The Imperative of Conversation Analysis in the Era of LLMs: A Survey of Tasks, Techniques, and Trends
作者: Xinghua Zhang, Haiyang Yu, Yongbin Li, Minzheng Wang, Longze Chen, Fei Huang
分类: cs.CL
发布日期: 2024-09-21
备注: 21 pages, work in progress
💡 一句话要点
综述性论文:在LLM时代,系统化会话分析任务,弥合研究与商业应用间的差距。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 会话分析 大语言模型 任务定义 归因分析 对话生成 商业应用 综述
📋 核心要点
- 现有会话分析技术分散,缺乏明确的任务范围和系统性,难以有效赋能商业应用。
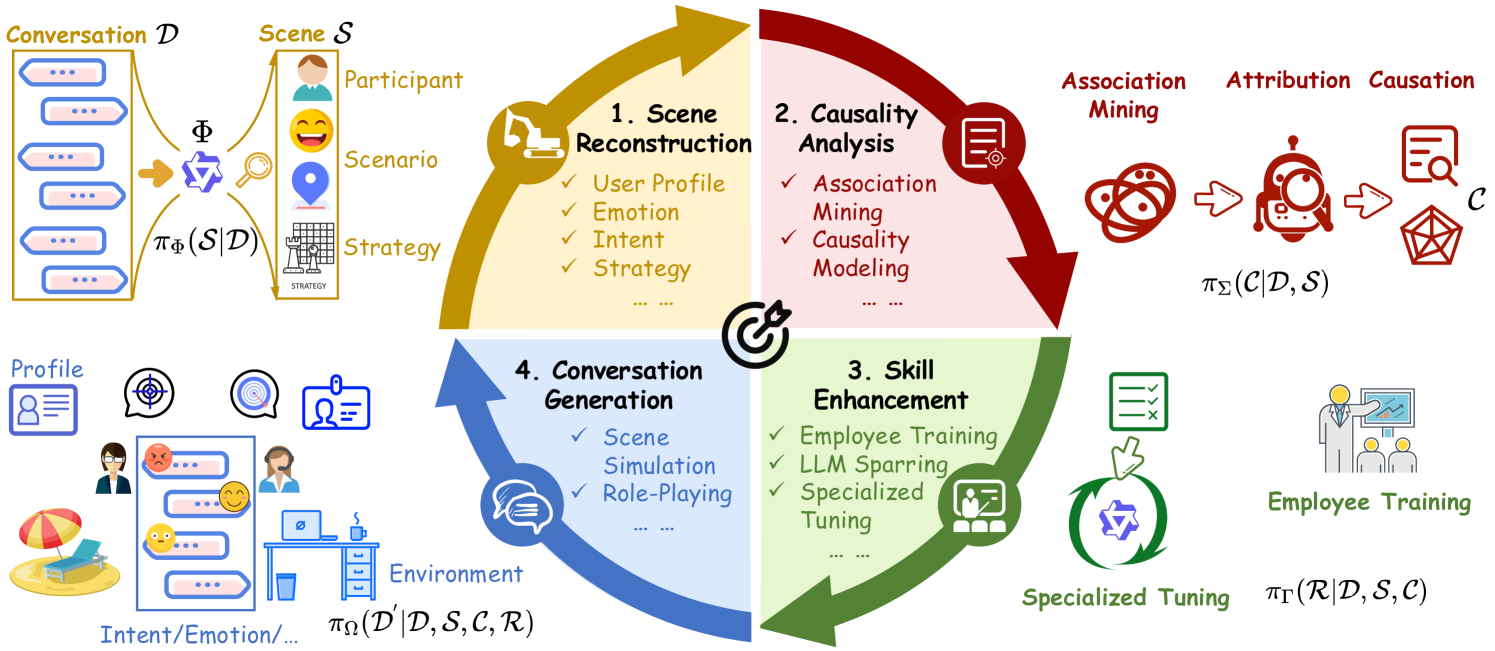
- 论文正式定义会话分析任务,并提出包含场景重建、归因分析、针对性训练和对话生成的四步框架。
- 论文分析了现有技术的局限性,指出了未来研究方向,尤其是在因果关系和战略任务等高层次分析方面。
📝 摘要(中文)
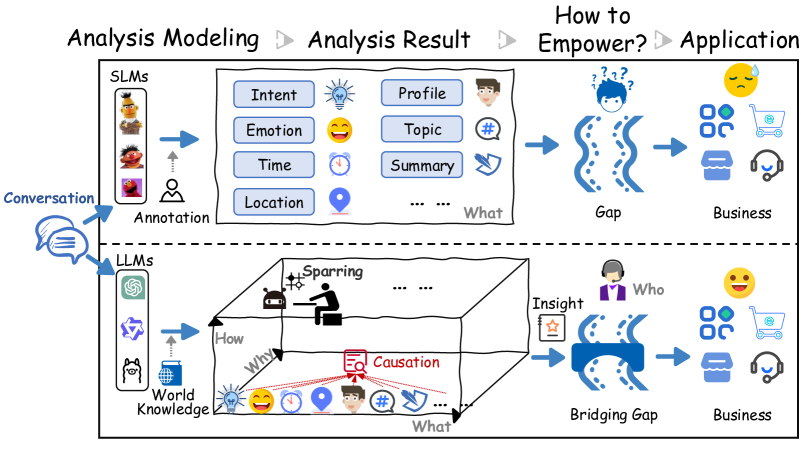
在大语言模型(LLM)时代,由于语言用户界面(UI)的快速发展趋势,将会积累大量的会话日志。会话分析(CA)致力于从会话数据中发现和分析关键信息,从而简化手动流程,并支持商业洞察和决策。提取可操作的见解并推动赋能的需求日益突出,并引起了广泛关注。然而,由于缺乏明确的CA范围,导致各种技术分散,难以形成系统的技术协同作用来增强商业应用。在本文中,我们对CA任务进行了全面的回顾和系统化,以总结现有的相关工作。具体来说,我们正式定义了CA任务,以应对该领域碎片化和混乱的局面,并从会话场景重建、到深入的归因分析、再到执行有针对性的训练,最后生成基于有针对性的训练的对话以实现特定目标,推导出CA的四个关键步骤。此外,我们展示了相关的基准,讨论了潜在的挑战,并指出了行业和学术界的未来方向。鉴于目前的进展,很明显,大多数努力仍然集中在对浅层会话元素的分析上,这在研究和商业之间存在相当大的差距,并且在LLM的帮助下,最近的工作已经显示出研究因果关系和战略任务的趋势,这些任务是复杂和高层次的。所分析的经验和见解将不可避免地在针对会话日志的业务运营中具有更广泛的应用价值。
🔬 方法详解
问题定义:论文旨在解决会话分析领域任务定义不清晰、技术分散的问题。现有方法主要集中在浅层会话元素分析,无法满足商业应用中对深层洞察(如因果关系、战略意图)的需求。缺乏统一的框架和标准,导致研究与实际应用脱节。
核心思路:论文的核心思路是将会话分析任务进行系统化梳理,并定义为一个包含四个关键步骤的流程。通过明确任务范围和步骤,旨在为会话分析研究提供一个统一的框架,并促进更高级别分析技术的发展,从而更好地服务于商业应用。
技术框架:论文提出的会话分析框架包含以下四个主要步骤: 1. 会话场景重建:理解会话发生的背景和参与者信息。 2. 深入的归因分析:分析会话中事件的原因和影响,例如用户行为背后的动机。 3. 针对性训练:基于归因分析的结果,对模型进行训练,使其能够理解和生成特定类型的会话。 4. 对话生成:利用训练好的模型生成符合特定目标的对话。
关键创新:论文的关键创新在于对会话分析任务的系统化定义和框架构建。它将原本分散的会话分析技术整合到一个统一的流程中,并强调了高层次分析(如因果关系和战略意图)的重要性。这种系统化的方法有助于弥合研究与商业应用之间的差距。
关键设计:论文主要关注会话分析任务的定义和框架构建,并未涉及具体的参数设置、损失函数或网络结构等技术细节。未来的研究可以基于此框架,探索更有效的模型和算法,以提升各个步骤的性能。
🖼️ 关键图片

📊 实验亮点
论文对现有会话分析技术进行了全面的回顾和总结,并提出了一个系统化的任务框架。论文强调了高层次分析(如因果关系和战略意图)的重要性,并指出了未来研究方向。这些分析和见解对于推动会话分析技术的发展和应用具有重要价值。
🎯 应用场景
该研究成果可应用于智能客服、销售对话分析、用户行为分析等领域。通过深入分析会话数据,企业可以更好地理解用户需求、优化服务流程、提升销售效率。未来,随着LLM技术的不断发展,会话分析将在商业决策中发挥更重要的作用。
📄 摘要(原文)
In the era of large language models (LLMs), a vast amount of conversation logs will be accumulated thanks to the rapid development trend of language UI. Conversation Analysis (CA) strives to uncover and analyze critical information from conversation data, streamlining manual processes and supporting business insights and decision-making. The need for CA to extract actionable insights and drive empowerment is becoming increasingly prominent and attracting widespread attention. However, the lack of a clear scope for CA leads to a dispersion of various techniques, making it difficult to form a systematic technical synergy to empower business applications. In this paper, we perform a thorough review and systematize CA task to summarize the existing related work. Specifically, we formally define CA task to confront the fragmented and chaotic landscape in this field, and derive four key steps of CA from conversation scene reconstruction, to in-depth attribution analysis, and then to performing targeted training, finally generating conversations based on the targeted training for achieving the specific goals. In addition, we showcase the relevant benchmarks, discuss potential challenges and point out future directions in both industry and academia. In view of current advancements, it is evident that the majority of efforts are still concentrated on the analysis of shallow conversation elements, which presents a considerable gap between the research and business, and with the assist of LLMs, recent work has shown a trend towards research on causality and strategic tasks which are sophisticated and high-level. The analyzed experiences and insights will inevitably have broader application value in business operations that target conversation logs.