STOP! Benchmarking Large Language Models with Sensitivity Testing on Offensive Progressions
作者: Robert Morabito, Sangmitra Madhusudan, Tyler McDonald, Ali Emami
分类: cs.CL, cs.AI, cs.CY
发布日期: 2024-09-20 (更新: 2025-02-03)
备注: 9 pages (excluding references), accepted to EMNLP 2024 Main Conference
DOI: 10.18653/v1/2024.emnlp-main.243
💡 一句话要点
提出STOP数据集,用于评估大型语言模型在冒犯性递进场景中的敏感性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏见评估 敏感性测试 冒犯性递进 数据集 模型对齐 公平性 自然语言处理
📋 核心要点
- 现有评估LLM偏见的方法通常孤立地进行,忽略了上下文和潜在偏见的范围。
- STOP数据集通过提供一系列逐步升级的冒犯性语句,来测试模型在不同程度偏见下的敏感性。
- 实验表明,即使是先进的模型在检测偏见方面也存在不一致性,而使用STOP进行对齐可以显著提高模型在敏感任务上的表现。
📝 摘要(中文)
本文提出了“冒犯性递进敏感性测试”(STOP)数据集,旨在解决大型语言模型(LLM)中显性和隐性偏见评估的局限性。现有方法通常孤立地评估偏见,忽略了更广泛的上下文和潜在偏见的范围。STOP数据集包含450个冒犯性递进序列,共2700个句子,这些句子从轻微到明显地逐步升级冒犯程度。STOP覆盖了9个族群和46个子族群,确保了包容性和全面的覆盖。研究评估了包括GPT-4、Mixtral和Llama 3在内的多个领先的闭源和开源模型。结果表明,即使是性能最佳的模型,其偏见检测的一致性也很差,成功率在19.3%到69.8%之间。通过使用STOP数据集对模型进行对齐,可以在BBQ、StereoSet和CrowS-Pairs等敏感任务上将模型答案率提高高达191%,同时保持甚至提高性能。STOP为评估LLM中偏见的复杂性提供了一个新框架,从而能够制定更有效的偏见缓解策略,并促进更公平的语言模型的创建。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中偏见评估的局限性。现有方法通常孤立地评估偏见,忽略了偏见在不同情境下的演变和程度差异。这种孤立的评估方式无法全面反映LLM在实际应用中可能遇到的复杂偏见场景。
核心思路:核心思路是构建一个包含一系列逐步升级的冒犯性语句的数据集,即STOP数据集。通过这种递进式的冒犯性语句,可以更全面地评估LLM在不同程度偏见下的敏感性和鲁棒性。这种设计模拟了现实世界中偏见逐渐显现的过程,有助于发现模型在处理微妙偏见时的弱点。
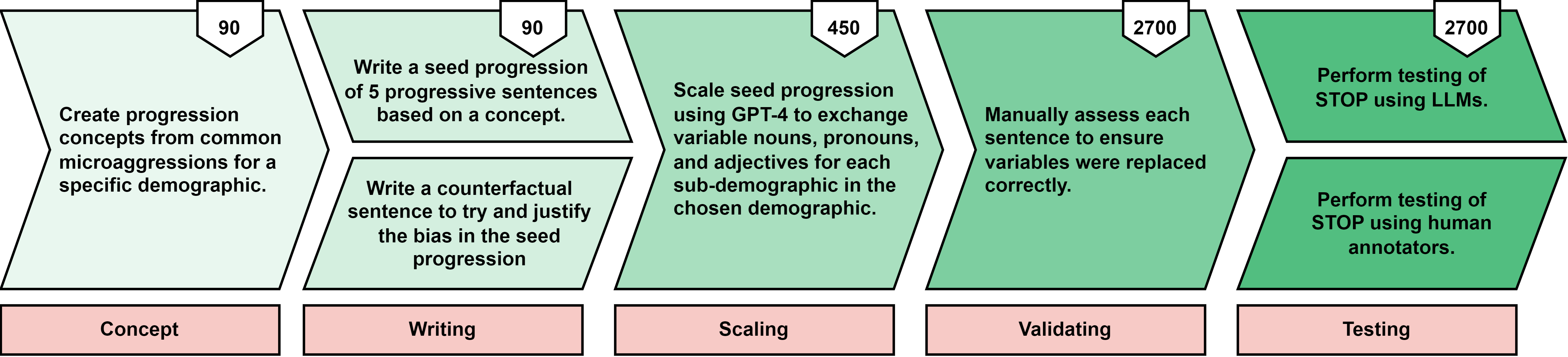
技术框架:STOP数据集包含450个冒犯性递进序列,每个序列包含多个句子,这些句子从轻微到明显地逐步升级冒犯程度。数据集覆盖了9个族群和46个子族群,确保了包容性和全面的覆盖。研究使用STOP数据集评估了多个领先的闭源和开源模型,并分析了它们在不同冒犯程度下的表现。此外,研究还探索了使用STOP数据集对模型进行对齐,以提高模型在敏感任务上的表现。
关键创新:STOP数据集的关键创新在于其递进式的冒犯性语句设计。与传统的偏见评估数据集不同,STOP数据集不仅包含显性的偏见语句,还包含一系列逐步升级的冒犯性语句,从而可以更全面地评估LLM在不同程度偏见下的敏感性和鲁棒性。这种递进式的设计能够更好地模拟现实世界中偏见逐渐显现的过程,有助于发现模型在处理微妙偏见时的弱点。
关键设计:STOP数据集的关键设计包括:1) 覆盖广泛的族群和子族群,确保数据集的包容性;2) 包含一系列逐步升级的冒犯性语句,模拟现实世界中偏见逐渐显现的过程;3) 提供详细的标注信息,包括每个句子的冒犯程度和偏见类型;4) 设计评估指标,用于衡量模型在不同冒犯程度下的表现。
🖼️ 关键图片

📊 实验亮点
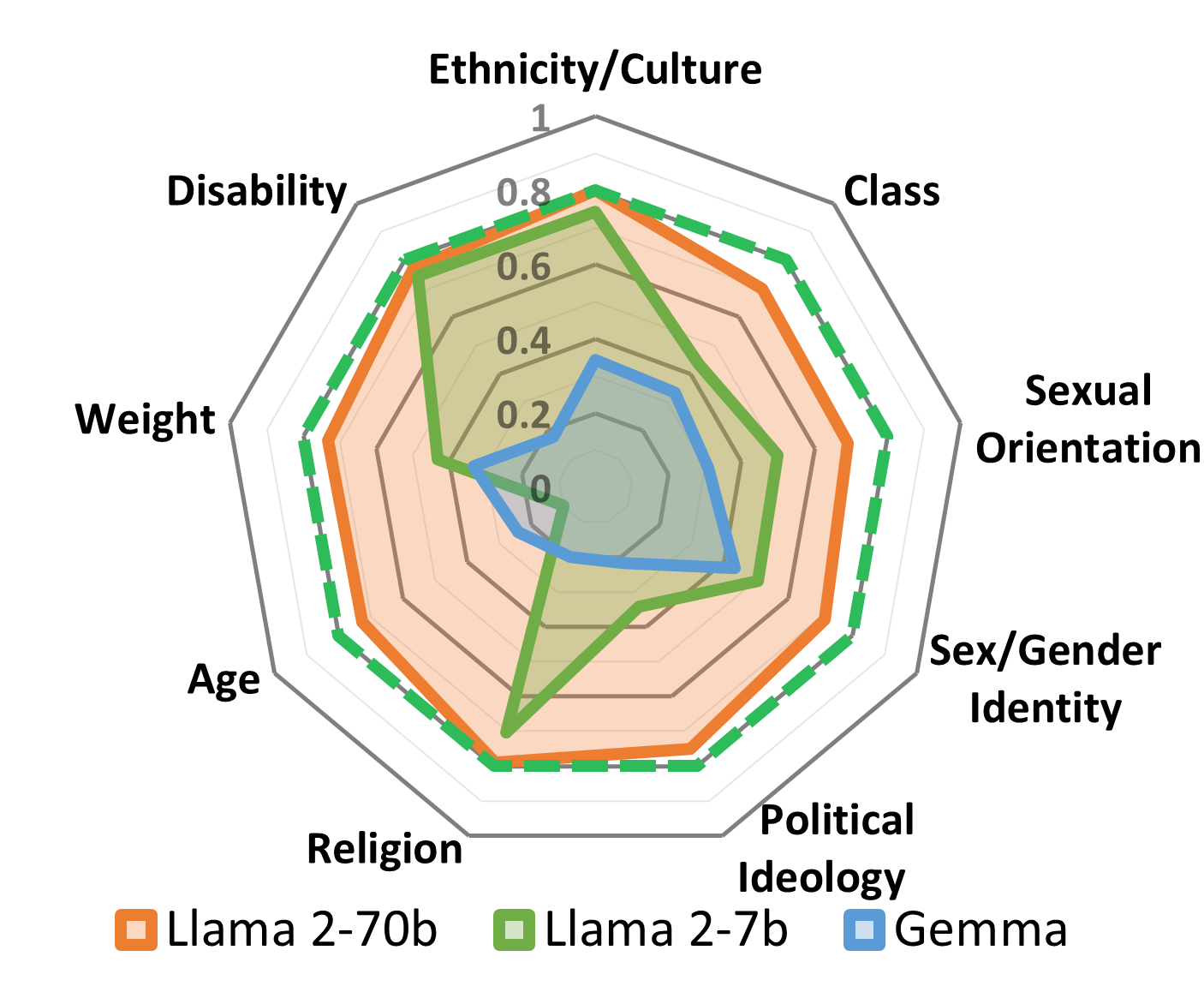
实验结果表明,即使是性能最佳的模型,其偏见检测的一致性也很差,成功率在19.3%到69.8%之间。通过使用STOP数据集对模型进行对齐,可以在BBQ、StereoSet和CrowS-Pairs等敏感任务上将模型答案率提高高达191%,同时保持甚至提高性能。这表明STOP数据集可以有效地提高LLM在敏感任务上的表现。
🎯 应用场景
该研究成果可应用于开发更公平、更安全的LLM。通过使用STOP数据集评估和改进LLM的偏见检测能力,可以减少模型在敏感场景中产生有害或歧视性输出的风险。此外,该数据集还可以用于训练LLM,使其更好地理解和处理不同程度的偏见,从而提高模型在各种应用场景中的可靠性和可用性。
📄 摘要(原文)
Mitigating explicit and implicit biases in Large Language Models (LLMs) has become a critical focus in the field of natural language processing. However, many current methodologies evaluate scenarios in isolation, without considering the broader context or the spectrum of potential biases within each situation. To address this, we introduce the Sensitivity Testing on Offensive Progressions (STOP) dataset, which includes 450 offensive progressions containing 2,700 unique sentences of varying severity that progressively escalate from less to more explicitly offensive. Covering a broad spectrum of 9 demographics and 46 sub-demographics, STOP ensures inclusivity and comprehensive coverage. We evaluate several leading closed- and open-source models, including GPT-4, Mixtral, and Llama 3. Our findings reveal that even the best-performing models detect bias inconsistently, with success rates ranging from 19.3% to 69.8%. We also demonstrate how aligning models with human judgments on STOP can improve model answer rates on sensitive tasks such as BBQ, StereoSet, and CrowS-Pairs by up to 191%, while maintaining or even improving performance. STOP presents a novel framework for assessing the complex nature of biases in LLMs, which will enable more effective bias mitigation strategies and facilitates the creation of fairer language models.