an instruction-following manipulation task that is, by design, rife with referential ambiguity. We employ this dataset to evaluate several state-of-the-art Vision and Language Models (VLM) across multiple settings, focusing on their capability to process and accurately respond to TPRs and thus recover from miscommunication. We find that, compared to humans, all models significantly underperform in this task. We then show that VLMs can benefit from specialised losses targeting relevant tokens during fine-tuning, achieving better performance and generalising better to new scenarios. Our results suggest that these models are not yet ready to be deployed in multi-modal collaborative settings where repairs are common, and highlight the need to design training regimes and objectives that facilitate learning from interaction. Our code and data are available at www.github.com/JChiyah/blockworld-repairs